Sora 的训练算力需求大概率是 GPT-4 的 1/4 左右。Sora 的推理算力需求是 GPT-4 的 1000 倍 以上(这么看来 2 万亿美元市值的 NVIDIA 仍然不是高点)。复现 Sora 的难度没有预想中的大,至少训练算力不是瓶颈; 国内靠 A800/H800 的余量仍可以满足。国产芯片迎来一次机会,设计并量产 14nm 的中算力、大显存 LLM 推理芯片,可以绕开芯片制程的瓶颈迅速商业化
1.Sora 的训练算力需求大概率是 GPT-4 的 1/4
左右
2.Sora 的推理算力需求是 GPT-4 的 1000 倍以上(这么看来 2 万亿美元市值的 NVIDIA 仍然不是高点)
3.复现 Sora 的难度没有预想中的大,至少训练算力不是瓶颈; 国内靠 A800/H800 的余量仍可以满足
4.国产芯片迎来一次机会,设计并量产 14nm 的中算力、大显存 LLM 推理芯片,可以绕开芯片制程的瓶颈迅速商业化
测算 GPT-4 的训练算力需求
首先估算 GPT-4 的算力需求, 根据 OpenAI 的 Paper:Scaling
Laws for Neural Language Models , 训练
Transformer 模型的理论计算量为FLOPs
≈ 6ND 。其中, N 为模型参数量大小, D 为训练数据量大小:

LLM
每 token 需要的计算量是 6 倍的模型大小
基于一些"众所周知"的消息:
- GPT-4 是一个 MoE 模型,其总参数量估计在 1.6T - 1.8T 之间,激活参数量估计在 400B - 600B 之间, GPT-4 的训练理论计算量需按照激活参数量而非总参数量来估计。 我们假设为
400B 激活。
- GPT-4 的训练数据约为 13T - 20T 之间,我们假设为 20T 数据
则 GPT-4 训练所需的 FLOPs = 6 * 400B * 20T = 4.8 * 10^25
目前最大的模型训练计算量预估在
10^25 - 10^26 之间
那么 GPT-4 需要训练多久呢?
GPT-4 是 2022 年上半年训练的,据说 OpenAI 使用了 25000 张 A100。 每张
A100 的理论算力是 312 TFLOPs。 假设 25k 的超大规模集群训练
所需通信量比 Dense 更高的 MoE 模型,OpenAI Infra 优化利用率 MFU 到 40% (无法 overlap 的通信和访存会大幅降低利用率),则可以推导出来训练所需的时间是:
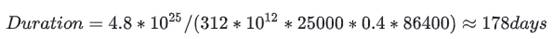 "="">Duration=4.8∗1025/(312∗1012∗25000∗0.4∗86400)≈178days" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-3-Frame">
"="">Duration=4.8∗1025/(312∗1012∗25000∗0.4∗86400)≈178days" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-3-Frame">
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip


 试着问问
试着问问