从语言理解到任务执行
之前大多相关项目和产品都主要利用了 GPT 模型的语言理解方面的能力,例如生成文案的 Jasper,Notion AI,帮忙做网页、文档总结的 Glarity,Bearly.ai,做问答的 New Bing,ChatPDF 等。后续想要拓展 GPT 的应用范围,一个很自然的方向就是让 GPT 能够学会自己使用各种外部工具,来进行更广泛的任务类型的执行,做到“知行合一”
。除了上面提到的 AutoGPT 和 BabyAGI,还有很多有意思的项目如 Toolformer,HuggingGPT,Visual ChatGPT 等都在尝试这个方向。
这个任务执行说起来原理也不复杂,基本的套路还是让 GPT 去做生成,只不过我们会在 Prompt 中告诉 GPT,如果你需要调用一些外部工具,那么就按照特定的格式来生成一些指令/代码,程序接收到之后,再根据 GPT 生成的内容去调用外部工具并获得相应结果,这个结果再作为输入可以由 GPT 去做进一步的理解和生成,循环往复。以 LangChain 里最常见的 ReAct prompt 为例,输入给模型的内容如下:
...
你可以使用如下工具来完成任务:
1. 计算器,用来执行各种数学计算获取精确结果,输入表达式,例如 1 + 1,得到结果
...
问题:123 乘以 456 的结果是多少?
...
模型生成的内容如下:
思考:我需要使用计算器来计算 123 乘以 456 的结果
动作:调用计算器
动作输入:123 * 456
观测结果:
然后我们可以处理这段返回,调用计算器程序,拿到 123 * 456 的结果,然后将结果填写到观测结果后面,再让模型继续生成下一段内容。
这就是基本的任务执行的方法。更多内容也可以参考我之前对于 LangChain 的一些分享:微软
365 Copilot 是如何实现的?揭秘 LLM 如何生成指令。

典型的 ReAct prompt
模型记忆
另外一类非常常见的模式是通过外部存储来增强模型记忆。其中一个典型场景是长 session
的聊天过程,由于 GPT API 本身的输入信息有 4000 个 token 的限制,所以当聊天进行比较久之后,用户经常会发现 ChatGPT 已经“忘了”之前讲过的内容。另外一个典型场景是给 LLM 提供更多的新信息,像一些产品里能够对一整篇 PDF 甚至一整个知识库里的内容做理解和问答,那么自然不可能直接把所有这些额外信息都直接在 prompt 里扔给 GPT 去处理。
这时候就需要通过外部存储来帮助 GPT 拓展记忆。最简单的方法就是直接把这些对话记录,外部信息等以文本形式保存到文件或者数据库系统里,后续在与模型进行交互时,可以按需去获取这些外部存储中的信息。我们可以把 prompt 里的内容当成模型的“短期记忆”,那么这些外部存储自然就成为了“长期记忆”。除了前面提到的好处外,这种记忆系统模式还能一定程度上起到降低模型 hallucinations 的作用,避免纯粹依靠“生成”来实现任务目标。
获取长期记忆的方法,目前最常见的方式是通过“语义搜索”。大概意思就是利用一个
embedding 模型,将所有的记忆文本都转化为一个向量。而后续跟模型的交互信息也可以通过同样的
embedding 模型转化为向量,然后通过计算相似度来找到最相似的记忆文本。最后再将这些记忆文本拼接到
prompt 里,作为模型的输入。这类方法最热门的开源项目可以参考 OpenAI 官方的 ChatGPT Retrieval Plugin 和 Jerry Liu 的 LlamaIndex。
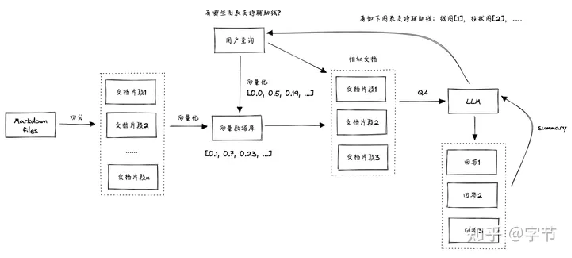
Retrieval Pattern
这种拓展模型记忆的模式相比人类大脑的运作方式来说感觉还有些“粗糙”,所谓的长期与短期记忆(包括 LangChain 与 LlamaIndex 中一些更复杂的实现),仍然是比较“hard coded”的感觉。如果未来在模型 context size 上有突破性的研究进展,那么当前的这类模式或许就不再需要了。
从整体的交互流程来看,这类模型记忆实现模式也可以看作是一种“任务执行”的方式,只不过这里的任务是“写入/获取记忆”,而不是“执行某个外部工具”。我们可以把两者统一来看,也就是当前大语言模型最常用的应用开发模式。后面我们也会看到,各种所谓的智能 agent 也都是在这个思路下进行拓展实现的。
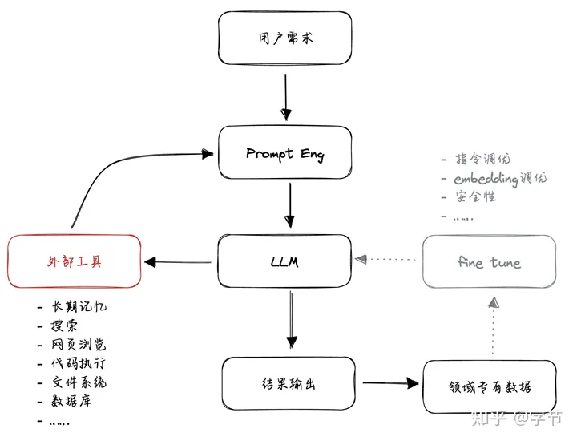
LLM 调用外部工具的应用模式
有意思的是,OpenAI 的 Jack
Rae 和 Ilya Sutskever 在之前的分享中也分别提到了 压缩即智慧 的理念。对于模型的“压缩率”来说,如果能更有效地使用这些“外部工具”,就能大幅提升很多特定任务 next token 预测的准确率。个人感觉这个方向的发展还有非常大的空间,例如从“有效数据”角度看,人类执行各类任务使用工具,甚至思维过程等数据会有非常高的价值。而从模型训练角度来看,如何能在过程中把模型利用工具的能力也体现在 loss function 里,可能也是个很有趣的方向。

提升“压缩率”的手段
AutoGPT
有了前面的铺垫信息,我们来理解 AutoGPT 这类 AI agent 工作的内部结构与核心逻辑就会比较容易了。这类项目绝大多数的主要创新还是在 prompt 层面,通过更好的提示词来激发模型的能力,把更多原先需要通过代码来实现的流程“硬逻辑”转化为模型自动生成的“动态逻辑”。以 AutoGPT 为例,它的核心 prompt 如下:
You are Guandata-GPT, 'an AI assistant designed to help data analysts do their daily work.'
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. 'Process data sets'
2. 'Generate data reports and visualizations'
3. 'Analyze reports to gain business insights'
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
从这大段的 prompt 可以看出来,AutoGPT
的确算得上是提示词应用模式当前比较先进的“集大成者”了,有很多可以学习的地方。相比经典的 reason +
act 模式,我们可以分别来看看它都做了哪些进一步的发展改进。
Constraints &
Resources
在这里告诉了模型你自己的各种局限性,也是很有喜感。例如模型的输入 context
size 有限制,所以你需要把重要的信息保存到文件里。尤其在代码生成场景中这个动作非常重要,否则无法实现长代码的生成和执行。另外 AutoGPT 里也给模型提供了长期记忆的管理功能,当前这类复杂 prompt 生成的解决任务的流程往往比较冗长,没有这类长期记忆的管理很容易就会导致模型的输出变得不连贯协调。
另外像默认的模型是“没有联网”的,所有的知识只更新到训练数据的截止日期。所以也明确告诉模型可以通过网络搜索来获取更多时效性的外部信息。
Commands
在 commands 也就是各类工具的选择上,这里给出的选项非常丰富。这也是为何很多文章宣传里提到 AutoGPT 能够完成多种不同任务的原因之一,灵活性与通用性很高。
具体的 commands 中,可以分为几大类,包括搜索、浏览网页相关,启动其它的 GPT agent,文件读写操作,代码生成与执行等。使用其它的 agent 的想法跟 HuggingGPT 有些类似,因为目前 GPT 模型对于越具体,细致的任务,生成的表现就越精确和稳定。所以这种“分而治之”的思路,是很有必要的。
Performance
Evaluation
这里给出了模型整体思考流程的指导原则,分为了几个具体维度,包括对自己的能力与行为的匹配进行 review,大局观与自我反思,结合长期记忆对决策动作进行优化,以及尽可能高效率地用较少的动作来完成任务。这个思考逻辑也非常符合人类的思考,决策与反馈迭代的过程。
Response
从 response 格式上来看,也是综合了几种模式,包括需要把自己的想法写出来,做一些 reasoning 获取相关背景知识,生成有具体步骤的 plan,以及对自己的思考过程进行 criticism 等。这些格式的限定也是对前面思维指导原则的具体操作规范说明。
具体 command 的生成与前面提到的
ReAct 方式基本一致。这里的 command 也是可以嵌套的,比如可以在一个 command 中启动另一个 GPT agent,然后再对这个 agent 发送 message,这样就可以实现更复杂的任务了。而在 LangChain 里,子 agent 与主流程之间应该只有一次调用和返回,相对来说比较受局限。
值得注意的是这么一大段 response 是模型一次交互生成的,而不像一些其它框架中会把计划,审视,动作生成等通过多轮模型交互来生成。个人感觉是因为 AutoGPT 生成的解决流程往往会非常冗长,如果每一个动作的生成都需要与 LLM 做多轮交互,耗费的时间和 token 量都会非常大。但如果某个具体决策动作的开销非常大,例如需要调用一个比较贵的
API 做图片生成,那么可能把这个动作做多次审视优化,最后做一次决策,可能整体成本会更低一些。
人工介入
如果大家自己跑过 AutoGPT,会发现模型很容易会把问题复杂化或者在执行计划层面“跑偏”。所以在具体执行过程中,AutoGPT 也允许用户来介入,对于每一个具体执行步骤提供额外的输入来指导模型行为。经过人工反馈输入后,模型会重新生成上述的 response,以此往复。大家可以访问这个 带界面的
AutoGPT 产品,实际体验一下这个流程。虽然从实际完成任务角度来看还在比较早期的阶段,但这个 prompt 的设计和交互方式还是挺有启发性的。
BabyAGI
相比 AutoGPT 来说,BabyAGI
是一个相对更聚焦在“思维流程”方面尝试的项目,并没有添加对各种外部工具利用的支持。其核心逻辑非常简单:
.
从任务列表中获取排在第一位的任务。
.
获取任务相关的“记忆”信息,由任务执行 agent 来执行这个任务,获取结果。目前这个执行就是一个简单的 LLM 调用,不涉及外部工具。
.
将返回结果再存放到记忆存储中。
.
基于当前的信息,如整体目标,最近一次执行结果,任务描述,还未执行的任务列表等,生成所需要的新任务。
.
将新任务添加到任务列表中,再判断所有任务的优先级,重新排序。
作者表示这个过程就是在模拟他一天真实的工作流程。早上起来看下有哪些任务要做,白天做任务拿反馈,晚上再看下基于反馈有没有新的任务要加进来,然后重新排下优先级。
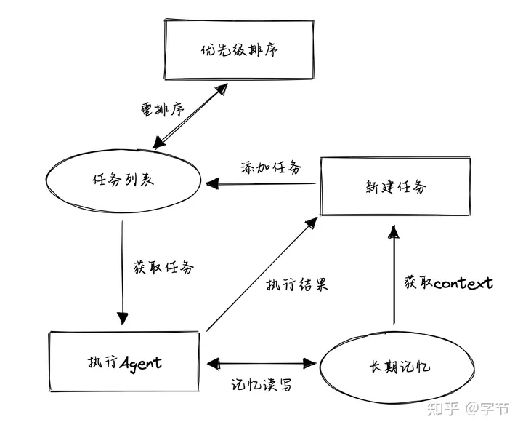
BabyAGI 运作流程
整个项目的代码量很少,相关的 prompts 也比较简单易懂,有兴趣的同学可以自行阅读。
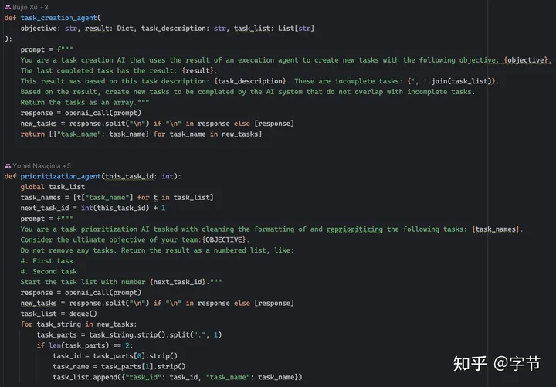
BabyAGI prompts 示例
后续也出现了一些在这个项目上的进化版本,例如这个 BabyASI,借鉴了 AutoGPT 添加了对 search,代码执行等工具的支持。理论上来说,如果这个 ASI(Artificial Super Intelligence)真的足够聪明,甚至可以产生代码给自己做 prompt 优化,流程改造,甚至持续的模型训练等,让 GPT 自己开发未来的 GPT,想想是不是很带感 。
HuggingGPT
如果说 BabyAGI 更多的是探索了
plan & execution 这个应用 LLM 的模式,那么 HuggingGPT 这个相对早一些的工作更多地展示了在“外部工具”这个层面的想象空间。其核心运作逻辑也是计划加上执行,只不过在执行工具层面,可以利用丰富的“领域专业模型”来协助 LLM 更好地完成复杂任务,如下图所示:

HuggingGPT 流程
通过作者给出的各种例子,可以看出 LLM 能够很好地理解任务并调用相应模型来解决。虽然很多例子可能会被后来多模态的 GPT 系列通过端到端的方式直接完成,但这个想法还是挺有意思的。外部工具不仅仅局限于搜索,API 调用这些,也可以调用其他复杂的模型。未来或许不光能调用模型,还能触发数据收集,模型训练/微调等动作,完成更加复杂的任务流程。
从另一个角度看,对于一些目标明确,专业化且高频的场景,往往具有丰富的数据,可以通过构建一个更小的专有模型来很好地以较低成本来完成相关诉求。而像一些更加模糊,需求多变的“胖尾”诉求,就可以更好地利用大模型强大的理解,推理,生成能力来满足,未来或许会替换到很多当基于启发式规则驱动的业务流程。这或许是未来大模型与小模型的一种常见组合应用形态。
Camel / Generative
Agents
在前面 AutoGPT 里,我们看到了一些给模型 agent 加上长期记忆,以及调用其它 agent 进行交互的玩法。另外在前面的 prompt 模式中也发现,让模型进行自我审视,或者先计划再执行的方式往往能达到非常好的效果提升。如果沿着这个方向进一步推演,是否可以将多个 agent 组成一个团队,分别扮演不同的角色,是否能更好地解决一些复杂问题,甚至让这个小的“社群”演化出一些更复杂的行为模式甚至新知识的发现?最近就有两篇很火的工作跟 agent“社群”的方向相关。
Camel
在 Camel 这篇工作中,作者的思路是通过 LLM 来模拟用户和 AI 助手,让两个 agent 进行角色扮演(例如一个是业务专家,一个是程序员),然后让他们自主沟通协作来完成一项具体的任务。这个想法还是比较直接的,不过作者也提到 prompt 的设计还是蛮重要的,否则很容易出现角色转换,重复指令,消息无限循环,有瑕疵的回复,何时终止对话等等问题。有兴趣的同学可以具体看项目代码中给出的 prompt 设定,添加了非常多的明确指令来让 agent 按照预想的设定来沟通协作。

AI 用户与 AI 代码助手 prompt
除了 agent prompt 和运作模式的设计优化外,作者还设计了 prompt 来自动生成各种角色,场景诉求等内容。这些内容在自动组成各种角色扮演的场景,就能收集到各个场景下 agent 的交互情况,便于后续做进一步的挖掘分析。感兴趣的同学可以在 这个网站 来探索他们已经生成的各种 agent 组合之间的对话记录。这个项目代码也做了开源,会是一个非常好的研究 AI agent 社群研究方向的起点。

数据生成 prompt
Generative Agents
而在 Generative Agents 这篇工作中,作者将 25 个拥有身份设定的模型 agent 组成了一个虚拟小镇社群,每个 agent 都具有记忆系统,并通过做计划,行动应答,自我反思等机制来让他们自由活动,真正来模拟一个社群的运作。从模拟过程来看这个社群也“涌现”了不少真实社会中的现象,非常有意思。
从技术角度来说,这篇文章中有几个 agent 行为的设定值得学习:
·
每个
agent 的记忆获取做得更加细致,会结合时效性,重要度和相关度来做相关记忆的召回。相比简单的向量相似度搜索来说效果会好很多。
·
记忆的存储方面也添加了 reflection 步骤,定期对记忆进行反思总结,保持 agent 的“目标感”。
·
在
plan 生成方面也做了多层级的递归,由粗到细生成接下来的行动计划,跟我们的日常思考模式也更接近。
·
通过“人物采访”的方式来评估这些行为设定的效果,消融实验中都能发现明显的提升。
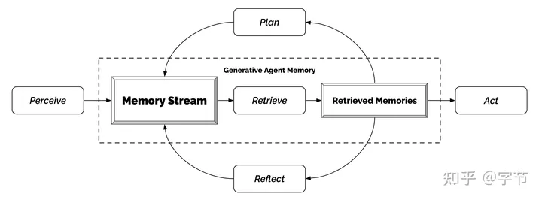
Agent 架构
这一整套 identity,plan, act/react,reflect,memory
stream 的逻辑看起来也挺合理的,与 AutoGPT 的做法可以进行一些互补。当然局限性应该也有不少,比如模拟过程中 agent 之间都是一对一的谈话,而没有会议/广播这种设定。目前模拟运行的时长也有限,比较难确保长时间的运行下 agent 的记忆、行为模式的演化,社群整体目标的探索与推进等方面的效果。
从应用角度来看,目前好像也主要集中在社会活动模拟,游戏应用等。是否能拓展到任务处理,知识探索等更广阔的领域,还有待进一步探索。
Prompt Patterns
最后我们来总结一下前面这些项目中体现的 prompt 设计模式。
.
CoT prompt,在给出指令的过程中,同时也给出执行任务过程的拆解或者样例。这个应该很多人都用过,“let's think step by step”
.
“自我审视”,提醒模型在产出结果之前,先自我审视一下,看看是否有更好的方案。也可以拿到结果后再调用一下模型强制审视一下。比如 AutoGPT 里的“Constructively self-criticize
your big-picture behavior constantly”。
.
分而治之,大家在写 prompt 的时候也发现,越是具体的 context 和目标,模型往往完成得越好。所以把任务拆细再来应用模型,往往比让它一次性把整个任务做完效果要好。利用外部工具,嵌套 agent 等也都是这个角度,也是 CoT 的自然延伸。
.
先计划,后执行。BabyAGI,HuggingGPT 和
Generative Agents 都应用了这个模式。也可以扩展这个模式,例如在计划阶段让模型主动来提出问题,澄清目标,或者给出一些可能的方案,再由人工 review 来进行确认或者给出反馈,减少目标偏离的可能。
.
记忆系统,包括短期记忆的 scratchpad,长期记忆的 memory stream 的存储、加工和提取等。这个模式同样在几乎所有的 agent 项目里都有应用,也是目前能体现一些模型的实时学习能力的方案。
可以看出这些模式都与人类的认知和思考模式有很大的相似性,历史上也有专门做 cognitive architecture 相关的研究,从记忆,世界认知,问题解决(行动),感知,注意力,奖励机制,学习等维度来系统性思考智能体的设计。个人感觉目前的 LLM agent 尝中,在奖励机制(是否有比较好的目标指引)和学习进化(是否能持续提升能力)这两方面还有很大的提升空间。或许未来 RL 在模型 agent 这方的应用会有很大的想象空间,而不仅仅是现在主要用来做“价值观对齐”。
认知架构研究
常见问题
如果大家有实际上手玩过这些项目,应该能切实感受到一些当前模型 agent 的问题和局限性。例如:
.
记忆召回问题。如果只是做简单的 embedding 相似性召回,很容易发现召回的结果不是很好。这里应该也有不少可以改进的空间,例如前面提到的 Generative Agents 里对于记忆的更细致的处理,LlamaIndex 中对于 index 结构的设计也有很多可以选择与调优的地方。
.
错误累积问题。网上给出的很多例子应该都是做了 cherry-picking 的,实际上模型总体表现并没有那么惊艳,反而经常在前面一些步骤就出现了偏差,然后逐渐越跑越远……这里一个很重要的问题可能还是任务拆解执行,外部工具利用等方面的高质量训练数据相对匮乏。这应该也是 OpenAI 为啥要自己来做 plugin 体系的原因之一。
.
探索效率问题。对于很多简单的场景,目前通过模型 agent 来自行探索并完成整个解决过程还是比较繁琐耗时,agent 也很容易把问题复杂化。考虑到 LLM 调用的成本,要在实际场景落地使用也还需要在这方面做不少优化。一种方式可能是像
AutoGPT 那样可以中途引入人工的判断干预和反馈输入。
.
任务终止与结果验证。在一些开放性问题或者无法通过明确的评估方式来判断结果的场景下,模型 agent 的工作如何终止也是一个挑战。这也回到了前面提到的,执行 task 相关的数据收集与模型训练以及强化学习的应用或许可以帮助解决这个问题。
你在使用这些模型 agent 过程中有碰到过什么样棘手的问题,有什么好的解决方法?或者有没有发现什么场景已经可以由现有的 agent 很好地满足?欢迎在评论区分享交流。
出自:https://zhuanlan.zhihu.com/p/622947810
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip