“ 为了实现LLM的高效流式部署,研究人员提出了 Streaming LLM 框架,其核心思路是保留最近的标记和重要的注意力点,同时丢弃不必要的中间标记。该方法允许LLM高效处理更长的上下文,在多轮对话等场景中展现出巨大应用潜力。”
“ 为了实现LLM的高效流式部署,研究人员提出了 Streaming LLM 框架,其核心思路是保留最近的标记和重要的注意力点,同时丢弃不必要的中间标记。该方法允许LLM高效处理更长的上下文,在多轮对话等场景中展现出巨大应用潜力。”

01
—
在和ChatGPT这类的大模型LLM对话时,有时候会感觉好像在与一只七秒记忆的鱼对话,因为它能处理的令牌token长度是有限制的。对话长度超过一定数量后,它会遗忘之前对话的内容。
如果大模型能够像人一样长时间对话并记住之前的内容,那么我们将拥有更广泛的应用可能性,让AI能够做更多事情。
在多轮对话和其他流媒体应用中,因为预计会有持续较长时间的互动,因此行业内正在研究一种方法,使大型LLM模型能够处理更长的上下文信息。
由麻省理工学院、卡内基梅隆大学、Meta 公司联合组成的研究团队最近发表的论文《EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS》一文针对上述问题,提出了一种优化方案:可以使LLM在不需要微调的情况下推广到无限序列长度。该框架可以使Llama-2、MPT、Falcon和Pythia在高达400万个令牌的情况下进行稳定和高效的语言建模。同时研究发现,在预训练期间添加一个占位符令牌作为专用的注意力汇可以进一步提高流式部署的性能。
论文地址:
http://arxiv.org/abs/2309.17453
开源地址:
http://github.com/mit-han-lab/streaming-llm
核心思想:该方案并没有改变LLM上下文的大小,只保留最近的标记和注意力,丢弃中间的标记,这意味着方案关注最新的标记。同时上下文窗口仍受大模型本身的限制。例如,如果Llama-2在预训练时使用了4096个上下文窗口,那么Llama-2上的StreamingLLM的最大缓存大小仍为4096。
02
—
下图为StreamingLLM与现有方法的对比图示,建模任务为:语言模型在长度为L的文本上进行预训练,预测第T个标记(T≫L)。
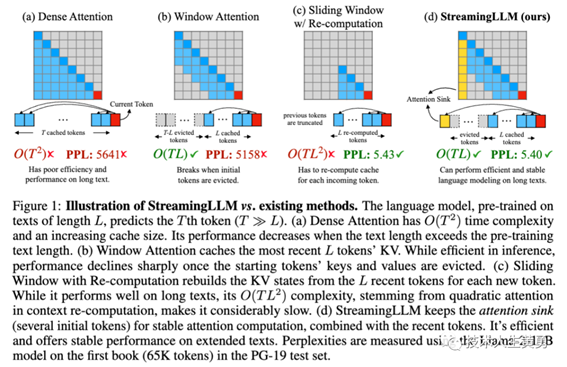
(a) 在密集注意力 Dense
Attention中,时间复杂度为O(T^2),并且随着缓存大小的增加,性能会下降,特别是当文本长度超过预训练文本长度时。
(b) 窗口注意力
Window Attention则维护了一个固定大小的滑动窗口,仅缓存了最近L个标记的KV。虽然它具有高效的推理能力,能够在填满缓存后维持稳定的内存使用率和解码速度,但一旦序列长度超过缓存大小,即使只是删除第一个标记的KV,模型就会崩溃,性能急剧下降,如图所示。
(c) 重新计算的滑动窗口Sliding
Window w/Re-computation ,每次生成新标记时都重新构建最近L个标记的KV状态。虽然这种方法在处理长文本上效果良好,但由于上下文重新计算中的二次注意力,时间复杂度为O(TL^2),导致速度明显较慢,因此在实际的应用中并不切实可行。
(d) StreamingLLM 通过将注意力集中在一些初始标记上,并与最近的标记相结合,来实现稳定的注意力计算。这种方法非常高效,能够在处理扩展文本时提供可靠的性能。
四种注意力机制的评测对比
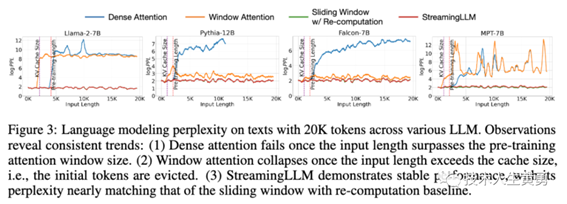
一旦输入长度超过预训练注意窗口大小,Dense attentions 就会失败。
一旦输入长度超过缓存大小,窗口注意力就会崩溃,即初始tokens 被丢弃。StreamingLLM 表现出稳定的性能,PPL 几乎与带有重新计算基线的滑动窗口相匹配。
03
—
实现
自回归语言模型(即现在流行的大模型类型)中,窗口注意力机制存在失败现象,即注意力分数大量分配给初始标记,这些标记被称为“注意力汇聚点”,尽管它们缺乏语义意义,但仍然收集了显著的注意力分数。
这是由于Softmax操作需要所有上下文标记的注意力分数总和为1,因此即使当前查询在许多先前标记中没有强匹配,模型仍然需要将这些不需要的注意力值分配到某个地方,以便总和为1。
StreamingLLM利用了注意力汇聚(attention
sink)具有较高的注意力值的特点,保留它们可以使注意力分数分布保持接近正常。因此,StreamingLLM简单地将注意力汇聚点的标记Key-Value(仅需4个初始标记即可)与滑动窗口的Key-Value一起用于锚定注意力计算并稳定模型性能。
效果
StreamingLLM可以让Llama-2、MPT、Falcon和Pythia进行稳定而高效的语言建模,在预训练过程中添加一个占位符作为专门的注意力汇聚,可以进一步改进流式部署。
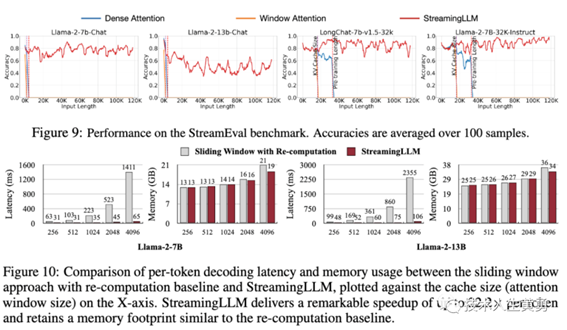
与滑动窗口及重新计算相比,StreamingLLM实现了高达22.2倍的加速,实现了LLM的流式使用。
04
—
FAQ
1、对于LLMs来说,"处理无限长输入"意味着什么?
使用LLM处理无限长文本是一项挑战。存储之前所有的键和值(KV)状态需要大量内存,模型可能难以生成超过其训练序列长度的文本,StreamingLLM通过只保留最新的标记和注意力汇聚,而丢弃中间的标记。这样,模型就能在不重置缓存的情况下从最近的标记生成连贯的文本,这是早期方法所不具备的能力。
2、LLM的上下文窗口会增加吗?
不会。上下文窗口保持不变,只保留最近的标记和注意力,丢弃中间的标记,这意味着模型只能处理最新的标记。上下文窗口仍受初始预训练的限制。例如,如果Llama-2在预训练时使用了4096个上下文窗口,那么Llama-2上的StreamingLLM的最大缓存大小仍为4096。
3、是否可以在StreamingLLM中输入长篇文本(如一本书)进行摘要?
虽然可以输入长篇文本,但模型只能识别最新的标记。因此,如果输入的是一本书,StreamingLLM可能只会对结尾段落进行摘要,而这些段落的内容可能并不深刻。正如前面所强调的,方案既没有扩大LLM的上下文窗口,也没有增强它们的长期记忆。StreamingLLM的优势在于无需刷新缓存就能从最近的标记生成流畅的文本。
4、StreamingLLM的理想用例是什么?
StreamingLLM针对多轮对话等流式应用进行了优化。它非常适合模型需要持续运行而不需要大量内存或依赖过去数据的场景。基于LLM的日常助手就是一个例子。StreamingLLM可以让模型持续运行,根据最近的对话做出响应,而无需刷新缓存。早期的方法要么需要在对话长度超过训练长度时重置缓存(丢失最近的上下文),要么需要根据最近的文本历史重新计算KV状态,而这可能会非常耗时。
具体实践效果还需要根据实际场景实验验证,更多细节请阅读论文原文。
参考资料:
http://arxiv.org/abs/2309.17453
出自:https://mp.weixin.qq.com/s/dTWAvdCwHRb3uCEe5PclJA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip