随着AIGC的发展,传统的网络搜索模式也在接受这前所未有的挑战,首当其冲的就是各大搜索引擎,比如bing在自家浏览器中搭载了chatgpt,能够根据搜索的内容进行整合,并生成逻辑清晰,而且相对准确的信息,极大的增加了传统搜索需要逐一点开网页进行浏览,人工提取有效信息的效率。
随着AIGC的发展,传统的网络搜索模式也在接受这前所未有的挑战,首当其冲的就是各大搜索引擎,比如bing在自家浏览器中搭载了chatgpt,能够根据搜索的内容进行整合,并生成逻辑清晰,而且相对准确的信息,极大的增加了传统搜索需要逐一点开网页进行浏览,人工提取有效信息的效率。当然,这也是一个不可逆转的趋势。
但是由于网络环境以及各类AI工具的的兴起,各类收费工具也层出不穷,这是作为一个底层用户很难承担起的,所以,只能把目光投向一些开源的项目,然后搭建一些简单的工具来完成相应的功能。
最近OPENAI的GPT4.0的出现,让AIGC有了新的玩法,各类插件的接入,让一些的传统的任务也变得简单、智能。比如搜索、编程等等
国内也出现了类似的开源的,比如我前面图文中介绍的更强大的双语对话模型——ChatGLM3。在前面的图文中,我们只介绍了基本的对话模式,这次我们来简单体验下他的工具模式
可以通过在 tool_registry.py 中注册新的工具来增强模型的能力。只需要使用 @register_tool 装饰函数即可完成注册。对于工具声明,函数名称即为工具的名称,函数 docstring 即为工具的说明;对于工具的参数,使用 Annotated[typ: type,
description: str, required: bool] 标注参数的类型、描述和是否必须。
例如,get_weather 工具的注册如下:
1 @register_tool
2 def get_weather(
3 city_name: Annotated[str, 'The name of the city to be queried', True],
4 ) -> str:
5 """
6 Get the weather for `city_name` in the following week
7 """
8 ...
当然,要启动这个工具模式,首先得启动集成的demo。如果你是windows系统,需要修改一下model环境变量,在composite_demo文件夹下打开client.py文件
MODEL_PATH = os.environ.get('MODEL_PATH', 'your model path')
然后安装这个文件夹下requirements.txt中的相关依赖,然后启动
streamlit run composite\main.py
就会出现如下界面:
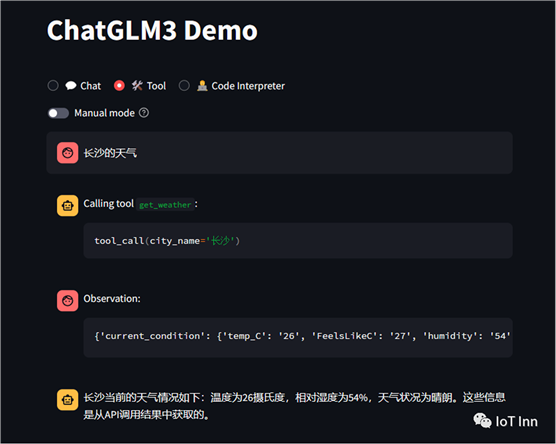
我们选择工具模式,默认有两个工具,一个是查询天气,一个是生成随机数,我们先来体验下,然后再制作一个自己的工具
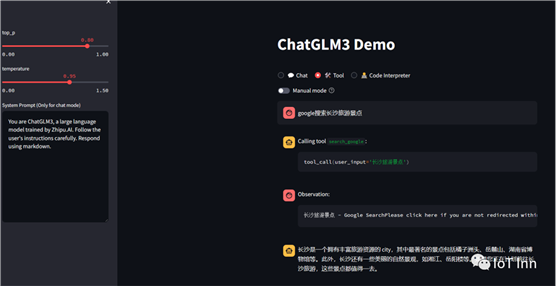
现在我们能制作一个自己的工具,就做一个简单的浏览器搜索好了,但是也只能做一些简单的文本搜索,要仔细浏览每一个链接,需要更精细的爬虫,留给各位同学自己去实现吧。
这里我们用selenium和bs4来实现一个简单的google搜索爬虫
1 search_access = False
2 service = Service()
3 options = webdriver.ChromeOptions()
4 options.add_argument('headless')
5 # options.add_argument('--disable-infobars')
6 # options.add_argument('--disable-dev-shm-usage')
7 #options.add_argument('--no-sandbox')
8 #options.add_argument('--disable-gpu')
9 # options.add_argument('--remote-debugging-port=9222')
10
11 driver = webdriver.Chrome(service=service,options=options)
12 driver.implicitly_wait(10)
13 driver.get('https://www.google.com/')
14 # print(driver.title)
15 html = driver.page_source
16
17 def google_results(query):
18
19 try:
20 search = driver.find_element(By.NAME, 'q')
21 search.send_keys(query)
22 search.send_keys(Keys.ENTER)
23
24 items = driver.find_elements(By.CLASS_NAME, "LC20lb")
25 addrs = driver.find_elements(By.CLASS_NAME, "yuRUbf")
26
27 all = zip(items, addrs)
28
29 content = ""
30
31 for item in all:
addr = item[1].find_element(By.TAG_NAME, 'a').get_attribute('href')
33 # print(f'{item[0].text} - {addr}')
34 #print(BeautifulSoup(driver.page_source,'html.parser').get_text()) 35 # content = driver.get(addr).find_element(By.CLASS_NAME, 'ULSxyf').text
36 # print(content)
37 content += BeautifulSoup(driver.page_source,'html.parser').get_text() + "\n"
38
39 except NoSuchElementException:
40 print('无法定位')
41
42 if content == "":
43 return("没有找到结果")
44 else:
45 return content
46
47 driver.quit()
然后将这个工具注册进去:
1 @register_tool
2 def search_google(
3 user_input: Annotated[str, 'the content of the user input', True]) 4 -> str:
5 """
6 Search the 'user input' on google
7 """
8
9 search_data = google_results(user_input)
10
11 return search_data
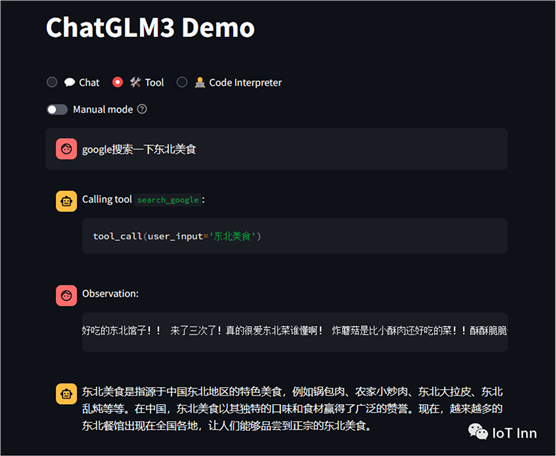
接着我们重启一下ChatGLM3 ,然后选择工具模式,我们借用这个工具来搜索一下东北的美食
然后我们搜索一下纽约时间
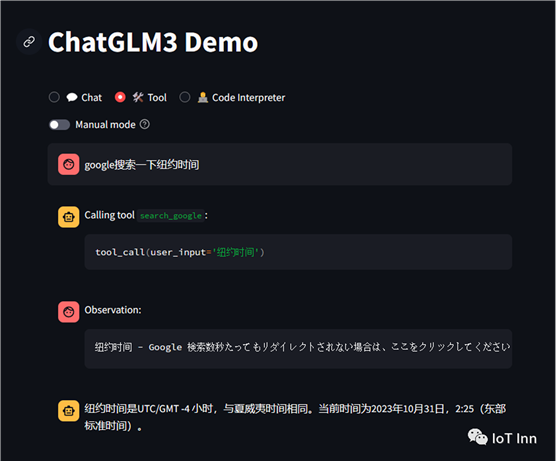
直接google后的结果

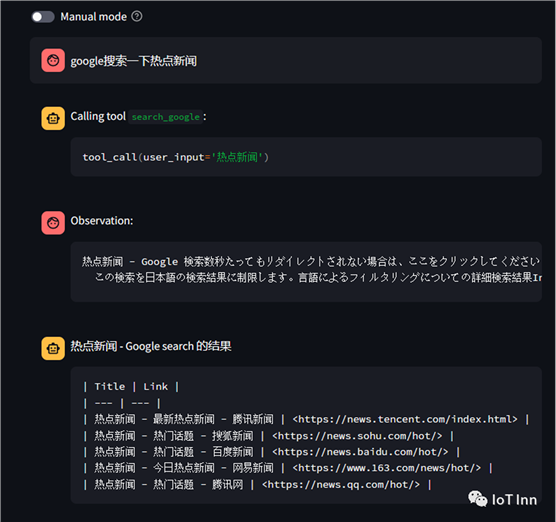
但是对于一些有登录限制,或者一些专门的网页就很难获取到信息了
出自:https://mp.weixin.qq.com/s/FAhPO_3hWOdOssssRmVFUQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip