Fish Speech是Fish Audio开发的开源文本到语音(TTS)工具,支持多语言,通过70万小时数据训练实现高质量语音合成,具有低显存需求、快速推理、高自定义性等特性,包括零样本/小样本TTS、语音克隆、无音素依赖等能力。文章还介绍了Fish Speech的本地搭建方法,包括环境要求、安装步骤和推理实战,效果接近官网服务。
Fish Speech是一款由Fish Audio开发的开源的文本到语音(TTS)工具,支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
通过约70万小时的多语种数据训练,实现了接近人类水平的语音合成效果,目前已更新到1.4版本。
该工具特点包括低显存需求(仅需4GB)、快速推理速度、高自定义性和灵活性,用户可快速进行

1. 零样本 & 小样本 TTS:输入 10 到 30 秒的声音样本即可生成高质量的 TTS 输出。详见 语音克隆最佳实践指南[https://docs.fish.audio/text-to-speech/voice-clone-best-practices]。
2. 高效的文本到语音转换:Fish Speech利用先进的算法,能够迅速将输入的文本信息转换成听起来自然、流畅的语音。通过优化的声学模型和语言模型,确保语音的自然度和准确性,使其在多种场景下都能提供高质量的语音输出。
3. 多语言 & 跨语言支持:只需复制并粘贴多语言文本到输入框中,无需担心语言问题。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
4. 语音克隆能力:用户可以上传自己或他人的一段语音作为参考,Fish Speech通过深度学习技术,学习并模仿该语音的特征,实现个性化的语音克隆。该功能在个性化语音助手、有声读物制作等领域具有广泛的应用潜力。
5. 无音素依赖:模型具备强大的泛化能力,不依赖音素进行 TTS,能够处理任何文字表示的语言。
6. 高准确率:在 5 分钟的英文文本上,达到了约 2% 的 CER(字符错误率)和 WER(词错误率)。
7. 快速:通过 fish-tech 加速,在 Nvidia RTX 4060 笔记本上的实时因子约为 1:5,在 Nvidia RTX 4090 上约为 1:15。
8. 低显存需求:仅需4GB显存即可运行,大大降低了硬件门槛,使得更多的用户能够在自己的电脑上使用Fish
Speech,而不必投资昂贵的硬件设备。
9. 微调能力:LORA微调技术允许用户对模型进行细致的调整,以适应特定的语音风格或表达方式,为用户提供了更多的创造性空间。
10. WebUI 推理:提供易于使用的基于 Gradio 的网页用户界面,兼容 Chrome、Firefox、Edge
等浏览器。
11. GUI 推理:提供 PyQt6 图形界面,与 API 服务器无缝协作。支持 Linux、Windows 和 macOS。查看
GUI[https://github.com/AnyaCoder/fish-speech-gui]。
12. 易于部署:轻松设置推理服务器,原生支持 Linux、Windows 和
macOS,最大程度减少速度损失。
Fish Speech官网入口
- 官网:https://speech.fish.audio/
- GIthub:https://github.com/fishaudio/fish-speech
- 模型:https://hf-mirror.com/fishaudio/fish-speech-1.4
- Demo:
https://huggingface.co/spaces/fishaudio/fish-speech-1
最新模型 V1.4 支持的语言以及其训练的时间
- 英语 (en) ~30 万小时
- 中文 (zh) ~30 万小时
- 德语 (de) ~20,000 小时
- 日语 (ja) ~20,000 小时
- 法语 (fr) ~20,000 小时
- 西班牙语 (es) ~20,000 小时
- 韩语 (ko) ~20,000 小时
- 阿拉伯语 (ar) ~20,000 小时
模型非常的小,还不到 1G:
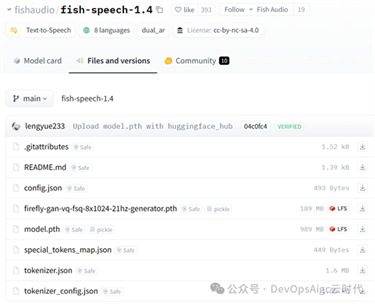
官方注册用户,有:每日50配额,也足够轻量使用,而且有好多训练好的声音,直接使用。入口:https://speech.fish.audio/
今天我们就来本地搭建一下,看看能否达到官方服务的效果。
要求
- GPU 内存: 4GB (用于推理), 8GB (用于微调)
- 系统: Linux, Windows
安装miniconda
请参考之前的文章,这里不再赘述:
创建Python环境,并安装依赖
创建python 3.11 环境,并进入环境:
1 conda create -n fish-speech python=3.11
2 conda activate fish-speech
安装依赖
1
2 # 安装 torch
3 pip install torch==2.4.1+cu124 torchvision==0.19.1+cu124
torchaudio==2.4.1+cu124 --index-url https://download.pytorch.org/whl/cu124
4
5 # 安装项目依赖
6 git clone
https://github.com/fishaudio/fish-speech.git
7 cd
fish-speech
8 pip install -e .
9
10 # 开启编译加速
安装triton-windows
11 pip install
https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
安装编辑加速
1. 安装LLVM 17.0.6 下载地址:https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true
·
下载完 LLVM-17.0.6-win64.exe 后,双击进行安装,选择合适的安装位置,最重要的是勾选 Add
Path to Current User 添加环境变量。
2. 下载安装 Microsoft Visual C++ 可再发行程序包,解决潜在 .dll 丢失问题。
下载地址:https://aka.ms/vs/17/release/vc_redist.x64.exe
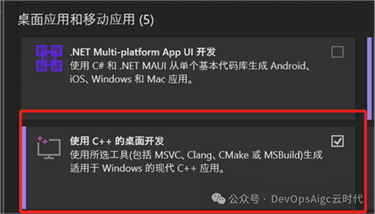
3. 下载安装 Visual Studio 社区版以获取 MSVC++ 编译工具, 解决
LLVM 的头文件依赖问题。
·
·
·
下载地址:https://visualstudio.microsoft.com/zh-hans/downloads/
·
安装好 Visual Studio Installer 之后,下载 Visual Studio Community 2022
·
如下图点击修改按钮,找到使用C++的桌面开发项,勾选下载:
f.
下载安装 CUDA Toolkit
12.x[https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64]
4. 双击 start.bat 打开训练推理 WebUI 管理界面.
想启动
推理 WebUI 界面?编辑项目根目录下的 API_FLAGS.txt, 前三行修改成如下格式:
--infer
#--api
#--listen ...
...
想启动 API 服务器?编辑项目根目录下的 API_FLAGS.txt, 前三行修改成如下格式:
# --infer
--api
--listen ...
...
其他Linux、Mac 环境的安装请参考官方文档:https://speech.fish.audio/zh

打开:推理配置,然后打开:打开推理服务器,如下图:
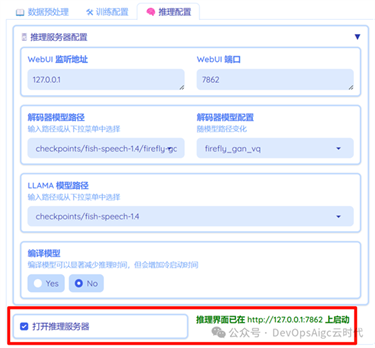
然后打开,右侧提示的网址:http://127.0.0.1:7862,如下图所示:
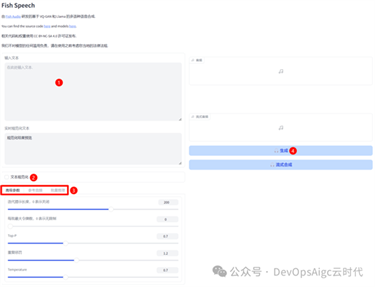
随机音色推理:
1. 输入要朗读的文本
2. 点击文本规范化,进行规范
3. 调整参数
4. 生成
如果需要克隆音色:请选择:“参考音频”,如下图:
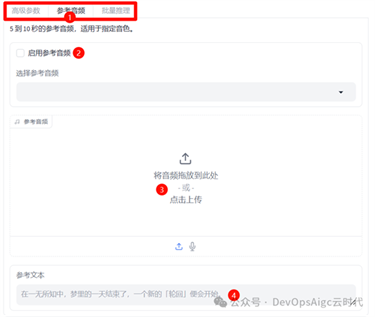
步骤如下:
1. 选择“参考音频”
2. 启用参考音频
3. 上传参考音频
4. 输入参考音频对应的文本
还是拿之前太乙真人的音频进行测试,同样的长文本:
1 有一个小镇很久没有下雨了,令当地农作物损失惨重,于是牧师把大家集合起来,准备在教堂里开一个祈求降雨的祷告会。人群中有一个小女孩,因个子太小,几乎没有人看得到她,但她也来参加祈雨祷告会。
2
3 就在这时候,牧师注意到小女孩所带来的东西,激动地在台上指着她:“那位小妹妹很让我感动!”于是大家顺着他手指的方向看了过去。
4
5 牧师接着说:“我们今天来祷告祈求上帝降雨,可是整个会堂中,只有她一个人今天带着雨伞!”大家仔细一看,果然,她的座位旁挂了一把红色的小雨伞;这时大家沉静了一下,紧接而来的,是一阵掌声与泪水交织的美景。
6
7 有时我们不得不说:小孩子其实一点都不小,他们其实很大!他们的爱心很大!他们的信心很大!
太乙真人原始音色:
太乙真人-原声音,DevOpsAigc云时代,12秒
生成后的:
fishspeech-太乙-祈雨祷告会,DevOpsAigc云时代,1分钟
显存占用:2.2G
个人感觉,效果非常的好,支持长文本,错字非常少,基本上跟官网的效果是一样的
再来个女解说:
原始音色:
女解说-原语音,DevOpsAigc云时代,22秒
生成后的:
fishspeech-女解说-祈雨祷告会,DevOpsAigc云时代,1分钟
个人感觉,效果也很好,就是差点感情
注意:
个人感觉,推理速度很快,效果也挺好,就没有必要进行训练微调了,有兴趣的朋友,可以自行研究。类似于官网,训练某个人的声音,直接生成模型,后期直接拿来使用,而无需在上传参考音频了。
原文出自:https://mp.weixin.qq.com/s/Phd80Wy7sxs7Yec5Gxpkxg
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip