Retrieval Augmented Thoughts (RAT) 是一种结合协同思维链和检索增强生成的 AI 策略,旨在解决 LLM 在长任务推理中的事实准确性问题,通过迭代修正模型推理步骤,提升输出准确性,广泛适用于代码生成、数学推理、创意写作和任务规划,为 AI 推理能力设定新标准。
Retrieval
Augmented Thoughts (RAT) 是一种协同思维链 (CoT) 和检索增强生成 (RAG) 的 AI 提示策略,助力解决具有挑战性的长任务推理和生成。
开发能够像人类一样思考、推理并解决复杂问题的模型一直是人工智能研究的关键目标。大规模语言模型(LLM)处于此类研究的最前沿,旨在模拟人类对概念的理解和表达。然而,LLM在确保长任务推理中的事实准确性方面仍然面临着巨大挑战,经常会出现所谓的“幻觉”(hallucination)——模型会生成看似合理但实际上并不准确的信息。这种现象在需要一系列逻辑推理的场景中尤其明显,凸显了LLM在长任务推理过程中、精确推理和理解上下文的能力方面的差距。
为弥合这一差距,研究人员提出了各种方法旨在改进 LLM 的推理过程。一些较早的方法尝试将外部信息检索与模型生成的内容相结合,以确保模型输出的事实准确性。然而,这些方法通常无法动态地改进推理过程,导致产生的结果虽然有所改善,却仍然未能达到理想的上下文理解和准确性水平。
来自北京大学、加州大学洛杉矶分校和北京通用人工智能研究院的研究人员提出的 Retrieval
Augmented Thoughts (RAT) 方法,旨在直接解决 LLM 中的事实准确性问题。RAT 是一种着重于迭代修正模型生成思路的新方法。通过利用与初始查询以及模型推理过程相关变动的信息,RAT 有效地缓解了幻觉问题。具体实现方法为:用从大型数据库中检索到的相关信息,去修正模型生成思维链的每一步,确保每个推理步骤都基于准确和相关的事实。
RAT 的优势
RAT 方法在各种长任务生成任务中表现出色,从生成复杂的代码到解决复杂的数学问题,以及撰写创意叙事、规划模拟环境中的行动方案。RAT 能稳定地提升 LLM 的性能,带来显著的性能提升。例如,代码生成任务的评分平均提高了 13.63%,数学推理的评分提高了 16.96%,创意写作的评分提高了 19.2%,在具体任务规划中的表现更是提升了 42.78%。这些成绩凸显了 RAT 作为一种通用解决方案在增强 LLM 推理能力方面的有效性和潜力。
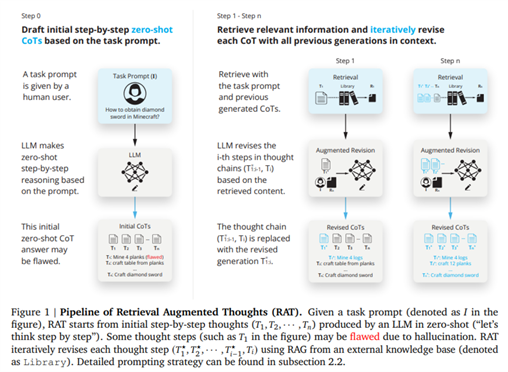
RAT 的实现显示了LLM有可能达到一种更接近人类的推理和生成响应的能力。通过使用与上下文相关的信息去迭代优化思考过程,该方法拓展了 LLM 可以实现目标的边界,为人工智能生成内容的准确性、可靠性和语境意识设定了新的标准。
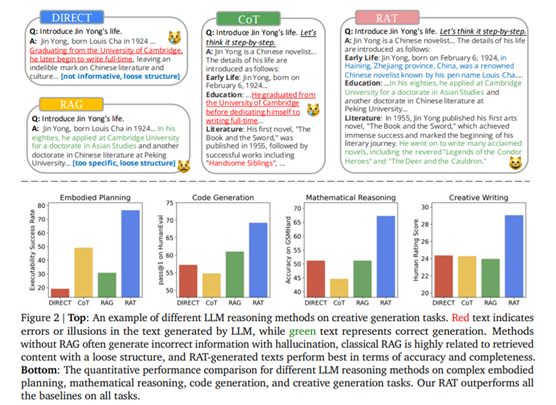
结论
Retrieval Augmented Thoughts (RAT) 方法可以概括为以下几点:
·
缩小了 LLM 在长任务推理中维持事实准确性能力方面的差距。
·
通过用相关的检索信息来修正每个推理步骤,缓解了幻觉问题,确保输出结果高度贴合语境。
·
在各种任务中展示了通用性,包括代码生成、数学推理、创意写作和任务规划,具有广泛的应用潜力。
·
为 LLM 输出的性能、准确性和可靠性设定了新的基准,为 AI 推理能力的未来发展铺平了道路。
出自:https://mp.weixin.qq.com/s/loQbbCX6Lx6uMwr3UvlvOQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip