字节跳动推出AI模型PersonaTalk,可精准同步视频配音与人物口型,保留个性特征,快速适配多场景,通过双重注意力机制实现细节之美,远超同类模型,但限制在科研机构使用,为视频创作带来便利和可能性。
字节跳动最近推出了一款名为PersonaTalk的AI模型,这项黑科技让视频配音彻底摆脱了传统的“僵硬感”。只需提供一段音频和一个视频,PersonaTalk便能精准同步人物的口型,不仅让声音和嘴型无缝贴合,还能保留视频中人物的表情和个性化说话风格,仿佛原生发声一般自然流畅。

PersonaTalk的“神同步”魔力
与其他配音技术相比,PersonaTalk有着令人惊叹的同步效果。该模型通过捕捉说话者的嘴型、表情等细节,实现了声音和口型的完美契合。无论是微笑、说话,还是任何面部表情,视频中人物的嘴唇动作都和新配音的语音高度一致。可以说,PersonaTalk在让视频“活起来”这方面功不可没。
1
个性保留,真实感加倍
PersonaTalk不仅仅关注嘴型的同步,还特别强调保留人物原本的面部特征和说话风格,这让视频的逼真度更上一层楼。不论人物的脸型、语气、表情,甚至独特的说话方式都能完美再现,这种个性化处理让视频仿佛是自然发声,而不是后期添加的配音。
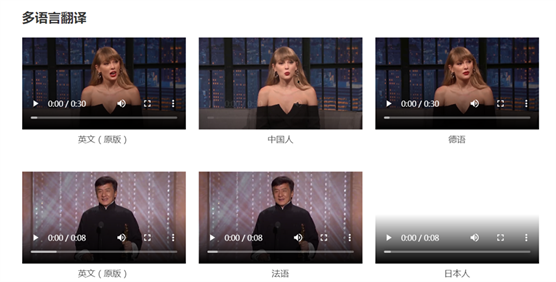
快速适配多场景,让配音更灵活
传统的AI配音技术通常需要针对特定人物进行大量数据训练,而PersonaTalk则不然,它无需为每个人物单独训练,便能适应不同的人物角色和场景,显著提高了使用的便捷性和灵活性。比如在广告、影视、教育等领域,这项技术的应用前景相当广阔。
AI双重注意力机制,细节之美
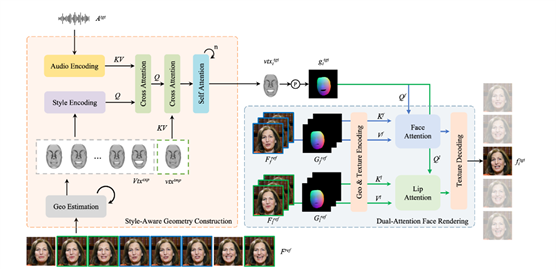
PersonaTalk的实现过程分为几何结构提取和人脸渲染两大部分。第一步,它从参考视频中捕捉人物的几何特征,再将音频特征与几何特征结合,通过个性化的说话风格生成同步口型的目标几何图形。第二步,借助双重注意力机制的人脸渲染器,PersonaTalk将人物面部进行细致渲染,细到嘴唇和面部其他区域的纹理采样,甚至连牙齿闪烁等常见问题都能有效避免,使得生成视频更加自然流畅。
领先技术,展现惊艳效果
从实验结果看,PersonaTalk在视觉效果、口型精度和个性化保留方面,表现远超同类模型,甚至无需额外的微调,就能实现对特定人物的精确配音。然而,值得注意的是,由于数据训练的限制,PersonaTalk在应对非人类形象(如卡通角色)和大幅度面部动作上仍有一定的挑战。
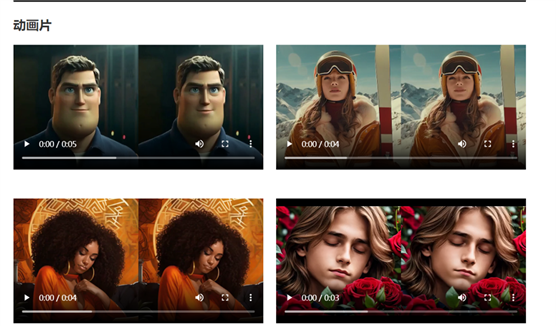
限制开放,保障技术安全
为防止潜在的滥用风险,字节跳动决定将PersonaTalk的访问权限限制在科研机构,以确保该技术能够在合规、可控的环境中进行应用与推广。
项目链接:https://grisoon.github.io/PersonaTalk/
PersonaTalk的出现,为视频创作带来了极大的便利和可能性。未来,我们或许可以见到更多基于这项技术的创意视频,不仅省去了繁琐的人工配音,更为视频增添了生动真实的细节,期待它在更多场景中的精彩表现!
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip