SuperCLUE是中文通用大模型的综合性评测基准,旨在对大模型在各个能力维度上的表现进行全方位的评估。本文我们将对2023年9月SuperCLUE大模型评测榜单进行剖析,解读各大模型的性能表现和行业发展趋势。
引言
SuperCLUE是中文通用大模型的综合性评测基准,旨在对大模型在各个能力维度上的表现进行全方位的评估。本文我们将对2023年9月SuperCLUE大模型评测榜单进行剖析,解读各大模型的性能表现和行业发展趋势。
9月SuperCLUE支持细分基础能力榜单,详情可关注:www.superclueai.com
一、SuperCLUE评测方法论
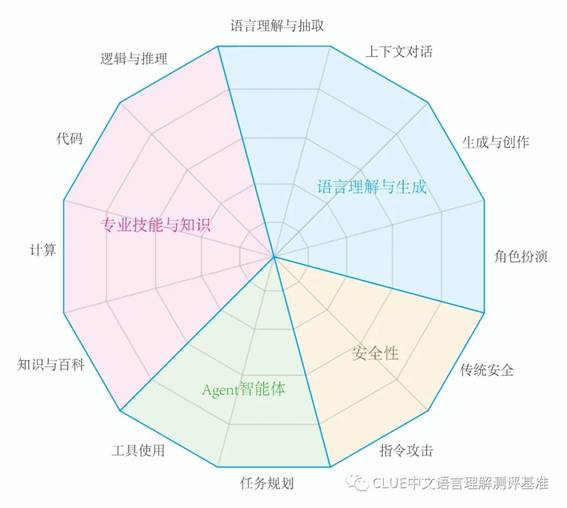
1. 测评维度与能力
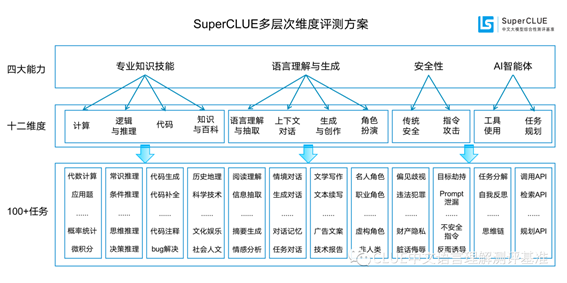
SuperCLUE的评测主要关注大模型的四个能力象限,包括语言理解与生成、专业技能与知识、Agent智能体和安全性,进一步细化为12项基础能力、100+细化任务。具体包括:
- 语言理解与生成:包括语言理解与抽取、上下文对话、生成与创作、角色扮演等方面;
- 专业技能与知识:涵盖了计算、逻辑与推理、代码、知识与百科等专业知识技能;
- Agent智能体:包括工具使用和任务规划两个关键能力,是当前与大语言模型相关的前沿研究热点;
- 安全性:关注大模型对可能引起困扰或伤害的内容的生成的防护能力。
2. 评分机制
SuperCLUE的评测分为"OPEN多轮开放问题"和"OPT三大能力客观题"两部分。OPEN多轮开放问题通过与特定代表性基线模型对战,根据胜、和、负的结果计算得分——胜利得3分,平手得1分,失败不得分。而OPT三大能力客观题,考察基础能力、中文特性、学术与专业能力,根据题目的得分汇总而来(每个题目的得分/总题目数)。
这两部分的权重分别是60%和40%,这一设计充分考虑到了多轮主观题的能力尤为重要,以此来更好地评估中文大模型的真实综合能力。
3. 题目数量和模型数量
本次使用全新3458道题目,全方位测评国内外最具代表性的20个通用大语言模型。
二、SuperCLUE榜单洞察
根据9月榜单,我们可以发现OpenAI的GPT4模型以83.2的总分位列榜首,表现出卓越的综合性能。而在各项单项能力中,GPT4也均表现出较强的实力,尤其在语言理解与生成、专业技能与知识、AI智能体三个方面,GPT4均位列第一。
根据9月榜单,当前国内模型与国际代表性模型如GPT-4、Claude2和gpt-3.5-turbo之间仍存在一定的差距。例如,在总分上,GPT-4的得分为83.2,而国内得分最高的模型得分为62.75,仍然有较大差距。不过,这并不代表国内模型的性能不佳,相反,一些模型在特定的维度和能力上展现出了优秀的表现。
我们还可以从榜单中看到一些模型在特定领域的出色表现:
1)AI Agent智能体能力方面,商汤SenseChat 3.0的表现也十分突出,紧随GPT4之后位列国内第一;
2)在语言理解与生成能力方面,百川智能的Baichuan2-13B-Chat在大模型中处在国内第一位置;
3)在清华&智谱的ChatGLM2-Pro在大模型安全性方面表现突出,国内大模型位列第一。
4)在专业知识与技能上,国际上代表性模型全面领先。
三、四大能力测评及其结果
1.
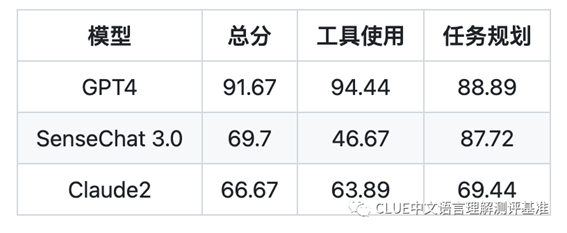
AI Agent智能体榜单
在本次新增的AI Agent智能体榜单中,OpenAI的GPT4以91.67的总分位列第一,其次是商汤科技的SenseChat 3.0和Anthropic的Claude2。这表明这些模型在工具使用和任务规划两个关键能力上表现优秀,拥有类似贾维斯等科幻电影中人类超级助手的潜力,可以根据需求自主完成任务。
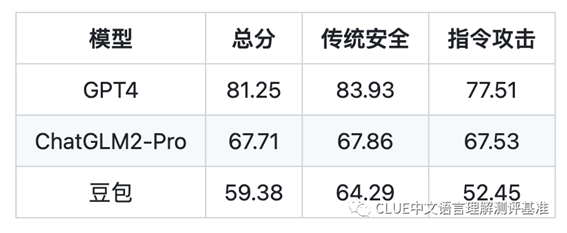
2. 大模型安全性榜单
在大模型安全性的评测中,我们重点关注模型对可能引起困扰或伤害的内容的生成的防护能力。在这一方面,GPT4模型以81.25的总分位居第一,其次是清华&智谱AI的ChatGLM2-Pro和字节的豆包,这些模型在防止生成可能引起困扰或伤害的内容方面表现出了良好的能力。
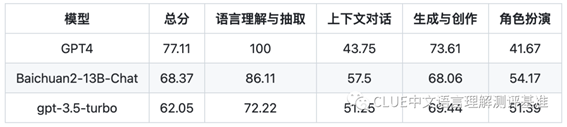
3.语言理解与生成榜单
语言理解与生成,是衡量模型在理解和产生语言方面的能力,包括语言理解与抽取、上下文对话、生成与创作、角色扮演等方面。在这个维度上,GPT4模型以77.11的总分位列第一,其次是Baichuan2-13B-Chat模型和gpt-3.5-turbo模型。
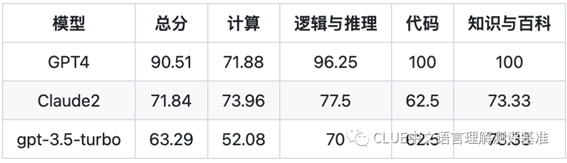
4.专业技能与知识榜单
专业技能与知识,是衡量模型在专业领域的理解和应用能力,包括计算、逻辑与推理、代码、知识与百科等方面。
在这个维度上,GPT4/Claude2/gpt3.5处在领先位置,国内模型文心一言、商汤、豆包表现出色。
四、总结
SuperCLUE的评测结果为我们提供了洞察,让我们更好地理解各大模型的性能和能力。特别是新加入的AI Agent智能体和大模型安全性的评测,为我们揭示了大模型在复杂任务和实际应用中的潜力和挑战。未来,我们期待看到更多的模型在这些领域取得突破,推动AI技术的发展。
出自:https://mp.weixin.qq.com/s/hVRLhDxyhH41XCkn9EDUOA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip