为什么Sora可以引起如此大的关注?Sora生成的视频与此前其它平台生成的视频到底有哪些区别?有很多童鞋似乎对这些问题依然有疑问,本文将以通俗的语言解释Sora的独特之处。
OpenAI的Sora模型是最近两天最火热的模型。它生成的视频无论是清晰度、连贯性和时间上都有非常好的结果。在Sora之前,业界已经有了很多视频生成工具和平台。但为什么Sora可以引起如此大的关注?Sora生成的视频与此前其它平台生成的视频到底有哪些区别?有很多童鞋似乎对这些问题依然有疑问,本文将以通俗的语言解释Sora的独特之处。
- OpenAI Sora视频生成能力与其它平台和工具的对比表
- OpenAI的Sora视频生成的能力概览
- OpenAI Sora可以生成长达一分钟的视频
- OpenAI Sora可以生成更加自由尺寸的视频
- OpenAI Sora可以支持向前以及向后扩展视频
- OpenAI Sora支持多个视频的连接
- OpenAI Sora涌现出真实物理世界模拟的能力
- OpenAI Sora可以模拟人工过程
- OpenAI Sora的技术独特之处
- OpenAI Sora与Diffusion模型和Transformers模型的比较
- OpenAI Sora模型的缺点
OpenAI
Sora视频生成能力与其它平台和工具的对比表
在这里,我们先用一张表格来展示OpenAI Sora与其它视频生成工具(如Runway Gen2、Pika等)的区别。然后我们针对OpenAI Sora的特别之处进行详细解释。
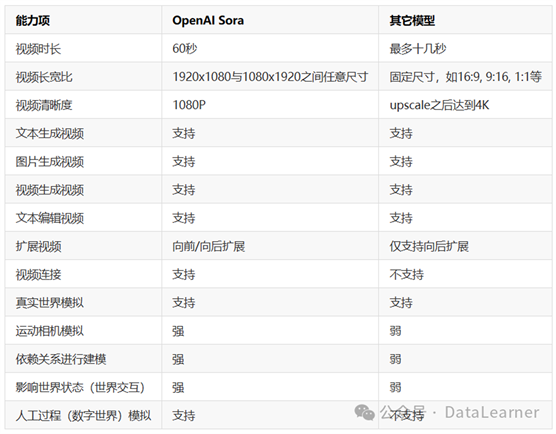
从这个表单可以看出,不论是基本的视频生成能力(时长、长宽比),还是更强的视频连续性、真实世界模拟等,OpenAI Sora都有无可比拟的优势。其中,视频清晰度,OpenAI
Sora默认是1080P,而且其它平台大多数默认的清晰度也都是1080P以下,只是在经过upscale等操作之后可以达到更清晰的水平。
上述视频生成能力项中,视频连接、数字世界模拟、影响世界状态(世界交互)、运动相机模拟等都是此前视频平台或者工具中较少提及的,下面我们也将详细解释。另外值得一提的是,OpenAI Sora模型还可以直接生成图片,也就是说,它是一个以视频生成为核心的多能力模型。
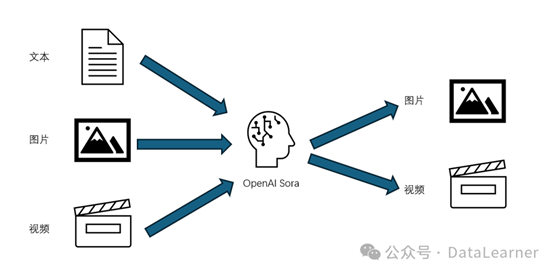
OpenAI的Sora视频生成的能力概览
首先,在详细描述Sora视频生成与Runway Gen2等平台的差异之前。我们先总结一下Sora视频生成的一些能力。
OpenAI
Sora可以生成长达一分钟的视频
在OpenAI发布Sora之前,业界基于大模型生成视频的主要平台有Pika、Runway Gen2等,但是这两个平台视频生成默认都是几秒中,即便通过视频扩展等手段,最多也只能生成十几秒的视频。而OpenAI的Sora可以生成最多1分钟的视频。并且视频生成的结果非常连贯和清晰。
OpenAI
Sora可以生成更加自由尺寸的视频
根据OpenAI的Sora技术报告,Sora模型可以采样宽屏1920x1080视频、竖屏1080x1920视频以及介于两者之间的所有尺寸视频。这意味着它可以生成更加自由的视频尺寸。而此前的视频平台,如Runway Gen2,文本生成视频的方式只能选择16:9, 9:16, 1:1,
4:3, 3:4, 以及 21:9的长宽比。至于清晰度,则默认1408 × 768px。

上图是生成海归游泳的视频,不同尺寸的视频里面海归都是正中间位置,不会出现主要目标被剪裁的情况。
OpenAI
Sora可以支持向前以及向后扩展视频
这是OpenAI Sora另一个与此前视频生成平台有巨大差异的地方。基于已有视频继续扩展在Runway
Gen2、Pika等平台都有。但是现有平台的视频扩展通常是在当前视频的基础上继续向前生成几秒的视频。但是,OpenAI Sora可以在视频的基础上向前或者向后扩展。例如给定一个视频,OpenAI
Sora可以为该视频创造不同的开头,最后都是以该视频结尾,过程非常连续。因此,Sora甚至可以在一个视频上同时向前和向后扩展,以产生一个无限连续的循环视频。
OpenAI
Sora支持多个视频的连接
这是另一个Sora与众不同的地方。给定两个视频,OpenAI Sora可以将这两个视频揉在一起,生成一个新的毫无违和感的视频。例如,给一个无人机穿越古罗马建筑的视频,再给一个蝴蝶在海底珊瑚飞行的视频,Sora可以生成一个新的视频,让无人机变成蝴蝶,古罗马建筑变成珊瑚风格。

上图是两个例子,左右两边是原来的2个视频,中间是基于这原有的2个视频连接后生成的新的视频。第一个就是刚才的蝴蝶与无人机的案例。第二个是圣诞节雪景和真实拍照的建筑视频的融合。
OpenAI
Sora涌现出真实物理世界模拟的能力
OpenAI
Sora可以生成更加真实的物理世界的视频。例如东京街头逛街的时尚女模、登山运动员等。但是,与其它平台的真实物理世界视频生成不同的是,OpenAI Sora可以以运动相机拍摄的方式来展示视频,包括运动相机的转换、旋转等。而这里最大的特点是运动相机拍摄的结果通常要与物理世界的三位空间一致,因此非常困难。但是Sora可以生成非常逼真的运动相机拍摄的视频结果。

此外,视频生成系统面临的一个重大挑战是在对长视频进行采样时保持时间一致性。OpenAI Sora经常(但并非总是)能够有效地对短距离和长距离依赖关系进行建模。例如,即使人、动物和物体被遮挡或离开画面,Sora模型也能保持它们的存在,在后续的视频中依然出现原有的人物或者动物。同样,它还能在单个样本中生成同一人物的多个镜头,并在整个视频中保持其外观。
同时,Sora有时可以模拟一些影响世界状态的简单动作。例如,画家可以在画布上留下新的笔触,并随着时间的推移而持续,或者一个人可以吃一个汉堡,并留下咬痕。


OpenAI
Sora可以模拟人工过程
除了真实的物理世界外,OpenAI Sora还可以模拟人类创造的一些世界或者过程。Sora模型可以通过理解语言提示来模拟和渲染视频游戏世界(如Minecraft)的高级能力。它不仅能够以高保真度同时渲染游戏环境和动态,还能控制游戏中的玩家角色,执行基本策略。这种能力表明Sora不仅具备强大的语言理解和任务推断能力,还能处理复杂的视觉和控制任务,尤其在视频游戏仿真领域表现出色。
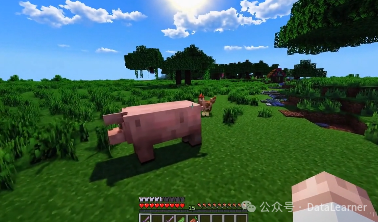
Sora模型的能力表明,继续扩大视频模型的规模是朝向开发能够高度仿真物理和数字世界及其中的对象、动物和人的高能力模拟器的有希望的路径。这种扩展不仅增强了模型处理复杂场景的能力,还提升了其对世界各种元素的理解和模拟能力,从而为创建更加智能和逼真的AI系统铺平了道路。
OpenAI
Sora的技术独特之处
尽管此次OpenAI一如既往地没有详细披露Sora模型的技术细节。但是也有一定的篇幅介绍了相关的技术。这里我们针对其中核心的几点来说明。
OpenAI
Sora是一种结合了Diffusion模型和Transformer模型的技术。通过将视频压缩网络将原始视频压缩到一个低维的潜在空间,并将这些表示分解为时空补丁,类似于Transformer的tokens,这样的表示使得模型能够有效地训练在不同分辨率、持续时间和宽高比的视频和图像上。
OpenAI
Sora与Diffusion模型和Transformers模型的比较
- 共同点:Sora模型利用了Diffusion模型的生成能力和Transformers模型的自注意力机制。它通过预测干净补丁的方式生成视觉内容,同时利用Transformers模型处理时空补丁的能力。
- 差异:
- 与Diffusion模型:Sora不仅仅是一个简单的Diffusion模型,它通过引入Transformers模型的自注意力机制和视频压缩技术,增强了处理不同分辨率和格式视频的能力。
- 与Transformers模型:Sora超越了传统Transformers模型的应用范围,通过将视觉数据转换为补丁并利用Diffusion过程生成视觉内容,它结合了两种模型的优势,实现了视频和图像的高效生成。
同时,OpenAI也强调了,这个模型在大量的数据上训练后就能提高视频生成的效果。下图展示了训练过程中模型水平的提升:
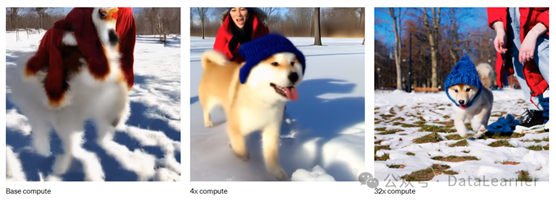
换个角度说,OpenAI Sora也是某种程度上大力出奇迹的一个成果。
OpenAI
Sora模型的缺点
除了上面描述的优点外,OpenAI Sora视频生成也有一些缺点。在模拟复杂场景的物理现象、理解特定因果关系、处理空间细节、以及准确描述随时间变化的事件方面OpenAI
Sora都存在 问题。主要总结如下:
1.
物理交互的不准确模拟:
Sora模型在模拟基本物理交互,如玻璃破碎等方面,不够精确。这可能是因为模型在训练数据中缺乏足够的这类物理事件的示例,或者模型无法充分学习和理解这些复杂物理过程的底层原理。
2.
对象状态变化的不正确:
在模拟如吃食物这类涉及对象状态显著变化的交互时,Sora可能无法始终正确反映出变化。这表明模型可能在理解和预测对象状态变化的动态过程方面存在局限。
3.
常见的模型失败模式:
o
长时视频样本的不连贯性:在生成长时间的视频样本时,Sora可能会产生不连贯的情节或细节,这可能是由于模型难以在长时间跨度内保持上下文的一致性。
o
对象的突然出现:视频中可能会出现对象的无缘无故出现,这表明模型在空间和时间连续性的理解上还有待提高。
这些失败的案例包括人在跑步机上朝着反方向跑步、长视频中突然出现之前不曾出现的物体、篮球在篮筐跳动的时候出现火苗等。这些都意味着在真实世界交互的模拟都有重大问题。
原文:https://mp.weixin.qq.com/s/Ab9nwadni_zIgUuRuSYbnQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip