文章描述了一个免费的“订单”任务,即帮助一个由7名女生组成的小团队将生活照转换为动漫风格,以便在演讲中更具吸引力。作者使用AI技术完成了这项任务,包括使用Face ID插件和comfyUI界面,解决了显存不足的问题。作者详细描述了Face ID插件的安装和工作流配置过程,并通过与团队成员的沟通,逐一生成了满意的动漫风格照片。最终,这些照片被团队成员用PS合成并展示在大屏幕上,效果惊艳。虽然这不是最优解,但作者认为逐张生成的方式是一个可行的解决方案。

这几天接了一个“订单”,之所以加引号,是因为免费的。
因为公司布局调整,我带过的一个小团队前两年解散了。
不过优秀的成员们在其他部门依然成绩斐然。
最近她们(7个女生)的一个项目获奖,为了上台演讲的时候更加有吸引力,她们求助我把生活照用AI做成动漫效果。
这个任务说复杂并不复杂,习惯用AI的,完全可以找个动漫大模型用图生图转换一下。
但是,注意这里有个但是。
但是让小姐姐们满意不容易。
她们最终要呈现在大屏幕上七人组合的照片,要求纯白背景,简单的白色T恤、牛仔裤。
我一开始设想找一张七人图,然后用ControlNet提取姿势,再图生图生成七人合影。
不过我的显存只有12G(3060),合影需要很大的画幅,跑起来非常慢甚至可能爆显存。
于是我决定化繁为简,跑7张纯白背景的图,然后让小姐姐们在PS里合成。团队里有三个学设计的研究生,后期处理轻而易举。
为了保持画面的一致性以及参数的稳定,我选择了comfyUI(近期已经全面拥抱comfyUI,很少使用WebUI了)界面。
为了捕捉小姐姐们的面部,我选择了Face ID插件。
一、简要复习下Face ID插件的安装
1、安装IPAdapter节点
点击管理器,搜索IPAdapter
安装ComfyUI_IPAdapter_plus节点。
安装后重启启动器。
如果是先装节点,后安装模型,会出现重启后报错的情况,不过不要紧,按照上文的顺序把这些模型装一遍就好了。
2、安装IPAdapter模型
Face ID依托IPAdapter实现,IPAdapter已经发布了SD1.5和SDXL下的十几个模型,建议统统下载备用。
(1)Image Encoder(编码器)
需要下载安装两个基础的编码器模型,需要注意的是,在huggingface,这两个模型文件名一样的,建议下载后重命名为SD15和SDXL。
如果从我提供的网盘下载,就不需要重命名了,我已整理好。
不过,两个模型的应用范围并不是那么严格,和大模型的图片大小有关。SDXL模型只能用于SDXL,但SD15模型也可以用于一部分SDXL模型。
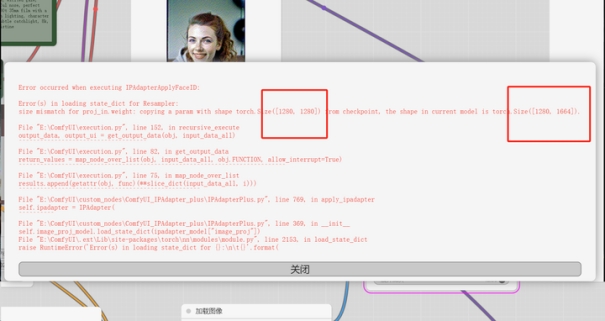
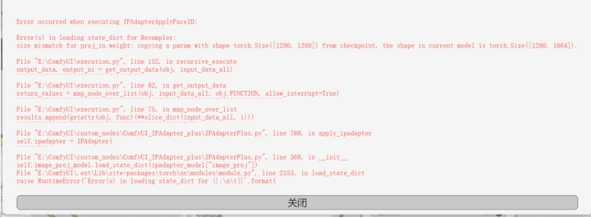
当你使用SDXL模型遇到类似尺寸不符的提示时,就可以更换为SD15模型。
编码器两个模型拷贝至:
ComfyUI\models\clip_vision
如果没有该目录,需要手工创建。
(2)IPAdapter常见模型
我从huggingface下载了21个模型,均已打包放在网盘。
https://www.123pan.com/s/ueDeVv-PJuI.html
3、工作流增加Face ID节点
安装完模型,就可以在工作流里进行配置了!
主要是一个IPAdapter应用节点,以及四个辅助节点。

添加节点-IP适配-IP适配应用(FaceID)。
主节点配置完成后,再将IP适配、CLIP视觉、InsightFace、图像、模型拖拉出新的节点。
(1)IP适配选择相应的ipadapter模型,我用的是SDXL模型,所以这里选了个SDXL的。
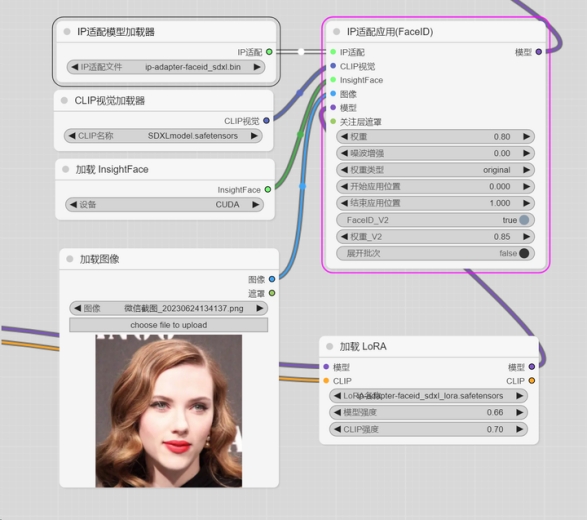
(2)CLIP视觉加载器,有两个模型可选。
SD1.5的只能选SD15,SDXL的默认选SDXL,如果出现图片尺寸相关的报错,则改成SD15即可。
(3)加载InsightFace,建议用CUDA,如果报错,可以改成CPU模式。
(4)加载图像,这里为换脸的原图输入。
(5)加载LoRA。该项不是选出来的,而是手动添加的,该项可选可不选。
Face ID提供了两个LoRA模型,一个SD1.5,一个SDXL,使用LoRA,效果会更好一些。这也是FaceID优于其他换脸工具的原因之一。
ipadapter节点左边的“模型”,连接到LoRA节点然后再连到大模型(本文是leosamsHelloworldXL),右边的“模型”,连接到采样器。
注意事项:ipadapter的权重,建议0.6-0.8之间,LoRA的权重,也建议0.6-0.8之间。否则容易过拟合。
二、调试提示词
沟通好每个小姐姐想要的发型、姿态。
然后试生成图片,请小姐姐们过目预览。
再根据需求进行调整。
这是一个漫长的过程... ...
省略一万字。
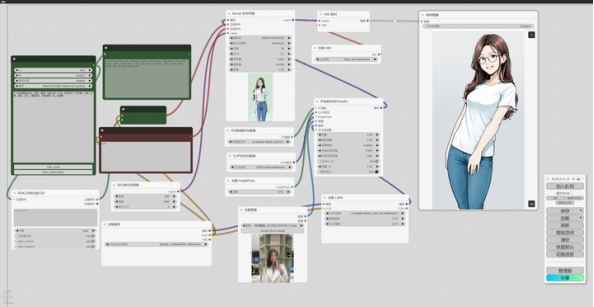
如图,上传一个小姐姐的自拍照(为防止泄露隐私,已打码),工作流生成照片。
经过不断的调整尺寸,调整姿态,终于得到一张小姐姐满意的照片。
七个小姐姐们的漫画风格照片逐一生成。

后面我的工作就省事了,她们用PS组合在一起,然后搬上了大屏幕。

排练的时候我看了一下效果,非常惊艳,引起了参与人员的轰动。
当然了,这个“订单”还有很多种解决方式,这并不是最优解。
我认为理想中的最佳方案是通过ControlNet控制体态,逐个面部进行对应,然后一次性生成大图。
只不过这种方式需要配置非常多的节点,对显卡要求也比较高,需要更多的准备时间,我精力有限(事实上和小姐姐们沟通的时间并不短),就选择了逐张生成的方式。
小姐姐们非常满意,甚至有几位把头像换成了AI漫画。

PS,凌晨跑完图后,好友问我为啥还没休息,我兴奋的解释了下,于是又给她做了一张头像。

出自:https://mp.weixin.qq.com/s/xi0AuBSio9f0WbyPVPy6Qg
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip