本文介绍了Python中常用的中文分词库,包括jieba、SnowNLP、pyltp和THULAC,并重点介绍了jieba库的安装和使用方法,包括精确模式、搜索引擎模式和全模式的分词,以及自定义词典、关键词提取、词性标注等功能的介绍。同时,本文还通过一个示例展示了如何使用jieba库对文本进行分词,并结合WordCloud和matplotlib库生成词云图像。
今天我们来简单介绍下中文分词库。
01
—
分词库
在Python中,有多个分词库可供选择。以下是一些常用的中文分词库:
1. jieba:jieba是Python中最常用的中文分词库之一,具有简单易用、高效的特点。可以通过pip安装:`pip install jieba`
2. SnowNLP:SnowNLP是一个基于概率算法的中文自然语言处理工具包,其中包含了中文分词功能。可以通过pip安装:`pip install snownlp`
3. pyltp:pyltp是哈工大社会计算与信息检索研究中心开发的中文自然语言处理工具包,其中包括了中文分词功能。可以通过pip安装:`pip install pyltp`
4. THULAC:THULAC(THU Lexical Analyzer for Chinese)是由清华大学自然语言处理与社会人文计算实验室开发的中文词法分析工具包,其中包含了中文分词功能。可以通过pip安装:`pip install thulac`
这些分词库都有各自的特点和适用场景,你可以根据自己的需求选择合适的分词库进行使用。
当你安装了jieba库之后,你就可以在Python中使用它来进行中文分词。下面是一个简单的介绍:
首先,你需要使用`import jieba`语句将jieba库导入你的Python脚本中。
接下来,你可以使用`jieba.cut`方法来对中文文本进行分词,例如:

上述代码中,`jieba.cut`方法用于对`text`进行分词,`cut_all=False`表示使用精确模式进行分词,将分词结果存储在`seg_list`中,并通过`"/ ".join(seg_list)`将分词结果以空格分隔打印出来。
除了精确模式外,jieba还支持搜索引擎模式和全模式的分词,你可以根据自己的需求选择合适的模式。
此外,jieba还支持添加自定义词典、关键词提取、词性标注等功能,具体可以查阅jieba库的官方文档以了解更多信息。
02
—
使用举例
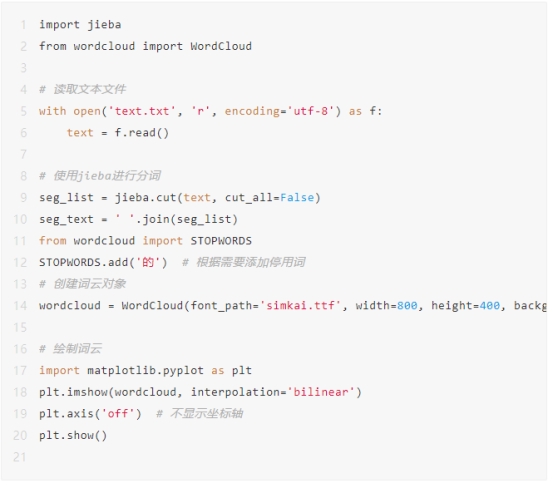
下面是一个简单的示例:
假设你有一个名为`text.txt`的文本文件,其中包含需要生成词云的文本内容。首先,使用jieba库对文本进行分词,并将分词结果拼接成字符串。然后,创建一个WordCloud对象,并指定词云的宽度、高度、背景颜色等参数。最后,使用matplotlib库绘制词云图像并显示出来。
你可以根据自己的需求调整词云的参数,以及对分词结果进行处理、过滤等操作,以获得更好的词云效果。

出自:https://mp.weixin.qq.com/s/ZkBNJqr17RXf92dbfg80JQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip