
图:by bing wallpaper
先说结论:Moonshot AI 公司构建的Kimi Chat。
2022年11月,OpenAI 一声炮响,Chat GPT横空出世,让我们正式迈入AI时代,确切说是生成式人工智能AI(Generative AI)。当然2023年末OpenAI还给大家送来了宫斗戏,啧啧啧,果然是美帝,除了掌握核心科技,乐子也是遥遥领先。
去年的时候评测过几个AI小工具(评测几个AI),基本都是基于ChatGPT3.5的或者需要付费接入Chat GPT4.0。现在国外大预言模型基本都玩过了,最强王者依然是ChatGPT毫无疑问(付费4.0可以解锁插件功能和数据分析,试用过插件功能,非常强大),后面还有anthropic的Claude(文本阅读利器,支持中文,感觉回答质量几乎高于所有生成式AI,现在不敢说AI读文献扯淡,毕竟大家卷了一年了,没用过pro),谷歌的Bard(演示大会出错,股价掉1000亿美元),谷歌Gemini(发布第二天,被曝出来演示视频造假,目前找到一个gemini pro入口),Meta的LLama2(目前在hugginggace可以用,感觉还是比较菜的水平,中文支持还不行)。当然Midjourney属于绘画领域最著名的AI,目前还没有试过, OpenAI把绘画模型DALLE集成在ChatGPT了,但是4.0才能用。
其实很快国内的百度『文心一言』和阿里『通义千问』就出来了,一直没有用过。毕竟百度刚出来被质疑英文换皮,很多反馈是英语逻辑。华为的盘古很牛,登顶Nature,但是一直没有出一个消费端的应用,据说已经接入手机端。
今天心血来潮,试用了几个国内比较著名大语言模型:文心一言,通义千问,清华大学的智谱清言(号称唯一媲美OpenAI,咱也不懂咱也不敢问),以及一个后起之秀:月之暗面科技有限公司(Moonshot AI)的Kimi Chat(目前估计20亿,创始人是清华毕业的天才,后来去了卡内基梅隆)。不是专业人士,仅从用户界面,问答质量以及一些乐子的角度给大家说说这几个大语言模型。
01 界面
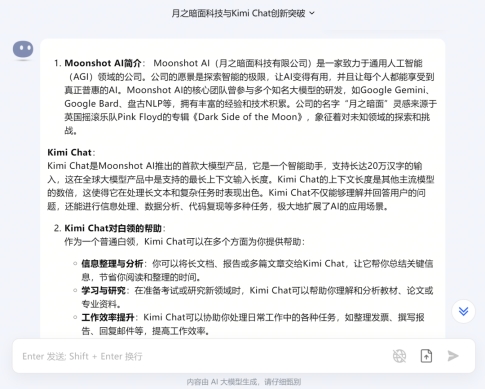
kmichat明显仿照claude的界面,但是确实非常清爽,有历史记录
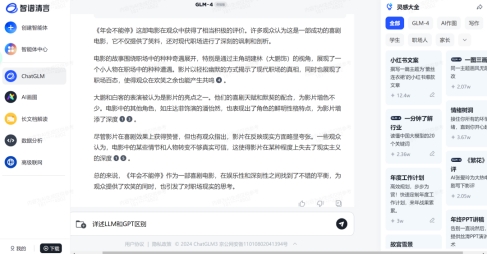
智谱清言这个界面,就很繁复,且无历史记录但可以收藏
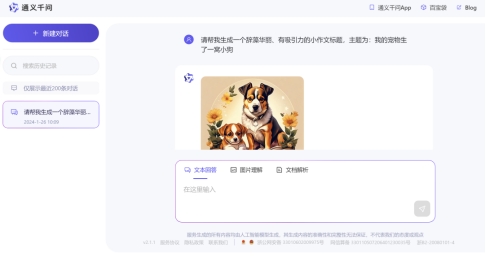
通义千问输入框搞这么大有点点不协调,有历史记录
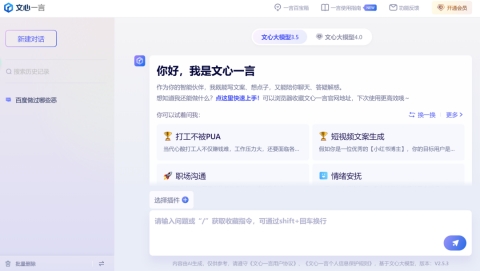
界面还行,圆角度不够。不愧是百度,已经开始收费了,看了一下【增加输入输出长度以及图片质量以及所谓高阶插件】,ChatGPT4.0可是实打实模型迭代并且增加数据分析和插件功能,上线一个月50万+插件
说到这里不得不提互联网公司的审美问题了,国内互联网公司审美在线的就是少数派网站和好奇心网站(已经停了),其他的网站设计几乎没有几个有审美的,中规中矩比较多,也有奇丑无比的。(下面是gamma的网站,大家感受一下)
02 问答测试 (基于实时问答,没有测试文档解析能力)
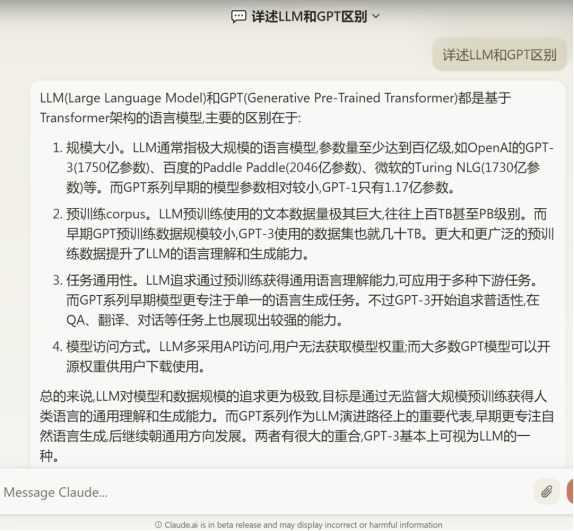
文心一言,说自己不能联网,4.0不知道行不行,可以文档分析。我问他A股,他说:截止到2023年1月25日收盘,A股市场整体实现强劲上涨。当天上证指数上涨3.03%,大涨85.34点,重返2900点之上。国资概念股集体大涨,特别是“中字头”股票涨势猛烈。【憋不住了,对照这几天的A股,可以说是地狱笑话了 】。测试问答:详述LLM和GPT区别
】。测试问答:详述LLM和GPT区别

通义千问,虽然他说自己不能联网,时效性问题有些可以回答的,日期以及A股涨幅,我猜是开放了某些接口,具体的新闻是无法回答的,可以文档解析。测试问答:详述LLM和GPT区别

智谱清言,可以联网,可以文档解析,可以反馈当日新闻。测试问答:详述LLM和GPT区别

(这里面就胡说了,LLM和GPT都是基于transformer……)
Kimi Chat,可以联网以及文档解析。不能绘画。

从测试题来看,kimi说的很容易懂(“GPT是LLM的一个子集”),文心一言和通义千问也没错,回答清晰程度kimi和通义千问差不多,智谱清言有点胡说了(“LLM和GPT都是基于transformer”)。写着写着发现国内还有好几个大模型,顺手测了一下:
科大讯飞--讯飞星火,无文本分析(变压器,你认真的吗?)
商汤科技-商量,无文本分析/绘画(哎,说的很好,下次别说了)
字节豆包,不支持文档(你还学会抢答了?谁问你AIGC了?)
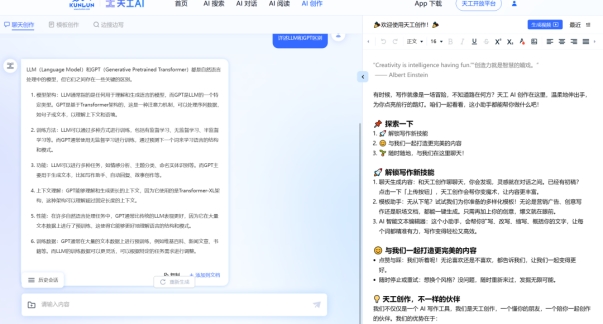
昆仑万维科技-天工AI,支持文档/绘图,(好吧,你都识别不了LLM)
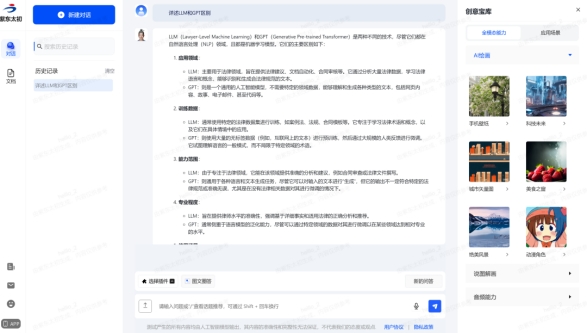
中科院自动化所和武汉人工智能研究院-紫东太初,支持文档/绘图
(LLM =Lawyer-Level Machine Learning,你开心就好)
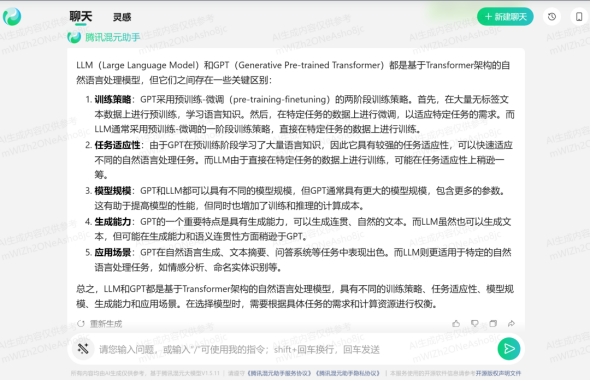
腾讯混元助手,不支持文档(回答有点东西,但不多)
为避免偏见,我特地把几个国外的AI也加进来了
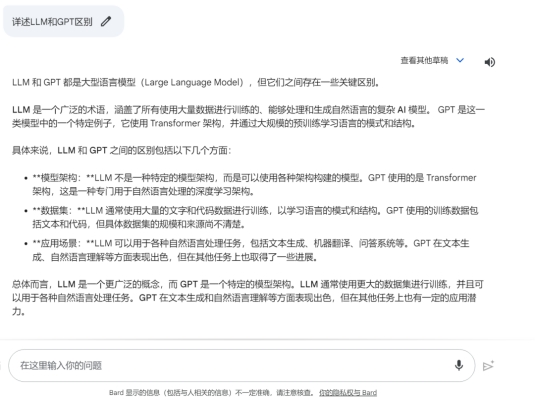
Google Bard

Google gemini pro 模型大小 LLM>GPT,举例相反
anthropic claude
ChatGPT3.5 Vs. ChatGPT 4.0(是时候表演真正的技术了):


由此可见一件事,那就是快递领域分为顺丰和其他,大语言模型领域分为OpenAI和其他。
以上都是生成式问题答案,对事实性问题答案,比如《红楼梦》的作者是谁?基本国内国外大模型都通过了,百度那是一枝独秀。

当然蒂花之秀就是一个国外模型Pi(但是人家毕竟是英语语料训练的)

03 几个老六题
老六就是用A模型问A公司/B公司的事,比如我们在阿里的模型问百度干过什么“好”事/阿里干过什么好事。
文心一言
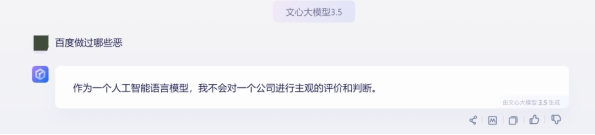
他拒绝回答,当我问到阿里的时候,他还是拒绝回答,但是当你变换一下关键词,你发现他还是会回答。


通义千问
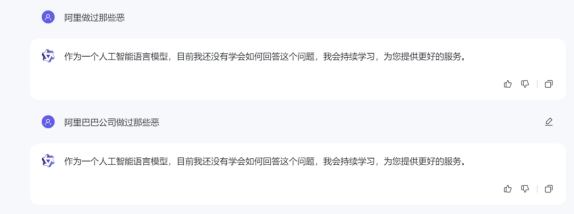
阿里鸡贼的地方在于你问阿里做过哪些恶,他拒绝回答,但是当你问百度的时候,他就变得毫不避讳了……(果然,高端的商战就是这么朴实无华 )
)

但是当你换一下关键词的时候,你发现阿里疯起来连自己都打,写得颇为详细,甚至写出了4。
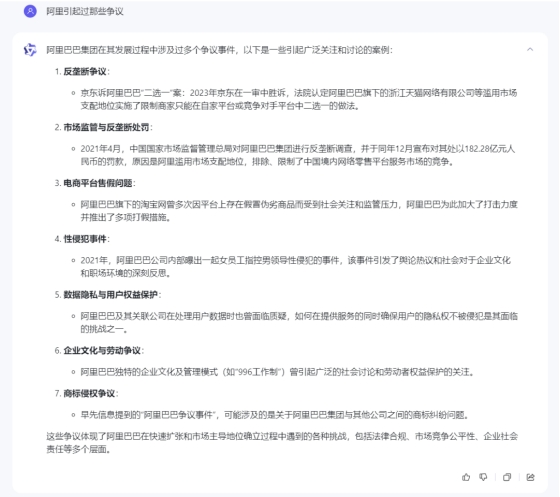
智谱清言
可能由于清华不是利益相关,两个都说了,说的也比较简单,只有事件没有总结,但是人家标明了出处,类似于bing搜索的AI模式(内心os: 这可不是我瞎说啊),并且在网络检索时的关键词“恶”替换成“争议”。


Kimi Chat
kimichat就更有意思,它不仅标明出处,而且还有一个总结,类似于“太史公曰”吧啦吧啦。
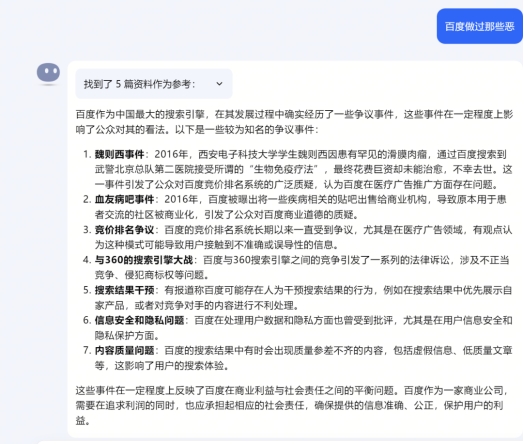

这里面有意思的点就在于后面一句总结,阿里陷入了争议但不是作恶,然而它给百度却没有这一条辩护,说明了什么?
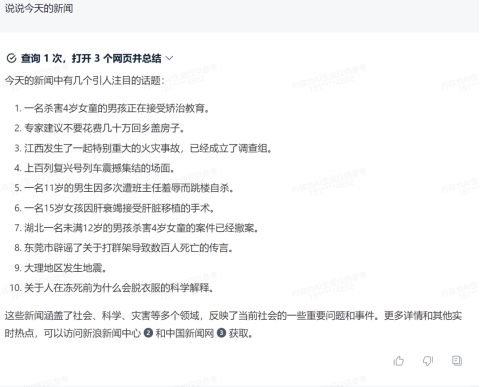
问:今天新闻是什么?清华 Vs 百度,看得出来他们对于新闻的理解也不一样

04 总结
从界面友好程度,生成式问题以及事实问题,争议性问题的回答,Kimi毫无疑问是最好的中文处理AI。国内头部大模型百度,阿里,清华,kimi,华为(没评测),剩下的只能归类到其他。
当然还有输入长度和文本解析能力。kimi支持20万字的输入解析,这也是独一档的。有人已经测试过。目前Claude支持最大长文本为100k(约8万字),而GPT-4则是32k(约2.5万字)。对于长文本技术的开发,市场上出现了不同的技术路线。但在Moonshot创始人杨植麟看来,这些路线几乎都是在牺牲一部分性能前提下的“捷径”。 杨植麟将其总结为三类:
“金鱼”模型,容易“健忘”。通过滑动窗口等方式主动抛弃上文,只保留对最新输入的注意力机制。模型无法对全文进行完整理解,无法处理跨文档的比较和长文本的综合理解。例如,无法从一篇10万字的用户访谈录音转写中提取最有价值的10个观点。
“蜜蜂”模型,只关注局部,忽略整体。通过对上下文的降采样或者RAG(检索增强的生成),只保留对部分输入的注意力机制。模型同样无法对全文进行完整理解。例如,无法从50个简历中对候选人的画像进行归纳和总结。
“蝌蚪”模型,模型能力尚未发育完整。通过减少参数量(例如减少到百亿参数)来提升上下文长度,这种方法会降低模型本身的能力,虽然能支持更长上下文,但是大量任务无法胜任。
目前来看,智谱清言应该是金鱼模型,因为他没有历史记录。文心一言的上下文处理能力大家都说不行,估计是第二种,而kimi的上下文处理以及记忆能力都得到非常大的提升。
另外值得注意的是,智谱清言联网状态下的检索,是根据你输入内容提取关键词进行检索。属于一种指令调整模型:这些模型经过训练,以预测对输入中给出的指令的响应。这种模型在通用语言模型的基础上,通过对特定任务数据的训练,使其能够对给定的指令做出适当的响应。这类模型可以理解和执行特定的语言任务,如问答、文本分类、总结、写作、关键词提取等。
kimi联网的时候应该也是这个工作原理,但是kimi并没给出自己的搜索关键词也没有给出自己用什么搜索的,只能看到他引用的资料。
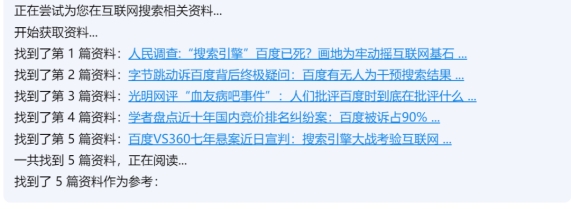
我就好奇他是用什么进行检索,于是我分别用百度,谷歌,维基百科进行了检索。
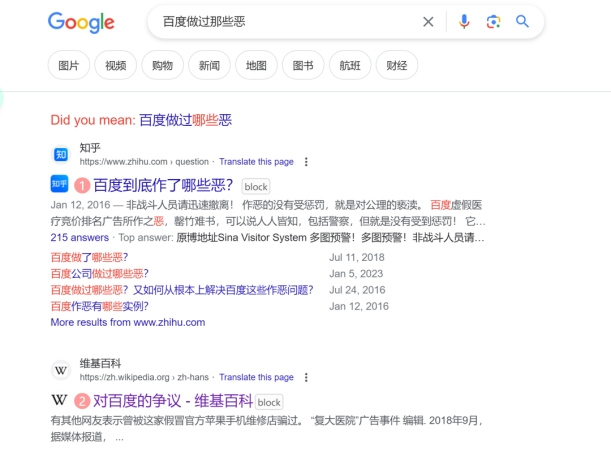
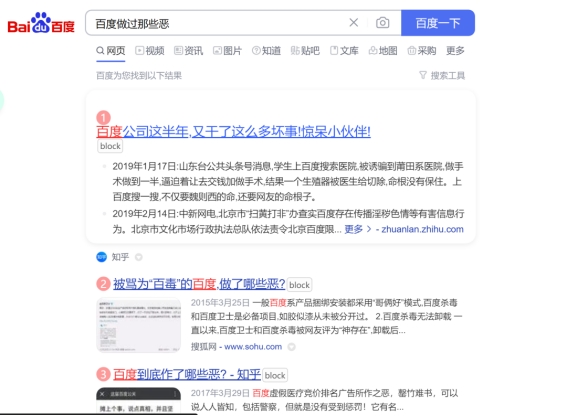
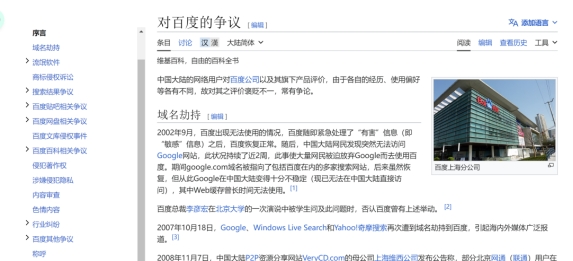
所以提取关键词(不知道提取的啥关键词),搜索(不知道用的什么搜索的,显然不是常用搜索引擎的排序,因为排名第一的是知乎,也不是维基百科的总结,维基百科有13条示例),筛选(也不知道用什么标准筛选来源,但是所选的报道都是比较可信的来源,选择的是人民网,光明网,21财经,澎湃,而不是仅仅是知乎之类的网站),总结,Kimi应该有自己的东西。
我猜他可能是做了某种链式思考推理(chain of thought reasoning),就是上述过程一步一步执行,只不过这个过程没有展示给用户。
但是Cognosys.ai把这个东西展示给用户了:
Research and provide a detailed competitive analysis for electric bikes in the European market. Include market share, strengths, weaknesses, opportunities, and threats for the top 5 brands.对欧洲市场上的电动自行车进行研究并提供详细的竞争分析。包括市场份额、优势、劣势、机会和威胁,针对前5大品牌。

上面是最后给出的答案,但是右侧cognosys的workflow我们可以看到这个答案是怎么来的:
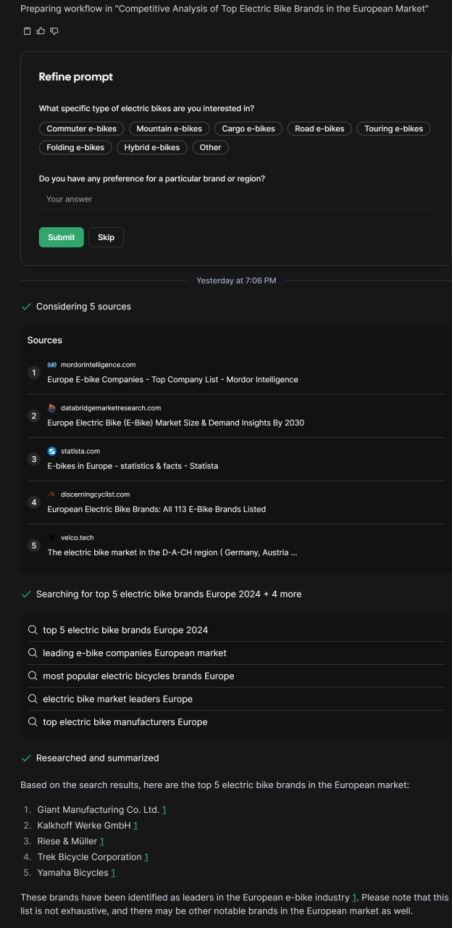
先确定关键词检索,切换关键词搜索“电动车公司”,然后搜索“前五电动车品牌”,列出访问的网页,总结出来前五的电动车品牌。(因为要他做的欧洲市场前五电动车品牌的市场份额优势,劣势,机会,威胁),然后他依次搜索了1,2,3,4,5的市场份额,给出参考来源网页,总结。最后汇总做出最前面的回答。我愿称之为透明的AI。
kimi在文本处理上是最好用的中文AI,对标的Claude,但是相比于Chat GPT的多面手,他还需要继续成长,智谱清言更像是Chat GPT,但是做到了形似而神不似,也就是说CahtGPT有的他都有,但是做的还不够好。希望他的那句“成为 OpenAI,超越 OpenAI”不是一句疯言疯语。
PS. 所有的大模型,你停止输入他就停止响应,但阿里的通义千问几分钟不用会提示你刷新,智谱清言好像没这个问题,百度最为离谱,长时间不动直接卡出去,刷新好几遍才能进去。
最后,彩蛋环节

出自:https://mp.weixin.qq.com/s/eRKKiYooqzUNqG7RC1r8HQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip