就像在软件工程中将复杂系统分解为一组模块化组件一样,在提交给GPT模型的任务中也是如此。复杂任务往往比简单任务出错率更高。此外,复杂任务通常可以重新定义为一系列简单任务的工作流程,其中前置任务的输出作为后续任务的输入。
在《GPT最佳实践 - 提升Prompt效果的六个策略》中,我们介绍了OpenAI官方发布的"GPT 最佳实践"指南的六个策略,其中第三个策略是“将复杂的任务拆分为更简单的子任务”。
就像在软件工程中将复杂系统分解为一组模块化组件一样,在提交给GPT模型的任务中也是如此。复杂任务往往比简单任务出错率更高。此外,复杂任务通常可以重新定义为一系列简单任务的工作流程,其中前置任务的输出作为后续任务的输入。
具体方法:
· 使用意图分类来识别与用户查询最相关的指令
· 对于需要很长会话的对话应用,总结或过滤之前的对话
· 分段总结长文档,并递归构建成完整摘要
使用意图分类来识别与用户查询最相关的指令
对于需要大量独立指令集来处理不同情况的任务,首先对查询类型进行分类并使用该分类来确定需要哪些指令可能会更好。这可以通过定义与处理给定类别中的任务相关的固定类别和硬编码指令来实现。该过程也可以递归地应用,将任务分解为一系列阶段。这种方法的优点是每个查询仅包含执行任务下一阶段所需的指令,与使用单个查询执行整个任务相比,这可以降低错误率。这还可以降低成本,因为更多的提示(large prompts)运行成本也会更高。(这段描述比较抽象,结合下面的例子来理解会清楚很多)
示例1
例如,对于一个客户服务查询系统,可以按照以下方式进行更好的查询分类。
SYSTEM Prompt:


我们提几个问题,进行客户服务查询:
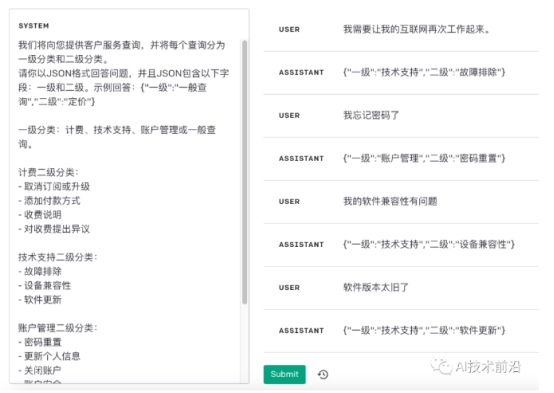
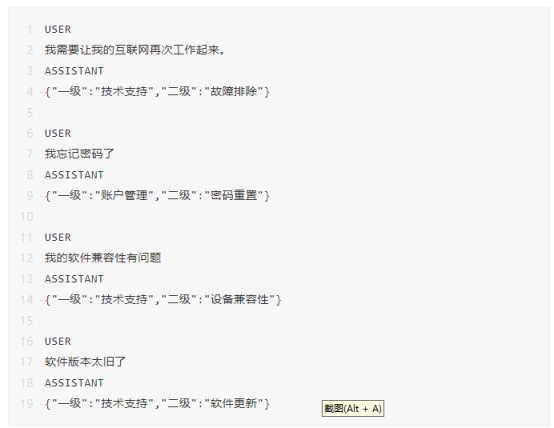
针对我们提出的4个问题,GPT对意图的识别都是正确的,效果很棒。
这种实现思路,非常适合用来实现智能客服,以及指令类型的应用系统。
示例2
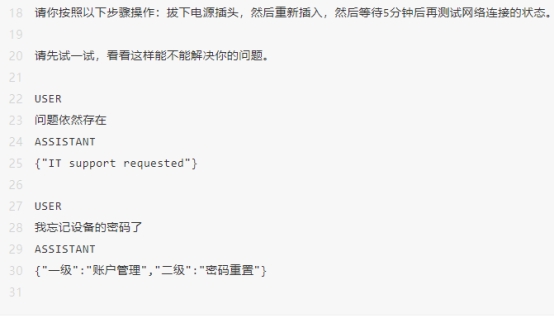
根据客户查询的分类,可以向 GPT 模型提供一组更具体的指令来处理后续的步骤。例如,假设客户需要“故障排除”方面的帮助。
SYSTEM Prompt:


相比于第一个例子,本示例的Prompt要复杂许多,换做是人工都不一定能回答得很好,但是GPT的回复却非常的到位。


对于需要很长会话的对话应用,总结或过滤之前的对话
由于 GPT 具有固定的上下文长度,因此用户和GPT之间的历史对话内容不能无限期地包含在上下文窗口中。
对于这个问题有多种解决方法,其中一种是对之前的对话进行总结。当输入内容的大小达到预定的阈值长度时,则触发对部分对话内容的总结,同时总结后的会话摘要可以作为系统提示信息的一部分。或者,可以在整个对话的过程中,在后台异步的总结之前的对话。
另一种解决方案,是动态的选择先前会话中与当前查询最相关的对话内容。这部分请参阅策略“使用基于嵌入的搜索实现高效的知识检索”。
举一个简单的例子:

分段总结长文档,并递归构建成完整摘要
由于 GPT 具有固定的上下文长度,因此它不能用于在单次查询中总结长度超过“固定上下文长度减去生成内容的长度”的文本。
要总结一个很长的文档(例如一本书),我们可以使用一系列的查询来总结文档的每个部分。通过将每一个章节的摘要合并在一起并进行总结,可以进一步生成摘要的摘要。这个处理过程可以递归地进行,直到对整个文档完成总结。如果有必要使用前面章节的信息来理解后面的章节,那么另一个有用的技巧是,在总结书中任何给定部分的内容时,都将前面章节得到的摘要(a running summary,持续摘要)包含进来。OpenAI 在之前的研究中,已经使用了 GPT-3 的变体研究了这种总结书籍的过程的有效性。
举一个简单的例子:

通过这种持续摘要的方式,提供了一个连续的、不断更新的上下文信息,当后续的章节与前面的章节有紧密的联系时,可以更好的理解最新的章节。
参考
https://platform.openai.com/docs/guides/gpt-best-practices/strategy-split-complex-tasks-into-simpler-subtasks
出自:https://mp.weixin.qq.com/s/o6iM59TfD2kf_Z8MSRibzw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip