我觉得去研究和实践基于LLM的应用更实际,而RAG就是非常好的一个方向,这对于很多企业来说是刚需。
我觉得去研究和实践基于LLM的应用更实际,而RAG就是非常好的一个方向,这对于很多企业来说是刚需。
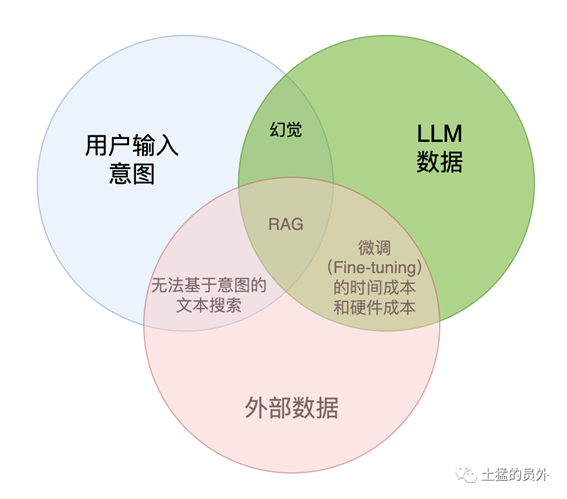
RAG是各方面综合之后的最优解
但是就像前面我说的,RAG入门很简单,但是要能让客户买单却很难,我已经看到好几个失败案例了...
下面我们来看看会有哪些方面会引起RAG的失败(下面的举例并不完全,还有一些本次来不及写了)。
1.分块(Chunking)策略和Top-k算法
一个成熟的RAG应该支持灵活的分块,并且可以添加一点重叠以防止信息丢失。一般来说,分块过程忽略了文本的内容,这就产生了问题。块的理想内容应该围绕单个主题保持一致,以便Embedding模型更好地工作。他们不应该从一个话题跳到另一个话题,他们不应该改变场景。比如长篇大论的论文和140字上限的微博内容的分析就会需要适配不同的分块策略,用固定的、不适合的分块策略会造成相关度下降。
除了chunk,我们需要考虑参数top_k的影响。RAG系统使用top_k来选择得分达到多少的文本chunk才能送到LLM里面进行生成(Gen)操作。在大多数设计中,top_k是一个固定的数字。因此,如果块大小太小或块中的信息不够密集,我们可能无法从向量数据库中提取所有必要的信息。
对于熟悉机器学习模型调优的人来说会对chunk_size和top_k非常敏感,为了确保RAG系统以最佳状态运行,需要对块大小和top_k进行调优,以确保它们是最合适的。机器学习里面参数调优的古老智慧仍然适用,唯一的区别是它们的调优成本更高。
2.世界知识缺失
考虑这样一个场景:我们正在构建一个《西游记》的问答系统。我们已经把所有的《西游记》的故事导入到一个向量数据库中。现在,我们问它:人有几个头?
最有可能的是,系统会回答3个,因为里面提到了哪吒有“三头六臂”,也有可能会说很多个,因为孙悟空在车迟国的时候砍了很多次头。而问题的关键是小说里面不会正儿八经地去描述人有多少个头,所以RAG的数据有可能会和真实世界知识脱离。
“今天的AI和机器学习真的很糟糕。人类有常识,而机器没有。”
——Yann LeCun
因此,当我们开发RAG系统时,不要让大语言模型已经知道解决方案的想法欺骗了您。他们没有。
3.多跳问题
让我们考虑另一个场景:我们建立了一个基于社交媒体的RAG系统。那么我们的问题是:谁知道埃隆·马斯克?然后,系统将遍历向量数据库,提取埃隆·马斯克的联系人列表。由于chunk大小和top_k的限制,我们可以预期列表是不完整的;然而,从功能上讲,它是有效的。
现在,如果我们重新思考这个问题:除了艾梅柏·希尔德,谁能把约翰尼·德普介绍给伊隆·马斯克?单次信息检索无法回答这类问题。这种类型的问题被称为多跳问答。解决这个问题的一个方法是:
1.
找回埃隆·马斯克的所有联系人
2.
找回约翰尼·德普的所有联系人
3.
看看这两个结果之间是否有交集,除了艾梅柏·希尔德
4.
如果有交集,返回结果,或者将埃隆·马斯克和约翰尼·德普的联系方式扩展到他们朋友的联系方式并再次检查。
有几种架构来适应这种复杂的算法,其中一个使用像ReACT这样复杂的prompt工程,另一个使用外部图形数据库来辅助推理。我们只需要知道这是RAG系统的限制之一。
4.信息丢失
如果我们看一下RAG系统中的流程链:
1.
将文本分块(chunking)并生成块(chunk)的Embedding
2.
通过语义相似度搜索检索数据块
3.
根据top-k块的文本生成响应
我们会看到所有的过程都是有信息损失的,这意味着不能保证所有的信息都能保存在结果中。如上所述,由于分块大小的选择和Embedding模型的效用,分块和Embedding是有损耗的;由于我们使用的top_k限制和相似度匹配函数,检索过程不可能完美;由于内容长度的限制和生成式大语言模型的能力,响应生成过程并不完善。
如果我们把所有的限制放在一起,重新考虑一些公司即将推出的基于RAG的企业搜索,我真的很好奇它们能比传统的全文搜索引擎好多少。记住,传统的搜索引擎是很难被击败的。不久前,微软E5是第一个超越流行搜索算法BM25的LLM。
我的意思是,搜索引擎和LLM的结合是可行的,然而,简单的RAG很难比搜索引擎表现得更好。
我们的一些突破
确实,RAG是很难的,我前面的文章就说过一些注意点,包括数据处理、内容提取、分块策略、embedding模型选择等等,可以参考之前的文章《大模型主流应用RAG的介绍——从架构到技术细节》。下面是这篇文章里面的截图:
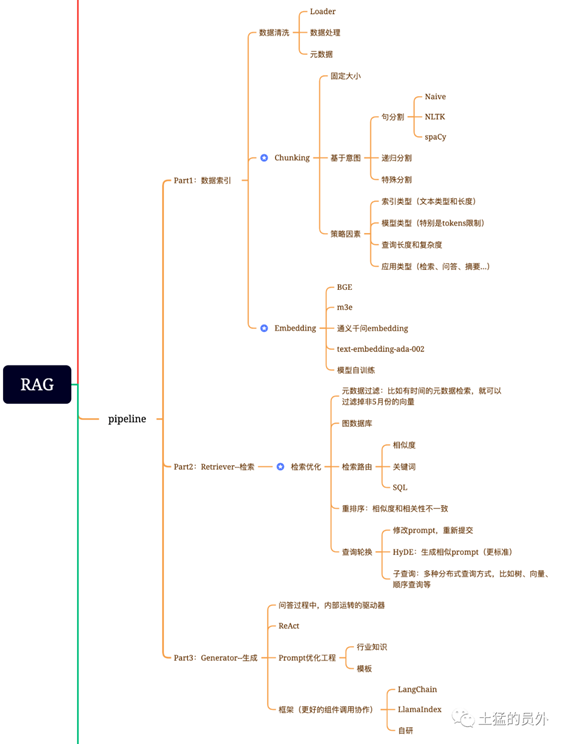
RAG应用中需要注意的关键点
最近我和小明对RAG做了一些广泛的测试,我在这里可以做一些简单的曝光。
a.通篇理解之后的检索生成
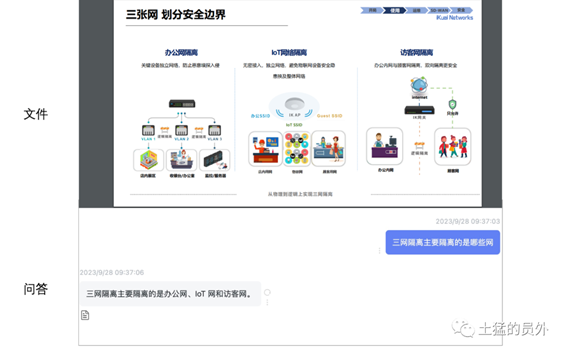
对于三网隔离的理解,原文中是需要多张PPT一起理解才能得到“三网融合”这个答案的,因为直接的答案这页PPT显示的是“三张网”。
b.多张PPT整合能力
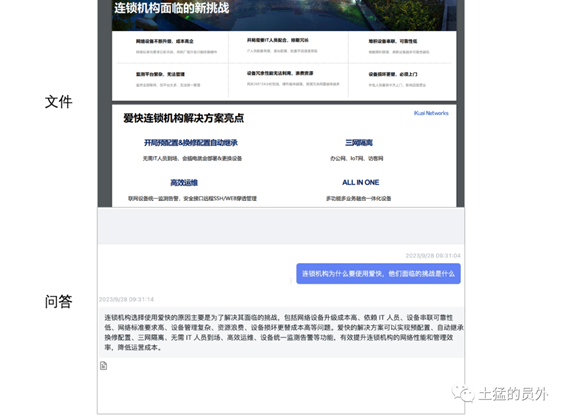
对于为什么要用(爱快的优势),和连锁机构面临的挑战其实是两个PPT中的内容,我们的RAG是可以自动进行理解与整合的。
结论
RAG作为一种简单而强大的LLM应用程序设计模式,有其优点和缺点。我们确实需要彻底了解该技术才能对我们的设计充满信心。我个人的看法是,尽管所有关于LLM和惊人突破的炒作,大语言模型应该被视为企业AI架构的重要组成部分。它们不应该是主要框架本身。
LLM有限的权力是我担心的一个问题,可解释性是另一个问题。所有的大语言模型都像黑匣子一样工作。人们不知道自己是如何储存知识的,也不知道自己是如何推理的。对于我们自己玩玩的应用程序来说这不是一个主要问题,但在企业应用中却很关键。我们可以看到,越来越多的监管规则被发布,以确保AI不会造成伤害,我们必须提高基于LLM的应用在自己的适配方向上实现真正的价值。
在未来的研究中,我将探索如何将LLM与其他外部知识库(如图形数据库)相结合,以实现更难以实现的目标。
出自:https://mp.weixin.qq.com/s/v487ps9RGujUFlM_dKDW4A
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip