在2023年的整个夏季的100天中,笔者阅读了超过500篇论文,直到上周读到一篇都柏林大学爱尔兰AI应用研究中心《为会话式AI构建信任》的论文后,脑中思考许久的人工智能应用范式渐渐浮现。



在2023年的整个夏季的100天中,笔者阅读了超过500篇论文,直到上周读到一篇都柏林大学爱尔兰AI应用研究中心《为会话式AI构建信任》的论文后,脑中思考许久的人工智能应用范式渐渐浮现。
我们先来看看这篇论文:
Building Trust in Conversational AI: A Comprehensive
Review and Solution Architecture for Explainable, Privacy-Aware Systems using
LLMs and Knowledge Graph
https://arxiv.org/pdf/2308.13534.pdf
来自爱尔兰都柏林大学爱尔兰AI应用研究中心的团队首先构建了一个大语言模型的数据库(数据表)LLMXplorer,数据覆盖了150多种大语言模型,从17个关键指标上审视大语言模型的训练方法和资源、训练数据、道德对齐、和私有数据安全性和在不同垂直领域的适用性。
应该说仅仅发表一个对现有大模型成果的梳理和评价所带来的行业价值可能并没有多么大,但是团队同时提出的无缝整合知识图谱动态结构和大语言模型、并且支持身份权限控制的新架构方案,很大程度上启发了全行业深度的思考。
整个架构方案可以概括为一个十步的工作流,参见下图:
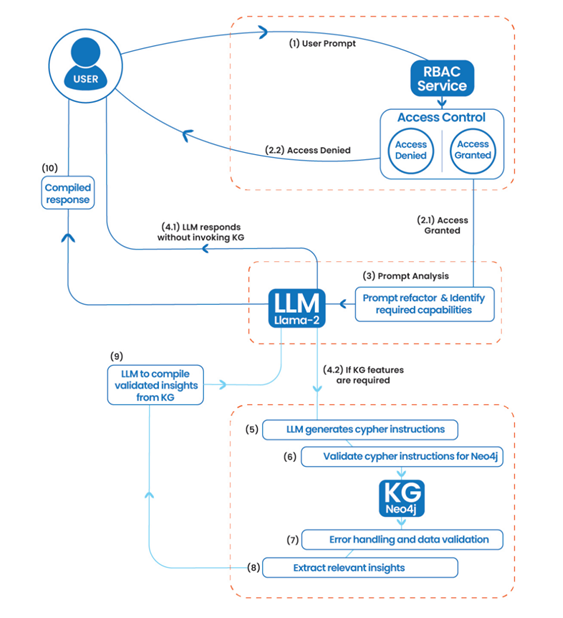
看完这张流程图,我想应该有不少同行会和笔者有同样的预感:这套十步工作流极有可能成为未来三到五年乃至更长时期内人工智能大模型的应用范式。
这个预判的起始于思维链(CoT,Chain-of-Thought)涌现的那个时刻。通过CoT咒语般的提示词 “Step by Step”,大语言模型一改过去的一本正经胡说八道,开始认真严肃的逐步推导,虽然推导得出的答案有时候还是会出现张冠李戴的低级错误,但是推导的过程却已经展现了一定的因果推理的能力。
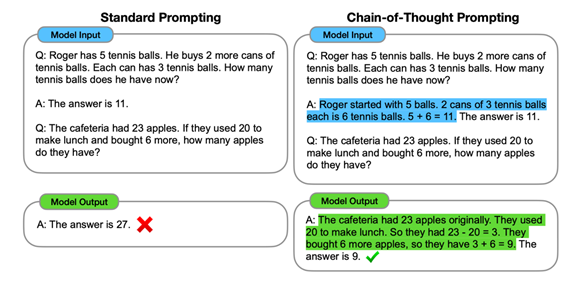
图片来源:Chain-of-Thought
Prompting Elicits Reasoning in Large Language Models,
https://arxiv.org/pdf/2201.11903.pdf
并且在CoT之上引入一致性自检(Self Consistency)的投票机制,模型的表现还能获得提升。在这个思路之下,随之而来的是思维树(ToT,Tree-of-Thought),将单向线性的逐步推导,引入了自带分支的逻辑判断流程。近期还有团队在ToT的基础上,模拟人类大脑的快慢双系统,引入了混合树的模式,通过快系统和慢系统互相校验。
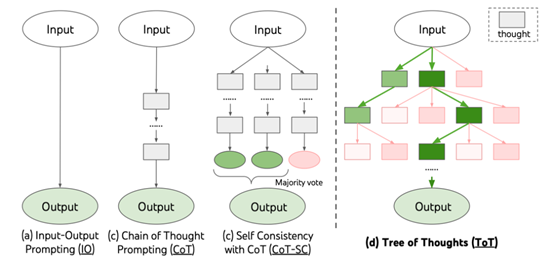
图片来源:Tree
of Thoughts: Deliberate Problem Solving with Large Language Models,
https://arxiv.org/pdf/2305.10601.pdf
到最近集中发布的多篇累进式推理(CR,Cumulative Reasoning)和思维图(GoT,Graph-of-Thought),都提出了基于流程图思维的推理任务分解、执行并在检验后聚合的推理模式。其中也有不少论文引入了类似Agent的概念,让模型扮演任务拆解、流程规划、答案校验、聚合应答等多种角色,实现协同操作。
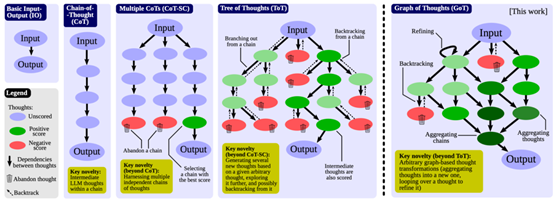
而一旦采用Agent智能体这种思路,有一个问题就绕不过去,如何在Agent之间共享记忆和信息,以便多个Agent能够协同完成一个复杂的任务,显然在大语言模型之外外挂一个存储空间,用于缓存:任务的总目标、任务分解的流程图、各层各步子任务的上下文、各个Agent的角色和历史行为、任务和行为之间的对应关系,而当这些共享的记忆中还要包含任务相关的垂直领域信息时,我们实质上为大语言模型引入了外部的知识库。
笔者在上一篇《AI Native也许是个伪命题》(点击链接阅读原文)中也提到了业界面临的真问题:Knowledge Native ,也就是“知识原生”的问题。更好的训练人工智能尤其是垂直领域智能能力的第一步,也应该着眼于将人类已知的知识表示为人工智能算法能快速解析、高效计算的形式,也许是词或句的向量空间嵌入、或是Taxonomy分类树、又或是Knowledge Graph知识图谱。
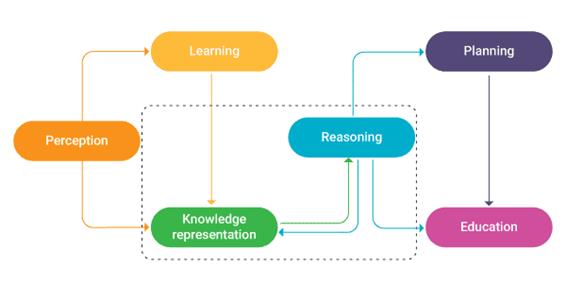
图片来源:《Classifying
Knowledge Representation in AI》,Fingent,https://www.fingent.com/blog/classifying-knowledge-representation-in-artificial-intelligence/
按照垂直领域知识的应用的深度差异,人工智能的应用范式会包含四大类。
· 将知识库作为外部检索和约束
由于大模型存在幻觉、在推理能力上还有不足,因此可以使用外部知识库对模型输出进行相关性判定、事实性校验、人类偏好对齐和推理准确性评价,可以有效的改善模型的表现,尤其是在引入向量化和图谱化的知识库后,可以通过向量和图计算的方法校验关联性和推理有效性。
· 利用知识库完善提示词工程
检索知识库我们还可以对复杂的任务进行拆解,生成思维树或图结构的分步骤提示词,并在任务中引入累进推理或者自检机制。除了检索现有的知识库做任务规划,我们也可以将提示词工程所积累的提示词和对应的高质量有效回答,也不断的追加到知识库,构建一个动态增补迭代的知识库。同时这些高质量问答的获取过程也是一种典型的知识蒸馏方法,获得的知识库也可以用于其他模型的监督微调。
· 利用知识库对大模型进行高效参数微调(PEFT)
使用知识库的语料,单独训练构建大模型的LoRA低秩适配器,实现大模型局部参数权重的微调。目前已经看到的行业实践包括:通过在Alpaca-LoRA中加入中文语料的训练获得中文能力、通过ChatGLM和中美金融数据LoRA构建的FinGPT、基于中文医疗数据LoRA和Ziya-LLaMa-13B的Medical-GPT。如此构建的好处是,既能保持基础模型的通用语言能力,也能获得垂直领域的知识应用能力,还不需要花费太多的训练时间和算力资源,比较适合拥有垂直领域高质量数据的中小型团队。
· 直接对知识库的数据做无监督的预训练和监督微调
显然金融领域的Bloomberg-GPT、法律领域的ChatLaw、医疗领域的Med-PaLM 和自然科学研究领域的DARWIN等垂直领域大模型都是类似的思路:历史积累丰富垂直行业数据经过清洗标注后形成知识库,在大模型基座上从头进行训练。如果可以使用图谱化的知识库参与大模型的预训练,那么大模型在基于知识的推理任务上也将获得更好的表现。不过这样的训练的成本昂贵、算力需求的规模极大,因此不是小型初创团队很难轻松完成,同时还有在局部领域过度训练,导致基础模型的通用能力下降等问题。
而在上一篇中,我们也提到的人工智能应用开发团队和创业企业在垂直领域知识遇到的相关问题:
1. 高质量数据缺乏、尤其是垂直领域的高质量数据
2. 私有数据的结构混乱
3. 数据清洗、数据标注的成本高
4. 技术人员对客户所在的垂直行业缺少认知
5. 现有的数据和知识如何被AI模型所利用
显然如何更好的为大模型提供垂直领域高质量数据、尤其是领域知识,必将是未来三到五年内有巨大潜在商业价值的探索方向,而且需要解决的问题也不仅是数据集、知识库、知识图谱,还包含了:规模化构建知识库的方法、支持高效检索的存储方式、更好利用知识库进行模型表现提升的框架。
所以,笔者坚信:构建垂直领域知识体系、提升基础大模型的专业表现的赛会已经拉开序幕,全世界也在期待赛手们的全情投入。
出自:https://mp.weixin.qq.com/s/ZpP6On_1pX6cwCNjCxt-9g
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip