本文介绍了TTS(文本转语音)技术的发展,从早期依赖预录制声音样本到现今基于AI的深度神经网络模型。随后,列举了多个好用且免费的文本转语音工具,包括TTS Maker、微软Azure、PaddleSpeech、VoiceVox、TensorFlowTTS、TTSKit、OpenTTS和eSpeak NG,并简要介绍了它们的特点、使用方式及官方网站或GitHub链接。
TTS(Text-to-Speech)技术是一项可以将文本转换成语音的技术。在早期,TTS技术主要依赖于预录制的声音样本,通过组合这些样本来生成语音。虽然这种方法能够产生可理解的语音,但由于样本数量的限制,很难达到完全自然的语音合成效果。
随着人工智能(AI)技术的进步,基于AI的TTS技术已经成为了新的标准。这种技术使用深度神经网络模型来合成语音,能够更自然地模拟人类的发音和语调,从而产生更加流畅和自然的语音输出。
下面是为大家整理的一些好用又免费的文本转语音工具。
TTS
Maker
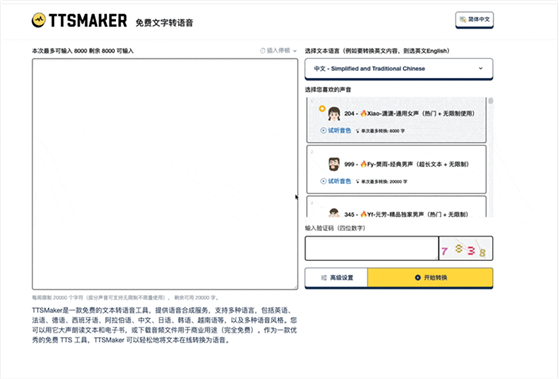
TTS Maker 是一个文本到语音(TTS)服务,支持多种语言和不同的声音选项(包括:中文、英语、日语、法语、阿拉伯语、韩语等等,甚至转换成方言:包括东北话、粤语、闽南话等等)。
特别适用于内容创作者、开发者和企业用户,需要为视频、播客、电子学习材料或任何其他需要语音旁白的项目生成语音。
单次转换限制字符数( 8000个字符) 每周限制 20000 个字符(部分声音可支持无限制不限量使用)
官网:https://ttsmaker.com/zh-cn
微软Azure
微软出品的一种语音服务功能,可将文本转换为逼真的语音。据说是目前最好用的文字转语音工具。
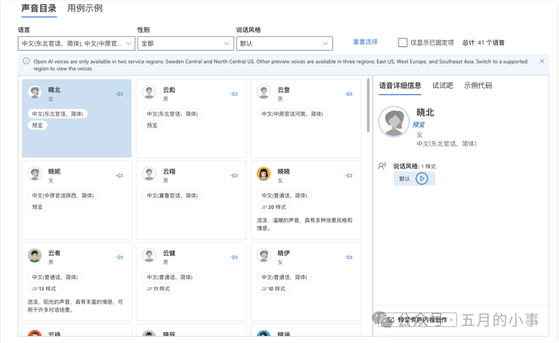
具有神经网络真人发音、支持在线体验和本地部署(通过Docker等方式)。该项目是开源的,后端依赖于微软的Azure语音模型。
有免费版和付费版,免费版有额度上限!微软Azure文本转语音:https://azure.microsoft.com/en-us/products/cognitive-services/text-to-speech/
PaddleSpeech
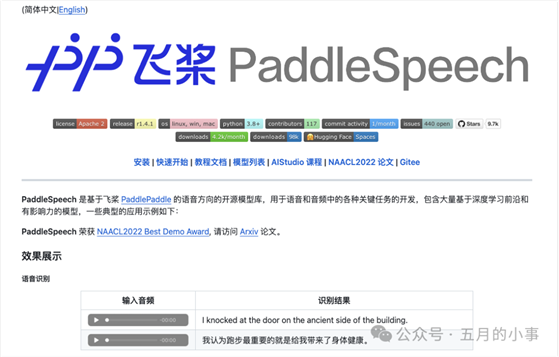
PaddleSpeech 是由百度开发的一个全面、灵活、高效的开源深度学习语音处理框架,基于PaddlePaddle深度学习平台。提供了基于 FastSpeech2 声学模型和 HiFiGAN 声码器的中文流式语音合成系统。
安装paddlespeech PaddleSpeech 快速安装方式有两种,一种是 pip 安装,一种是源码编译(官方推荐)。
pip 安装
1.
pip install pytest-runner
2.
pip install paddlespeech
源码编译
1.
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
2.
cd PaddleSpeech
3.
pip install
pytest-runner
4.
pip install .
GitHub:https://github.com/PaddlePaddle/PaddleSpeech
VoiceVox
VoiceVox是一个开源的文本到语音(TTS)软件,以高质量的语音合成能力著称,特别是在生成日语语音方面。
支持Windows / Mac / Linux三大平台,基于VOICEVOX的OSS(开源软件)版本构建,软件部分是Electron + Vue,语音合成引擎部分是Python + FastAPI。
提供了多种不同的声音库,这些声音库通常基于真实声优的声音进行训练和模拟,使得生成的语音既自然又具有表现力。
官网:https://voicevox.hiroshiba.jp/
GitHub:https://github.com/VOICEVOX/voicevox
TensorFlowTTS

TensorFlowTTS(TensorFlow Text-to-Speech)是一个基于TensorFlow 2的开源文本到语音转换库,包含了一系列最先进的深度学习模型,如FastSpeech
2、Tacotron 2、Multi-band MelGAN等,用于生成自然 sounding 的语音。不仅支持高质量的语音合成,还提供了训练、微调和部署这些模型的能力。
获取和使用
作为一个开源项目,TensorFlowTTS可以通过GitHub获得。
1.
pip install TensorFlowTTS
安装完成后,可以轻松地调用预训练模型进行文本到语音转换,或者根据自己的数据集训练新的模型。TensorFlowTTS还提供了丰富的文档和示例代码,帮助用户快速上手和深入理解如何使用这个库。
GitHub:https://github.com/TensorSpeech/TensorFlowTTS
TTSKit

TTSKit 是一个基于 Python 的文本转语音(TTS)库,通过集成多种开源TTS技术和模型,如 Tacotron 2、WaveNet、WaveGlow 等,能够生成高质量的语音输出。它支持多种语言和声音,可用于多种应用场景,从基本的文本阅读到复杂的语音交互系统。
获取和使用
TTSKit 作为一个Python库,可以通过 pip
安装。安装过程简单,通常只需要执行如下命令:
1.
pip install ttskit
安装后,开发者可以通过简单的几行代码调用TTSKit生成语音,例如:
1.
import ttskit
2.
3.
text = "你好,世界!"
4.
ttskit.text_to_speech(text,
'output.mp3')
这将会把文本 "你好,世界!" 转换为语音,并保存到 output.mp3 文件中。
TTSKit 提供了一个强大且易于使用的解决方案,使开发者能够在各种Python项目中轻松集成高质量的文本到语音转换功能。
GitHub:https://github.com/kuangdd/ttskit
OpenTTS
OpenTTS(Open Text-to-Speech)是一个开源的文本到语音转换项目,通过整合和利用现有的开源TTS引擎(如Mozilla的TTS、MaryTTS、eSpeak NG等)和语音合成技术,为用户和开发者提供了一个统一的接口来生成自然 sounding 语音。
GitHub:https://github.com/synesthesiam/opentts
eSpeak
NG
eSpeak NG(Next Generation)是一个开源、紧凑的文本转语音(TTS)引擎,是eSpeak的一个分支。eSpeak
NG继承了eSpeak的主要特点,包括对多种语言的支持和在多个平台上运行的能力。
这个TTS引擎因其小巧的体积、广泛的语言支持以及可在不同操作系统中运行的灵活性而受到推崇。
支持 Linux 和 Windows、Android 和其他操作系统,支持多种语言和口音,包括中文普通话,并附带许多有用的功能,这使其成为许多用户的理想选择。
GitHub:https://github.com/espeak-ng/espeak-ng
出自:https://mp.weixin.qq.com/s/JBomyU0qsy0teqn5QQe3nw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip