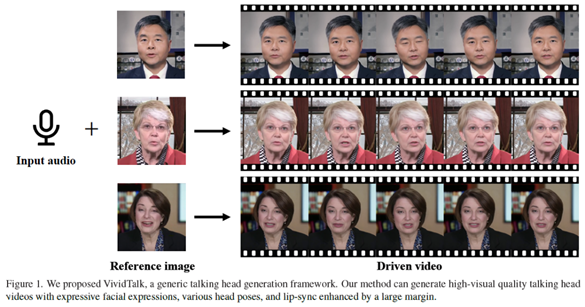
VividTalk由南京大学、阿里巴巴、字节跳动和南开大学联合发表。它通过先进的音频到3D网格映射技术和网格到视频的转换技术,实现了高质量、逼真的音频驱动的说话头像视频生成。只需提供一张人物的静态照片和一段语音录音,VividTalk即可制作出一个看起来像是实际说话的人物的视频。
“VividTalk:
One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior”
VividTalk由南京大学、阿里巴巴、字节跳动和南开大学联合发表。它通过先进的音频到3D网格映射技术和网格到视频的转换技术,实现了高质量、逼真的音频驱动的说话头像视频生成。只需提供一张人物的静态照片和一段语音录音,VividTalk即可制作出一个看起来像是实际说话的人物的视频。
多种角色
多种语言

方法对比

VividTalk不仅能够同步口型,还支持多种语言和不同的风格,包括真实风格和卡通风格等。VividTalk生成的视频看起来非常自然,应用范围广泛,可以用于虚拟助手、在线教育、娱乐内容制作等多个领域。

项目主页:https://humanaigc.github.io/vivid-talk/
论文地址:https://arxiv.org/pdf/2312.01841.pdf
Github地址:https://github.com/HumanAIGC/VividTalk
摘要
本文提出了一种名为VividTalk的语音驱动的人头生成框架,支持生成高质量的说话人视频,包括唇形同步、表情和头部姿态等特征。该框架采用两阶段的方法,第一阶段将音频映射到网格上,学习非刚性表情运动和刚性头部运动,第二阶段采用双分支运动VAE和生成器将网格转换为密集运动,并逐帧合成高质量视频。实验结果表明,VividTalk可以生成高质量的说话人视频,并在客观和主观比较中优于先前的最先进作品。
简介
一次性音频驱动的说话头生成旨在通过音频作为输入信号来驱动任意面部图像,并具有广泛的应用场景,如虚拟化身、视觉配音和视频会议。为了最大程度地增加生成视频的逼真度,需要考虑非刚性面部表情组件和刚性头部组件。
对于面部表情运动,大多数现有方法采用多阶段框架将音频特征映射到中间表示,如面部标志点和3DMM系数。然而,面部标志点过于稀疏,无法详细建模表情。相比之下,已经证明了3D面部可塑模型(3DMM)能够表示具有各种表情的面部。然而,我们观察到相同表情的混合形状在分布上存在显著差异,这加剧了音频和面部运动之间的一对多映射问题,并导致缺乏细粒度的运动。对于刚性头部运动,由于与音频之间的关系较弱,建模更加困难。一些方法利用视频提供头部姿势或在说话时保持头部静止。另一些方法直接从音频中学习头部姿势,但生成的结果不连续且不自然。到目前为止,如何从音频中生成合理的头部姿势仍然是一个具有挑战性的问题。
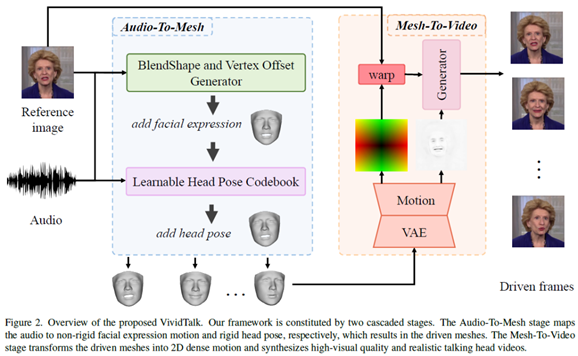
VividTalk是一个通用的一次性音频驱动的说话头部生成框架。该方法只需要一个参考面部图像和一个音频序列作为输入,然后生成一个具有表情和头部姿势的高质量说话头部视频。具体来说,该模型是一个两阶段的框架,包括音频到网格生成和网格到视频生成。在第一阶段,利用混合形状和3D顶点作为中间表示,混合形状提供粗略的运动,顶点偏移描述细粒度的嘴唇运动。此外,还采用了基于多分支变压器的网络,充分利用长期音频上下文来建模与中间表示的关系。为了更合理地从音频中学习刚性头部运动,将这个问题视为离散和有限空间中的代码查询任务,并建立一个可学习的头部姿势代码本,具有重构和映射机制。然后,将学习到的两个运动应用于参考身份,得到驱动网格。在第二阶段,基于驱动网格和参考图像,渲染内部面部和外部面部的投影纹理,以全面建模运动。然后设计了一种新颖的双分支运动vae来建模密集运动,将其作为输入馈送给生成器,以逐帧方式合成最终的视频。
广泛的实验证明,我们提出的VividTalk可以生成具有表情和自然头部姿势的口型同步说话头部视频。视觉结果和定量分析都表明了我们方法在生成质量和模型泛化性方面的优越性。
本文主要贡献如下:
·
我们提出了将长期音频上下文映射到混合形状和顶点上,以最大化模型的表示能力,并设计了一个精心设计的多分支生成器,分别建模全局和局部面部运动。
·
·
提出了一种新颖的可学习的头部姿势代码本,具有两阶段训练机制,以更合理地建模刚性头部运动。
·
·
实验证明,我们提出的VividTalk优于现有方法,支持高质量的说话头部视频生成,并可以在不同主题之间推广使用。
·
相关工作
音频驱动的说话头像生成旨在根据音频信号驱动面部图像。早期的研究尝试以端到端的方式生成视频。最近的一些研究采用了多阶段的框架,将音频映射到中间表示,如3DMM系数和面部关键点,以更好地建模运动。我们的方法使用混合形状和顶点作为中间表示,分别建模粗略运动和细粒度运动,以生成唇同步和逼真的说话头视频。
视频驱动的说话头像生成主要关注将源演员的动作转移到目标对象上,也被称为面部再现。方法通常分为两类:特定主体和通用主体。特定主体方法可以生成高质量的视频,但无法扩展到新的主体,这限制了它们的应用。最近,一些通用主体的方法尝试解决这个问题,并取得了巨大的成功。与上述方法相比,我们的任务更具挑战性,因为我们需要以音频作为输入来驱动图像,而没有任何运动先验知识。
方法
本文介绍了一种方法,可以根据音频序列和参考面部图像生成具有多样化面部表情和自然头部姿势的说话头像视频。该方法由两个级联阶段组成,分别是音频到网格生成和网格到视频生成。文章还介绍了3D可塑模型和数据预处理的基础知识,并描述了总体框架的训练策略。
预备知识
3D变形模型。我们的方法使用基于3d的(混合形状和顶点)而不是基于2d的信息作为说话头生成的中间表示。在3DMM中,三维脸型可以表示为:
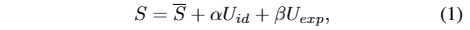
数据预处理。我们的模型只需要使用视听同步数据集进行训练。并进行预处理。
音频到网格生成
我们的目标是根据输入音频序列和参考面部图像生成3d驱动网格。我们首先利用FaceVerse重建参考面部图像。接下来,我们从音频中学习非刚性面部表情运动和刚性头部运动来驱动重构网格。为此,提出了一个多分支BlendShape和顶点偏移生成器以及一个可学习的头部姿态码本。
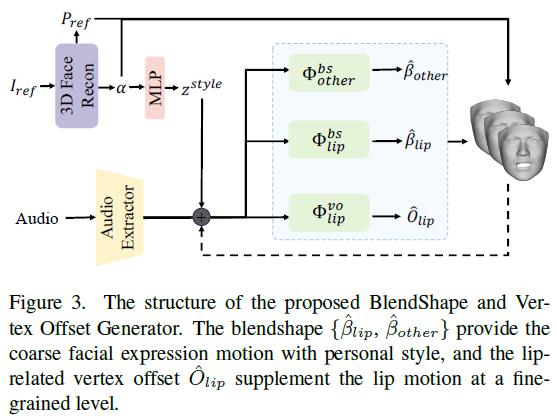
BlendShape和顶点偏移生成器。学习一个通用的模型来生成准确的嘴部运动和具有特定风格的面部表情,这在两个方面具有挑战性:1)第一个挑战是音频-动作相关问题。由于音频信号与口腔运动最相关,因此很难从音频中模拟非口腔运动;2)从音频到面部表情运动的映射自然具有一对多的属性,这意味着相同的音频输入可能有多个正确的运动模式,导致没有个人特征的mean face现象。为了解决音频-运动相关问题,我们使用混合形状和顶点偏移作为中间表示,其中混合形状提供了全局的粗面部表情运动,唇相关顶点偏移提供了局部的细粒度嘴唇运动。对于平均脸问题,我们提出了一种基于多支路变压器的生成器来单独建模每个部分的运动,并注入特定主题的风格以保持个人特征。
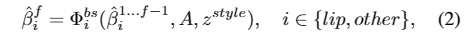
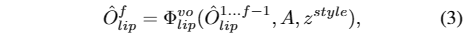
我们使用预训练的音频提取器来提取上下文化的语音表示。为了表示个人特定的风格特征,使用预训练的3D人脸重建模型从参考图像中提取身份信息α,并将其编码为风格嵌入z风格。然后,将音频特征A和嵌入个人风格的z风格添加并馈送到基于多分支Transformer的体系结构中,其中两个分支生成混合形状,在粗粒度上建模面部表情运动,第三个分支生成唇部相关的顶点偏移,在细粒度上补充唇部运动。请注意,为了更好地建模时间依赖性,在预测当前运动时,将学习到的过去运动作为网络的输入,可以表示为:
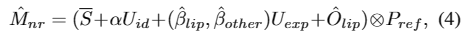
训练完成后,可以得到具有非刚性面部表情运动的驱动网格。
可学习的头部姿势码本。头部姿势是影响视频真实性的另一个重要因素。但是,直接从音频中学习并不容易,因为它们之间的关系很弱,会导致不合理和不连续的结果。我们提出将该问题作为一个离散且有限的头姿空间中的代码查询任务,并精心设计了两阶段的训练机制,第一阶段构建丰富的头姿码本,第二阶段将输入音频映射到码本以生成最终结果,如图4所示。
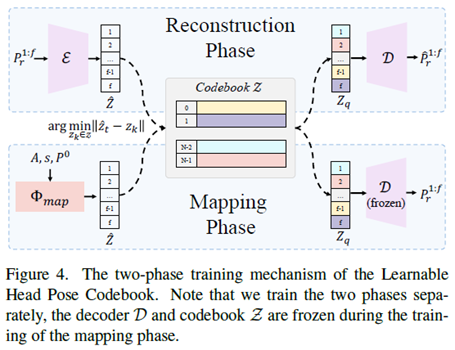
在重建阶段,任务是构建一个上下文头部姿态码本和能够从Z解码真实头部姿态序列的解码器。我们采用由编码器、解码器和码本组成的VQ-VAE作为主干。首先,计算相对头部位姿,并将其编码为潜码。然后,我们使用一个元素量化函数q(·)来得到zq,将Z´中的每一项Z´映射到它最近的码本条目Z k:
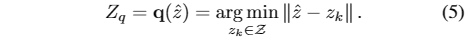
最后,基于Z q,由解码器D给出重构的相对头部位姿P * r 1:f,如下所示:
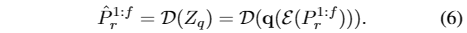
在映射阶段,我们专注于构建一个网络,该网络可以将音频映射到前一阶段学习的码本,以生成自然和连续的头部姿势序列。为了更好地模拟时间连续性,提出了一种基于自注意和跨模态多头注意机制的变压器自回归模型Φ map。具体来说,Φ map以音频序列A、个人风格嵌入z风格和初始头姿P 0为输入,输出中间特征z -,从码本z量化为z - q,然后由预训练的解码器D解码:
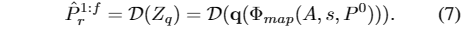
注意,码本Z和解码器D在映射训练阶段被冻结。
到目前为止,非刚性的面部表情动作和刚性的头部姿势都已经学会了。现在,我们可以通过将学习到的头部刚体位姿应用到M´nr网格上,得到最终的驱动网格M´d:
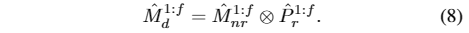
网格到视频生成
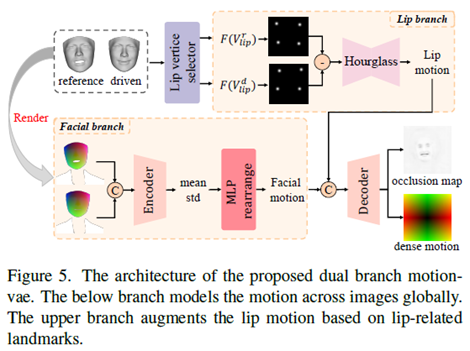
我们提出了一个双分支运动vae来模拟二维密集运动,并将其作为生成器的输入来合成最终的视频。
将三维区域运动直接转换为二维区域运动是困难和低效的,因为网络需要寻找两个区域运动之间的对应关系才能更好地建模。为了减少网络的学习负担并获得进一步的性能,我们借助投影纹理表示在二维域中进行这种转换。
为了渲染3D网格的投影纹理,我们首先将3D人脸的平均形状在x、y、z轴上归一化为0−1,得到类似于RGB的三个通道的归一化坐标码NCC,可以看作是人脸纹理的一种新的表示:
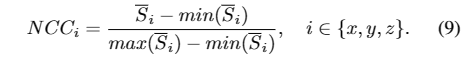
然后采用Z-Buffer对投影的三维内表面纹理PT进行NCC上色渲染。然而,由于3DMM的限制,不能很好地对外表面区域进行建模。为了更好地对跨帧运动建模,我们使用对图像进行解析,得到外脸区域纹理PT out,如躯干和背景,将其与PT in结合如下:

如图5所示,在面部分支中,参考投影纹理PT ref和驱动投影纹理PT d被连接并馈入Encoder,随后是MLP,后者输出2D面部运动图。为了进一步增强嘴唇运动和更准确地建模,我们还选择了与嘴唇相关的地标并将其转换为高斯图,这是一种更紧凑和有效的表示。然后,沙漏网络将高斯图的减除作为输入,输出一个二维的唇形运动,该唇形运动将与面部运动连接并解码为密集运动和遮挡图。
最后,我们根据之前预测的密集运动图对参考图像进行变形,得到变形后的图像,并将变形后的图像作为与遮挡图一起的生成器的输入,逐帧合成最终的视频。
训练策略
训练分为两个阶段:音频到网格和网格到视频。训练过程中,BlendShape和Vertex Offset
Generator受到重建损失的监督。
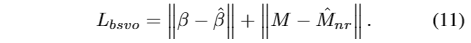
在Learnable Head Pose Codebook的训练中,使用了直通梯度估计器。
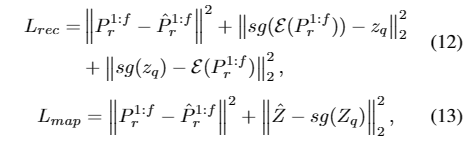
在网格到视频阶段,使用了基于预训练VGG-19网络的感知损失和特征匹配损失。
实验
数据集和评估指标
数据集。使用HDTF和VoxCeleb数据集进行模型训练。HDTF数据集包含346个主题的超过16小时的高分辨率音频-视觉数据,而VoxCeleb数据集包含超过100,000个视频和1,000个身份。首先,对这两个数据集进行筛选,去除无效数据,例如音频和视频不同步的数据。然后,根据文献[18],使用面部特征点检测器裁剪视频中的面部区域,并将其调整为256×256的大小。最后,将处理后的视频划分为80%用于训练,10%用于验证,10%用于测试。
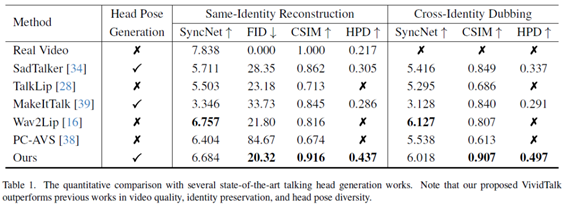
评估指标。使用SyncNet分数来衡量唇部同步质量,这是头像应用中最重要的指标。为了评估结果的真实性和身份保留性,计算参考图像和生成帧之间的Frechet Inception距离(FID)和余弦相似度(CSIM)。此外,计算生成的头部姿势(旋转和平移)的标准差,以更好地评估头部姿势的多样性(HPD)。
实现细节
使用FaceVerse作为重建方法,训练过程中分别训练音频到网格和网格到视频两个阶段,优化器使用Adam,总训练时间为2天,详细信息可参考补充材料。
与SOTA方法比较
我们与SadTalker、TalkLip、MakeItTalk、Wav2Lip和PCAVS等方法进行比较。
定性比较。SadTalker无法生成精确的细粒度唇动,视频质量不如我们。TalkLip产生模糊的结果,将皮肤颜色风格改为微黄色,在一定程度上丢失了身份信息。MakeItTalk不能生成准确的嘴型,特别是在Cross-Identity
Dubbing设置下。Wav2Lip倾向于合成模糊的嘴部区域,在输入单个参考图像时输出静态头部姿态和眼球运动的视频。PC-AVS需要驱动视频作为输入,并努力保持身份。相比之下,我们提出的方法可以生成高质量的说话头部视频,具有准确的嘴唇同步和富有表现力的面部运动。

定量比较。我们的方法在图像质量和身份保持方面表现更好,这反映在较低的FID和较高的CSIM指标上。我们的方法生成的头部姿态也更加多样和自然。虽然我们方法的SyncNet得分不如Wav2Lip,但我们的方法可以用单个音频代替视频驱动参考图像,生成更高质量的帧。
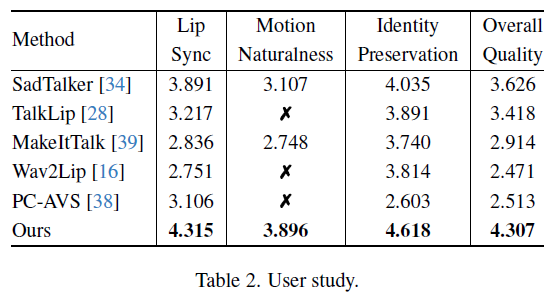
用户评估
通过对比实验,本方法在唇形同步、动作自然度、身份保留和整体质量等方面均优于之前的方法。研究者还进行了用户评估,结果表明该方法的表现更好。
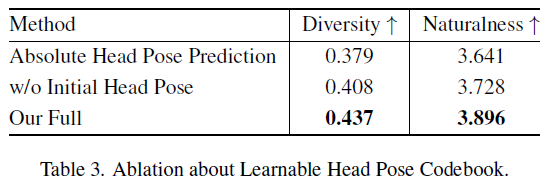
消融分析
中间表征。通过消融实验验证了使用混合形状和顶点偏移作为中间表示的优越性,混合形状可以很好地建模面部表情运动,但不能很好地建模嘴唇运动,而顶点偏移可以更好地建模嘴形,但会在牙齿区域产生伪影,使用两者的方法可以生成准确细致的运动并保持高质量的视频。

头部姿势码本。验证了可学习的头部姿势码本的设计有效性,学习绝对头部姿势导致多样性降低,去除初始头部姿势会导致不自然的视觉效果,而我们的完整方法在评估指标上表现更好,证明了我们设计的优势。
双分支Motion-VAE。通过消融实验评估了双分支Motion-VAE在Mesh-ToVideo阶段的唇同步和视频质量,去除唇运动分支无法准确建模嘴形并在牙齿区域生成伪影,而双分支模型可以通过唇分支的增强很好地合成结果。

总结
VividTalk是一个支持生成高质量的说话头像视频的框架。它使用混合形状和顶点作为中间表示来最大化模型的表达能力,并设计了一个多分支生成器来分别建模全局和局部的面部动作。对于刚性头部动作,提出了一个新颖的可学习头部姿势码本,并使用两阶段训练机制来合成自然的结果。通过双分支运动VAE和生成器,驱动网格可以很好地转换为密集的运动,并用于合成最终的视频。实验证明我们的方法优于先前的最先进方法,并在许多应用中开辟了新的道路,如数字人类创作、视频会议等。
▌关于我们
灵度智能,我们致力于提供优质的AI服务,涵盖人工智能、数据分析、机器学习、深度学习、强化学习、计算机视觉、自然语言处理、语音处理等领域。提供AI课程、AI算法代做、论文复现、远程调试等服务。如有相关需求,请私信与我们联系。
我们的愿景通过创新创意和智能技术为客户提供卓越的解决方案,助力产业升级和数字化转型。我们的产品和服务将引领行业标准,创造卓越的用户体验。我们的团队致力于创造更智能、更便捷和更高效的生活方式,推动社会进步,致力于创造更美好的未来。
出自:https://mp.weixin.qq.com/s/QpTekLGb_xn_IJpC_ELiSA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip