本文介绍了俄罗斯AI研究团队AI Forever开源的新文生图模型Kandinsky-3。该模型采用了直接文本引导的Latent Diffusion模型,使用了一个超大的text encoder,导致模型总参数达到了11.9B,是目前最大的开源文生图模型。模型结构包括text encoder和UNet模型,其中text encoder采用的是谷歌的Flan-UL2,UNet模型参数量为3B。Kandinsky-3还采用了多阶段的训练策略,可以直接生成1024x1024的图像。与之前的Kandinsky 2.2相比,Kandinsky-3在文本理解方面有一定优势,但生成图像的质量相当。文章还提供了上手体验和模型效果实测的相关信息。总体来说,虽然Kandinsky-3在文本理解方面弱于DALL-E 3,但仍然是一个值得关注的开源文生图模型。
在开源Kandinsky 2.2之后,俄罗斯AI研究团队AI Forever又开源了新的文生图模型Kandinsky-3,这个模型最特别之处时采用了一个超大的text encoder(参数量为8.6B),导致模型总参数达到了11.9B,这应该是目前最大的开源文生图模型。这篇文章我们简单介绍一下Kandinsky-3的模型结构、训练策略以及模型生成效果。
Kandinsky 2.2
在介绍Kandinsky-3之前,我们先说说之前的Kandinsky 2.2,Kandinsky 2.2可以看成是DALL-E 2和Latent Diffusion的混合体。Kandinsky 2.2和DALL-E 2一样采用两阶段生成方案:第一阶段采用一个prior模型基于文本生成图像的CLIP image embedding,第二阶段使用CLIP image embedding作为条件生成图像。这里的prior模型是一个基于transformer decoder架构的扩散模型(下图中第一列),其采用CLIP text encoder来编码文本。而第二阶段的生成模型(第二列)采用的是一个基于UNet架构的Latent Diffusion模型,这里的条件是CLIP image embedding。两个阶段的模型串起来就是文本到图像的生成。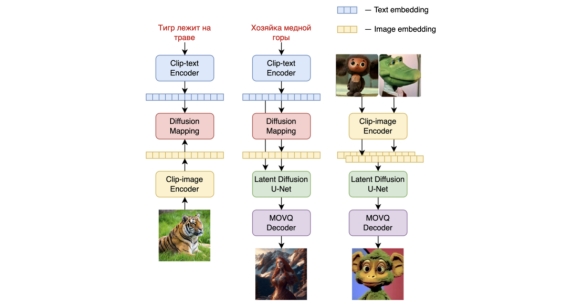 DALL-E 2的这种两阶段的方案的一个是优势是第二阶段只需要纯图像数据来训练图像生成模型,而且采用CLIP image embedding作为条件比直接用文本训练模型更容易一些。但是DALL-E 2比较大的缺陷是容易出现属性的混淆,下图展示了直接用给定图像的CLIP image embedding送入DALL-E 2的第二阶段生成模型的生成效果,可以看到属性出现了错乱,比如第一个示例中的上下两个方块的颜色发生了互换。
DALL-E 2的这种两阶段的方案的一个是优势是第二阶段只需要纯图像数据来训练图像生成模型,而且采用CLIP image embedding作为条件比直接用文本训练模型更容易一些。但是DALL-E 2比较大的缺陷是容易出现属性的混淆,下图展示了直接用给定图像的CLIP image embedding送入DALL-E 2的第二阶段生成模型的生成效果,可以看到属性出现了错乱,比如第一个示例中的上下两个方块的颜色发生了互换。 而且DALL-E 2比较难生成包含正确文本的图像,比如下面的"deep learning":
而且DALL-E 2比较难生成包含正确文本的图像,比如下面的"deep learning": 最主要的原因还是CLIP image embedding本身,通过对比学习训练的CLIP image embedding在区分属性和拼写单词方面均不太行。所以DALL-E 2存在一定的上限,这也是为什么DALL-E 3放弃了这种两阶段策略,而是直接采用文本引导的图像生成模型。类似地,Kandinsky-3放弃了Kandinsky 2.2这种架构。一个题外话是Kandinsky是俄罗斯的一个著名画家,他是世界公认的现代抽象绘画的开拓者,所以俄罗斯的文生图模型取名叫Kandinsky背后还是有一定的蕴意。
最主要的原因还是CLIP image embedding本身,通过对比学习训练的CLIP image embedding在区分属性和拼写单词方面均不太行。所以DALL-E 2存在一定的上限,这也是为什么DALL-E 3放弃了这种两阶段策略,而是直接采用文本引导的图像生成模型。类似地,Kandinsky-3放弃了Kandinsky 2.2这种架构。一个题外话是Kandinsky是俄罗斯的一个著名画家,他是世界公认的现代抽象绘画的开拓者,所以俄罗斯的文生图模型取名叫Kandinsky背后还是有一定的蕴意。
模型结构
Kandinsky-3采用了直接文本引导的Latent Diffusion模型,架构如下所示: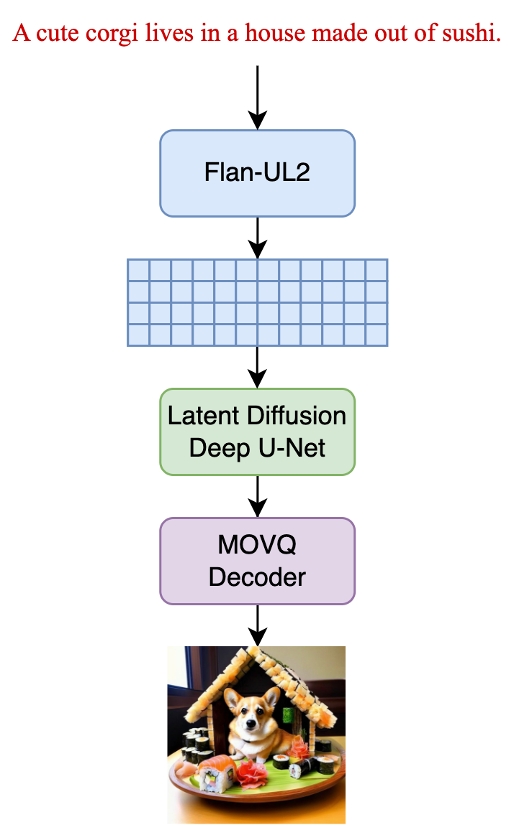
其中text encoder采用的是谷歌的Flan-UL2,这个模型的参数量是20B,它和谷歌的T5采用同样的架构,但是比最大的T5模型T5-XXL大了近两倍,当然性能有一个提升(这里加上Flan简单来说就是在原来模型基础上再进行了instruction finetuning):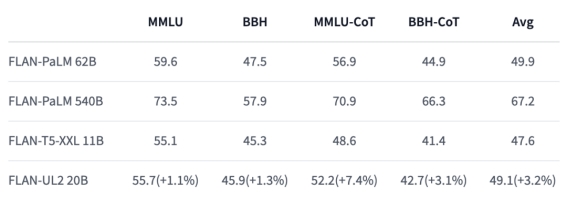 Flan-UL2和T5一样也是encoder-decoder架构,所以这里实际用到的是encoder部分,Flan-UL2 Encoder参数量为8.6B,也比T5-XXL Encoder(4.6B)大了将近2倍。和常规的文生图模型一样,这里也是将text encoder提取的文本特征通过cross attention嵌入到扩散模型UNet中。不过这里有两个重要的细节:一是Kandinsky-3采用的文本tokens长度是128,要比基于CLIP text encoder的SD支持更长的文本输入;二是Kandinsky-3还额外采用一个attention pooling从文本特征得到一个全局特征,然后把这个全局特征加在time embedding上嵌入UNet中(SDXL也是将CLIP ViT-G的全局特征类似处理)。
Flan-UL2和T5一样也是encoder-decoder架构,所以这里实际用到的是encoder部分,Flan-UL2 Encoder参数量为8.6B,也比T5-XXL Encoder(4.6B)大了将近2倍。和常规的文生图模型一样,这里也是将text encoder提取的文本特征通过cross attention嵌入到扩散模型UNet中。不过这里有两个重要的细节:一是Kandinsky-3采用的文本tokens长度是128,要比基于CLIP text encoder的SD支持更长的文本输入;二是Kandinsky-3还额外采用一个attention pooling从文本特征得到一个全局特征,然后把这个全局特征加在time embedding上嵌入UNet中(SDXL也是将CLIP ViT-G的全局特征类似处理)。
Kandinsky-3虽然也是Latent Diffusion模型,但是却和SD采用不一样的autoencoder,这里采用的是参数为270M的SBER-MoVQGAN,它是VQGAN的改进版本,从定量评测上来看,它要比SD所用的VAE效果要好: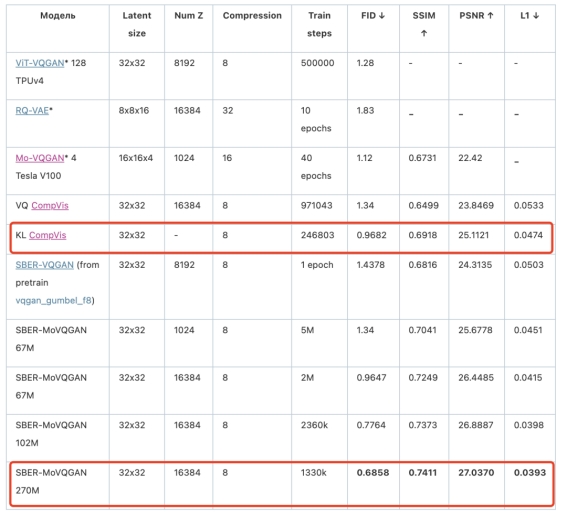 不过两个模型都是将512x512的图像压缩为32x32x4的latents,所以实际效果应该差不太多。
不过两个模型都是将512x512的图像压缩为32x32x4的latents,所以实际效果应该差不太多。
Kandinsky-3的UNet模型参数量为3B,比如SDXL(2.6B)还大一些。UNet的模型结构如下所示: 从整体上看,这个UNet也是包含4个stage,最后一个stage没有下采样,所以总共下采样了8x。和SDXL的设计一下,第一个stage的没有包含attention层,应该也是为了降低计算量。另外三个stage包含self-attention和cross-attention,这里的一个特别之处是每个stage只含有一个放在开始的self-attention层(对于decoder是放在最后),这应该也是为了降低计算量,因为self-attention应该是开销最大的。此外,UNet的卷积模块采用的是Big Gan Deep模块,这个模块是包含4个卷积层的残差模块(如果包含下采样或者上采样,还会多一个额外的stride=2的卷积或者反卷积层)。每个stage的基础模块就是Big Gan Deep + Cross Attn + Big Gan Deep,图中N实际上取3。4个stage的channels分别是384,768,1536,3072。
从整体上看,这个UNet也是包含4个stage,最后一个stage没有下采样,所以总共下采样了8x。和SDXL的设计一下,第一个stage的没有包含attention层,应该也是为了降低计算量。另外三个stage包含self-attention和cross-attention,这里的一个特别之处是每个stage只含有一个放在开始的self-attention层(对于decoder是放在最后),这应该也是为了降低计算量,因为self-attention应该是开销最大的。此外,UNet的卷积模块采用的是Big Gan Deep模块,这个模块是包含4个卷积层的残差模块(如果包含下采样或者上采样,还会多一个额外的stride=2的卷积或者反卷积层)。每个stage的基础模块就是Big Gan Deep + Cross Attn + Big Gan Deep,图中N实际上取3。4个stage的channels分别是384,768,1536,3072。
下表展示了Kandinsky-3和SDXL以及Kandinsky 2.2的模型参数对比,Kandinsky-3总参数比SDXL大了3倍多,而且每个组件都比SDXL要大。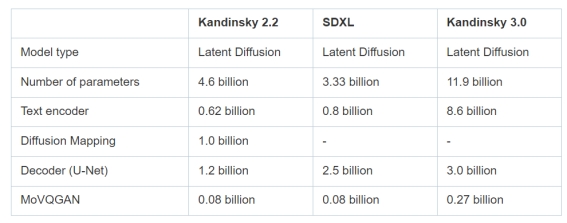
训练策略
Kandinsky-3和Kandinsky 2.2一样应该都是使用LAION数据集进行训练,不过相比Kandinsky 2.2这里额外增加了和俄罗斯相关的图像,并采用多模态语言大模型给图片生成文本描述。Kandinsky-3也采用了多阶段的训练策略,如下所示: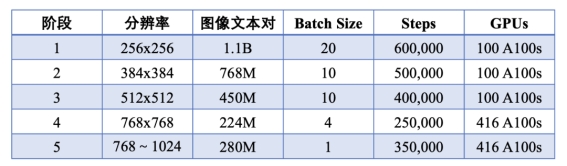 相比SDXL,Kandinsky-3在分辨率处理上粒度更新,多了384x384和768x768两个阶段。和SDXL一样,最后一个阶段也是采用多尺度训练策略,最终Kandinsky-3可以直接生成1024x1024的图像。
相比SDXL,Kandinsky-3在分辨率处理上粒度更新,多了384x384和768x768两个阶段。和SDXL一样,最后一个阶段也是采用多尺度训练策略,最终Kandinsky-3可以直接生成1024x1024的图像。
模型效果
为了比较模型效果,这里是选择了包含21个类别的2100个prompt进行人工评测,评测也包括两个方面:生成图像和文本的一致性和视觉质量。从评测结果来看,Kandinsky-3在文本一致性上有一定优势,但是生成图像的质量和Kandinsky 2.2相当。这主要是因为Kandinsky-3使用了一个比较大的text encoder,而Kandinsky 2.2是采用了只有650M的OpenCLIP ViT-bigG。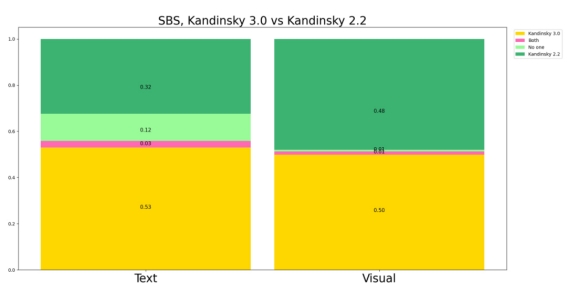
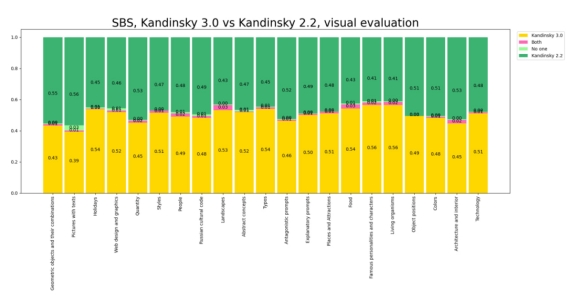
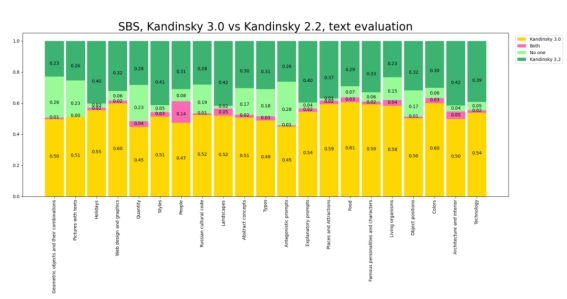
Kandinsky-3的主要优势还是在于文本理解方面,下面的对比图展示了这个优势,而Kandinsky 2.2容易出现概念的混淆:




由于Kandinsky-3训练过程中增加了俄罗斯文化的相关图像,所以也能更好地生成复合俄罗斯文化的图像:

下面的对比图展示了Kandinsky-3和更多模型(MJ v5.2,DALL-E 3和SDXL)的对比: A beautiful girl
A beautiful girl
 A highly detailed digital painting of a portal in a mystic forest with many beautiful trees. A person is standing in front of the portal.
A highly detailed digital painting of a portal in a mystic forest with many beautiful trees. A person is standing in front of the portal. A man with a beard
A man with a beard A 4K dslr photo of a hedgehog sitting in a small boat in the middle of a pond. It is wearing a Hawaiian shirt and a straw hat. It is reading a book. There are a few leaves in the background.
A 4K dslr photo of a hedgehog sitting in a small boat in the middle of a pond. It is wearing a Hawaiian shirt and a straw hat. It is reading a book. There are a few leaves in the background. Barbie and Ken are shopping
Barbie and Ken are shopping Extravagant mouthwatering burger, loaded with all the fixings. Highlight layers and texture
Extravagant mouthwatering burger, loaded with all the fixings. Highlight layers and texture A bear in Russian national hat with a balalaika
A bear in Russian national hat with a balalaika
我也基于开源的Kandinsky-3模型进行了实测,这里我也是从Imagen的DrawBench中选择了4个prompts,分别测试模型在颜色、计数、位置关系和文字方面的能力,生成效果如下所示,整体上表现还可以,但是文字方面不太行。
如何上手
如果想直接上手测试,可以使用官方的体验网站: 当然,Kandinsky-3也已经开源了,而且目前已经集成到huggingface的diffusers库中,所以你可以直接下载来使用:
当然,Kandinsky-3也已经开源了,而且目前已经集成到huggingface的diffusers库中,所以你可以直接下载来使用:
# 安装最新的diffusers
# pip install git+https://github.com/huggingface/diffusers.git
# pip install --upgrade transformers accelerate
from diffusers import Kandinsky3Pipeline
import torch
pipe = Kandinsky3Pipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload() # 要开这个,要不然显存扛不住
prompt = "A photograph of the inside of a subway train. There are raccoons sitting on the seats. One of them is reading a newspaper. The window shows the city in the background."
generator = torch.Generator(device="cpu").manual_seed(0)
image = pipe(prompt, num_inference_steps=25, generator=generator).images[0]
 还可以实现图生图:
还可以实现图生图:
from diffusers import Kandinsky3Img2ImgPipeline
from diffusers.utils import load_image
import torch
pipe = Kandinsky3Img2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A painting of the inside of a subway train with tiny raccoons."
image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky3/t2i.png")
generator = torch.Generator(device="cpu").manual_seed(0)
image = pipe(prompt, image=image, strength=0.75, num_inference_steps=25, generator=generator).images[0]
 image.png
image.png
小结
虽然Kandinsky-3使用了一个超大的text encoder,但是在文本理解方面还是弱于DALL-E 3,我觉得最大的原因还是在于数据,毕竟DALL-E 3的重点其实也放在了数据上面(生成高质量的文本描述)。我个人的观点是,对于文生图模型:**数据 > text encoder > diffusion model (UNet)**。但是还是致敬俄罗斯研究团队,没想到在美国的封锁一下,他们竟然还有A100显卡,并且训练出了自己的模型并开源,而且近期还开源了文生视频模型Kandinsky Video。
出自:https://mp.weixin.qq.com/s/cQK_Nj5eFz27mjOJpC0zqQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip