文章总结了应用程序从流程编排到灵活Pipeline的发展,特别在大模型AI时代,Pipeline成为构建AI应用的关键载体。介绍了FlowEngine和llamaindex的QueryPipeline,强调声明式Pipeline的灵活性和模块化优势,使AI应用开发更加简单、低门槛。展示了如何通过QueryPipeline构建复杂流程,并介绍了运行Pipeline及可视化流程的方法。
应用程序的本质往小里说是代码组织,往大里说就是逻辑编排。在大模型时代以前,比如推荐等大数据AI领域,其发展的趋势就是流程编排。传统做法是固化召回,粗排,精排等环节,形成标准的推荐系统处理流程,虽然有利于行业内交流沟通,但这样的方式,在实际生产环境下往往难以快速应对差异化的需求且人为导致模块的割裂及维护的困难,而笔者曾开源了一个AI应用编排的框架——FlowEngine(https://flow-engine.github.io/),其核心就是通过声明式的pipeline(离线、流式、实时三大编排Pipeline)来组织整个应用过程,这样可以更灵活,更泛化的构建各类生产级AI应用。
到了大模型AI时代,早期的RAG流程在生产应用的过程中越来越发现存在流程僵化,难以应对多变复杂的实际需求,这就促使框架们不断打开自己,朝着灵活定制的方向发展。在这里不论是langchain选择了命令式的langchain template,还是今天要介绍的主角llamaindex选择的声明式的QueryPipeline,以及在此之前已经发布了数据处理阶段的pipeline(IngestionPipeline),都是在昭示一个趋势,所谓RAG也好,还是未来的Agent也好,Pipeline将会是它们共享的一个更泛化载体。值得一提的是,langchain在近日发布的0.1.0版本引入的agent自定义框架langgraph也是这方面的一个证明(注意:它并不是DAG方式实现)。参看:《LangChain 0.1.0版本正式发布,One More Thing将成了Agent落地生产的福音》
说回到llamaindex
Query pipeline,其核心能力是允许开发者针对不同的应用场景(RAG、结构化数据提取等),结合实际需要构建高度定制的流程。其核心抽象是将Llamaindex的各种模块(LLM、提示、查询引擎、检索器等)作为DAG图上的节点,通过声明式编排完成应用逻辑开发。

在前面的文章里《LlamaIndex官方年度巨献:高清大图纵览高级 RAG技术,强烈推荐收藏》可以看到很多高级的技术,其本质是DAG图上的精细化改进。
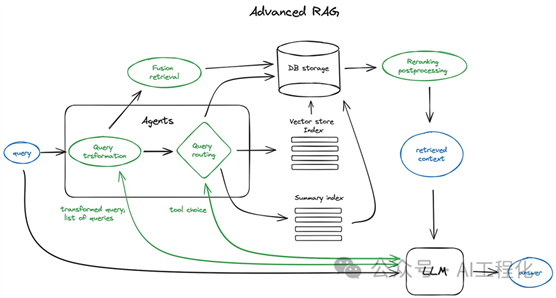
通过QueryPipeline使得这样的改进变得简单,再加上这样的设计客观上,可以避免传统方式的硬编码,提升模块化水平。进一步,在此基础上做langflow这样的拖拉拽的可视化开发,将会进一步降低LLM应用的开发门槛。值得一提的是,现在基于langchain开发的langflow或者flowise等拖拉拽可视化产品,由于langchain本身的流程封闭性,导致在此基础上封装编排流程在实际生产中很鸡肋,“有形而无神”,而未来基于这种开放的,自由定制的,声明式的,细颗粒的模块化Pipeline构建的LLM应用可视化开发流程才有可能会成为真正的低门槛落地的主流形式。
下面,我们一起看看如何构建一个QueryPipeline。
1)创建一个pipeline:
·
简单的Chain
·
# try chaining basic prompts
prompt_str = "Please generate related movies to {movie_name}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
p = QueryPipeline(chain=[prompt_tmpl, llm], verbose=True)
·
复杂的流程
·
from llama_index.postprocessor import CohereRerank
from llama_index.response_synthesizers import TreeSummarize
from llama_index import ServiceContext
# define modules
prompt_str = "Please generate a question about Paul Graham's life regarding the following topic {topic}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
retriever = index.as_retriever(similarity_top_k=3)
reranker = CohereRerank()
summarizer = TreeSummarize(
service_context=ServiceContext.from_defaults(llm=llm)
)
# define query pipeline
p = QueryPipeline(verbose=True)
p.add_modules(
{
"llm": llm,
"prompt_tmpl": prompt_tmpl,
"retriever": retriever,
"summarizer": summarizer,
"reranker": reranker,
}
)
# add edges
p.add_link("prompt_tmpl", "llm")
p.add_link("llm", "retriever")
p.add_link("retriever", "reranker", dest_key="nodes")
p.add_link("llm", "reranker", dest_key="query_str")
p.add_link("reranker", "summarizer", dest_key="nodes")
p.add_link("llm", "summarizer", dest_key="query_str")
2)运行一个pipeline:
·
如果pipeline只有一个 "根 "节点和一个输出节点,则使用 run。
·
output = p.run(topic="YC")
# output type is Response
type(output)
·
如果管道有多个根节点和/或多个输出节点,请使用 run_multi 。
·
·
output_dict = p.run_multi({"llm": {"topic": "YC"}})
print(output_dict)
同时,为了更好地观察整个流程执行情况,llamaindex的DAG组件均支持回调设计,类似于Langchain LCEL的设计,因此,可以利用 Arize Phoenix(https://github.com/Arize-ai/phoenix) 来对流程进行可视化。
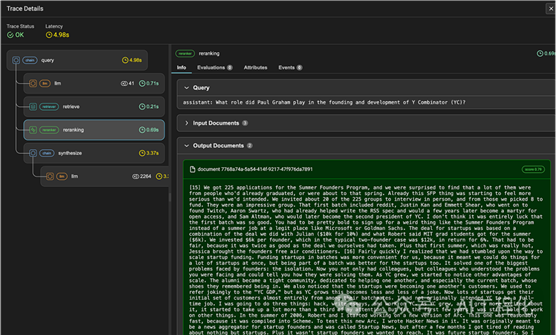
更多有关queryPipeline的细节可查看:https://docs.llamaindex.ai/en/latest/module_guides/querying/pipeline/root.html
出自:https://mp.weixin.qq.com/s/R7YW0jJKqjWNTW0dkdtdQQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip