本文提出了PanGu-Draw,一种资源高效的潜在扩散模型,旨在实现高效的文本到图像合成,并适应多种控制信号。该模型通过时间解耦训练策略,将文本到图像合成分解为结构和纹理两个生成器,提高数据和训练效率。同时,PanGu-Draw引入协同扩散算法,能够整合不同潜在空间和分辨率的预训练扩散模型,实现多控制图像合成。实验结果表明,PanGu-Draw在文本到图像和多控制图像生成方面表现卓越,为未来模型训练效率和生成通用性提供了新方向。
文章地址:https://arxiv.org/pdf/2312.16486.pdf
项目地址:https://pangu-draw.github.io
00 | 导言
目前的大规模扩散模型代表了条件图像合成的巨大飞跃,能够解释各种线索,如文本、人体姿势和边缘。然而,它们对大量计算资源和广泛数据收集的依赖仍然是一个瓶颈。另一方面,由于图像分辨率和潜在空间嵌入结构不兼容,现有的扩散模型(每个模型专门用于不同的控制并在独特的潜在空间中运行)的集成带来了挑战,阻碍了它们的联合使用。
针对这些限制,本文提出了“PanGu-Draw”,这是一种新型的潜在扩散模型,专为资源高效的文本到图像合成而设计,能够适应多种控制信号。首先提出了一种资源高效的时间解耦训练策略,该策略将单一的文本到图像模型分解为结构和纹理生成器。每个生成器都使用最大限度地提高数据利用率和计算效率的方案进行训练,减少了48%的数据准备,减少了51%的训练资源。其次,引入了“协同扩散”算法,该算法能够在统一的去噪过程中协同使用具有不同潜在空间和预定义分辨率的各种预训练扩散模型。这允许在任意分辨率下进行多控制图像合成,而不需要额外的数据或再训练。
经验验证表明,Pangu-Draw在文本到图像和多控制图像生成方面具有卓越的能力,为未来模型训练效率和生成通用性提供了一个有希望的方向。
贡献:
·
PanGu-Draw:一个具有时间解耦训练策略的资源高效扩散模型,减少了文本到图像合成的数据和训练资源。
·
·
Coop-Diffusion:一种集成多个扩散模型的新方法,在统一的去噪过程中实现多分辨率的高效多控制图像合成。
·
·
PanGu-Draw (5B模型)可以生成与文本和各种控件对齐的高质量图像,提高了基于扩散的图像生成的可扩展性和灵活性。
·
01 | 方法
1.1 时间解耦训练策略

三种多阶段训练策略
提高数据、训练和推理效率对于文本到图像模型的实际应用至关重要。图1显示了两种现有的训练策略:(a)级联训练,使用三个模型来逐步提高分辨率,数据效率高,但训练和推理时间增加了三倍。(b)分辨率提升训练从512x512开始,然后是1024x1024分辨率,丢弃较低分辨率的数据,并在所有时间步长上以较高的训练成本和单模型推理提供适度的效率。为了提高效率,作者从扩散过程的去噪轨迹中汲取灵感,其中初始去噪阶段主要塑造图像的结构基础,后期阶段细化其纹理复杂性。在此基础上,引入了时间解耦训练策略。这种方法将一个综合的文本到图像模型(表示为 )分成两个跨不同时间间隔操作的专门子模型:结构生成器
)分成两个跨不同时间间隔操作的专门子模型:结构生成器 和纹理生成器
和纹理生成器 。每个子模型的大小是原始模型的一半,从而增强了可管理性并减少了计算负载。如图1(c)所示,结构生成器
。每个子模型的大小是原始模型的一半,从而增强了可管理性并减少了计算负载。如图1(c)所示,结构生成器 负责在较大的时间步长范围内进行早期去噪,特别是在
负责在较大的时间步长范围内进行早期去噪,特别是在 , 其中
, 其中 ;这个阶段的重点是建立图像的基本轮廓。相反,纹理生成器
;这个阶段的重点是建立图像的基本轮廓。相反,纹理生成器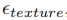 在较小的时间步长期间运行,用
在较小的时间步长期间运行,用 表示,详细说明纹理细节。每个生成器都是隔离训练的,这不仅减轻了对高内存计算设备的需求,而且避免了与模型分片相关的复杂性及其伴随的机器间通信开销。
表示,详细说明纹理细节。每个生成器都是隔离训练的,这不仅减轻了对高内存计算设备的需求,而且避免了与模型分片相关的复杂性及其伴随的机器间通信开销。
在推理阶段,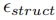 首先从初始随机噪声向量
首先从初始随机噪声向量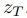 构造一个基本结构图像
构造一个基本结构图像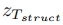 。随后,
。随后,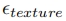 对这个基础进行了细化,以增强纹理细节,最终输出
对这个基础进行了细化,以增强纹理细节,最终输出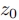 。这种顺序处理促进了更高效的资源工作流程,显著减少了硬件占用并加快了生成过程,而不会影响模型的性能或输出质量。
。这种顺序处理促进了更高效的资源工作流程,显著减少了硬件占用并加快了生成过程,而不会影响模型的性能或输出质量。
资源节约型训练制度 作者进一步对以上两种模型采用了专业化的训练设计。结构生成器 从文本中派生图像结构,需要在包含广泛概念的广泛数据集上进行训练。传统方法,如稳定扩散,通常会消除低分辨率图像,丢弃大约48%的训练数据,从而增加数据集成本。相反,作者将高分辨率图像与升级后的低分辨率图像集成在一起。这种方法没有显示出性能下降,因为预测的
从文本中派生图像结构,需要在包含广泛概念的广泛数据集上进行训练。传统方法,如稳定扩散,通常会消除低分辨率图像,丢弃大约48%的训练数据,从而增加数据集成本。相反,作者将高分辨率图像与升级后的低分辨率图像集成在一起。这种方法没有显示出性能下降,因为预测的 仍然包含大量噪声。这样既可以提高数据效率,又避免了语义退化的问题。此外,由于图像结构是在
仍然包含大量噪声。这样既可以提高数据效率,又避免了语义退化的问题。此外,由于图像结构是在 中确定的,纹理生成器
中确定的,纹理生成器 专注于细化纹理,作者建议以较低的分辨率训练
专注于细化纹理,作者建议以较低的分辨率训练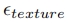 ,同时仍然以高分辨率采样。结果不会导致性能下降,也不会出现结构性问题。因此,训练效率实现了51%的总体提高。图1总结了不同训练策略的数据、训练和推理效率。除了更高的数据和训练效率外,与级联训练策略相比,本文的策略还实现了更高的推理效率,与级联训练策略相比,推理步骤更少,与分辨率提升训练策略相比,每步模型更小。
,同时仍然以高分辨率采样。结果不会导致性能下降,也不会出现结构性问题。因此,训练效率实现了51%的总体提高。图1总结了不同训练策略的数据、训练和推理效率。除了更高的数据和训练效率外,与级联训练策略相比,本文的策略还实现了更高的推理效率,与级联训练策略相比,推理步骤更少,与分辨率提升训练策略相比,每步模型更小。
1.2 Coop-Diffusion:多扩散融合
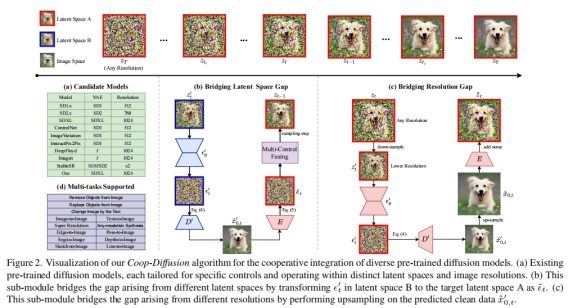
如图2(a)所示,有许多预训练的扩散模型,如各种SD、ControlNet、图像变化等,每个模型都针对特定的控制和图像分辨率量身定制。在不需要训练新模型的情况下,将这些预训练模型融合到多控制或多分辨率图像生成中是有希望的。然而,这些模型的潜在空间和分辨率不同,阻碍了不同模型控制的图像的联合合成,从而限制了它们的实际应用。针对这些挑战,作者提出了具有两个关键子模块的Coop-Diffusion算法,如图2(b)和(c)所示,以弥合潜在空间差距和分辨率差距,并将同一空间中的去噪过程统一起来。
弥合潜在空间差距 为了弥合空间A和空间B之间的潜在空间差距,建议使用图像空间作为中间媒介,将潜在空间B中的模型预测 转化为潜在空间A中的模型预测,从而统一潜在空间A中的模型预测。具体方法如下:首先,使用式(3)预测干净数据
转化为潜在空间A中的模型预测,从而统一潜在空间A中的模型预测。具体方法如下:首先,使用式(3)预测干净数据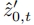 为:
为:
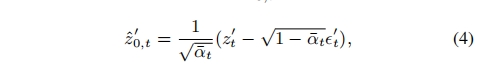
然后使用潜在解码器模型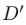 将其解码为像素级图像
将其解码为像素级图像 。使用图像编码器模型E将该图像编码到潜在空间A中,为
。使用图像编码器模型E将该图像编码到潜在空间A中,为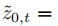
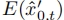 ,最后将式(3)逆变换为模型预测:
,最后将式(3)逆变换为模型预测:

有了统一的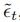 ,现在可以在
,现在可以在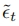 和
和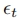 之间进行多控制融合(潜在空间A中
之间进行多控制融合(潜在空间A中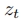 来自模型
来自模型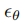 的预测,为简洁起见,在图2中省略):
的预测,为简洁起见,在图2中省略):

其中d和1−d为d∈[0,1]的每个模型的引导强度,与这两个模型共同指导多控制图像生成的去噪过程。算法1进一步说明了这一融合过程:

弥合分辨率差距 为了整合低分辨率模型和高分辨率模型的去噪过程,上采样和/或下采样是必要的。传统的双线性上采样通常用于去噪过程中的中间结果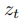 ,会对像素相关性产生不利的放大。这种放大偏离了最初的独立同分布(IID)假设,导致最终图像出现严重的伪影,如图3(a)所示。相反,下采样不会出现这个问题。为了解决上采样中的IID问题,作者提出了一种新的上采样算法,该算法保留了IID假设,从而弥合了具有不同预训练分辨率的模型之间的分辨率差距。
,会对像素相关性产生不利的放大。这种放大偏离了最初的独立同分布(IID)假设,导致最终图像出现严重的伪影,如图3(a)所示。相反,下采样不会出现这个问题。为了解决上采样中的IID问题,作者提出了一种新的上采样算法,该算法保留了IID假设,从而弥合了具有不同预训练分辨率的模型之间的分辨率差距。

不同上采样方法对低分辨率模型和高分辨率模型的融合结果。从中间 上采样会导致严重的伪影,本文上采样算法会产生高保真图像
上采样会导致严重的伪影,本文上采样算法会产生高保真图像
图2(c)可视化了上采样算法。具体来说,对于低分辨率 ,使用图像空间作为中间空间,将低分辨率空间中的
,使用图像空间作为中间空间,将低分辨率空间中的 转换为高分辨率空间中的
转换为高分辨率空间中的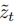 。首先用去噪模型
。首先用去噪模型 预测噪声
预测噪声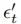 ,然后预测干净数据
,然后预测干净数据 ,如Eq. 4所示。使用解码器
,如Eq. 4所示。使用解码器 将其解码为图像
将其解码为图像 。然后,对
。然后,对 进行上采样,以获得高分辨率的
进行上采样,以获得高分辨率的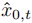 。最后,编码器E将
。最后,编码器E将 编码到隐空间中为
编码到隐空间中为 ,并添加t步噪声,使用Eq. 1得到最终结果
,并添加t步噪声,使用Eq. 1得到最终结果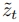 。
。
有了统一的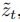 ,现在可以进行多分辨率融合。首先,使用低分辨率模型去噪以获得中间
,现在可以进行多分辨率融合。首先,使用低分辨率模型去噪以获得中间 及其高分辨率对应
及其高分辨率对应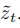 。然后,使用从
。然后,使用从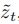 开始的高分辨率模型进行去噪,反之亦然。这种方法允许在不经历所有低分辨率去噪步骤的情况下进行一级超分辨率,从而提高推理效率。算法1进一步说明了这一融合过程。
开始的高分辨率模型进行去噪,反之亦然。这种方法允许在不经历所有低分辨率去噪步骤的情况下进行一级超分辨率,从而提高推理效率。算法1进一步说明了这一融合过程。
02 | 实验结果
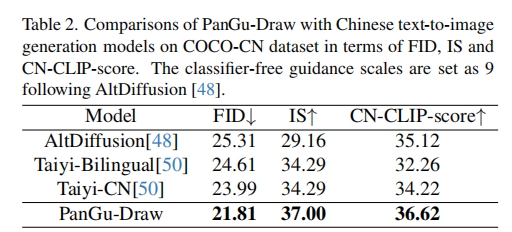
如表1所示,PanGu-Draw的FID为7.99,优于dall - e2和SDXL等比较方法。它还实现了与SOTA方法竞争的FID,表明时间解耦训练策略的有效性以及出色的数据和训练效率。就FID而言,5B盘古模型是发布最好的模型。
如表2所示,PanGuDraw在所有三个指标上都优于其他已发布的中文文本到图像模型,包括Taiyi-CN、Taiyi-Bilingual和AltDiffusion。这一表现突出了盘古绘卓越的中文文本到图像生成能力,以及双语文本编码器架构的有效性。

使用5B多语言文本到图像生成模型PanGu-Draw生成的图像。panu - draw能够生成与输入提示语义一致的多分辨率高保真图像。
出自:https://mp.weixin.qq.com/s/Fa0CAiDhr6vFDszHJJGYbQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip