一、前言
大家好,我是 Jack。
本文是图解 AI 算法系列教程的第二篇,今天的主角是 Transformer。
Transformer 可以做很多有趣而又有意义的事情。
比如我写过的《用自己训练的AI玩王者荣耀是什么体验?》。
再比如 OpenAI 的 DALL·E,可以魔法一般地按照自然语言文字描述直接生成对应图片!
输入文本:鳄梨形状的扶手椅。
AI 生成的图像:

两者都是多模态的应用,这也是各大巨头的跟进方向,可谓大势所趋。
Transformer 最初主要应用于一些自然语言处理场景,比如翻译、文本分类、写小说、写歌等。
随着技术的发展,Transformer 开始征战视觉领域,分类、检测等任务均不在话下,逐渐走上了多模态的道路。

Transformer 近两年非常火爆,内容也很多,要想讲清楚,还涉及一些基于该结构的预训练模型,例如著名的 BERT,GPT,以及刚出的 DALL·E 等。
它们都是基于 Transformer 的上层应用,因为 Transformer 很难训练,巨头们就肩负起了造福大众的使命,开源了各种好用的预训练模型。
我们都是站在巨人肩膀上学习,用开源的预训练模型在一些特定的应用场景进行迁移学习。
篇幅有限,本文先讲解 Transformer 的基础原理,希望每个人都可以看懂。
后面我会继续写 BERT、GPT 等内容,更新可能慢一些,但是跟着学,绝对都能有所收获。
还是那句话:如果你喜欢这个 AI 算法系列教程,一定要让我知道,转发在看支持,更文更有动力!
二、Transformer
Transformer 是 Google 在 2017 年提出的用于机器翻译的模型。

Transformer 的内部,在本质上是一个 Encoder-Decoder 的结构,即 编码器-解码器。

Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
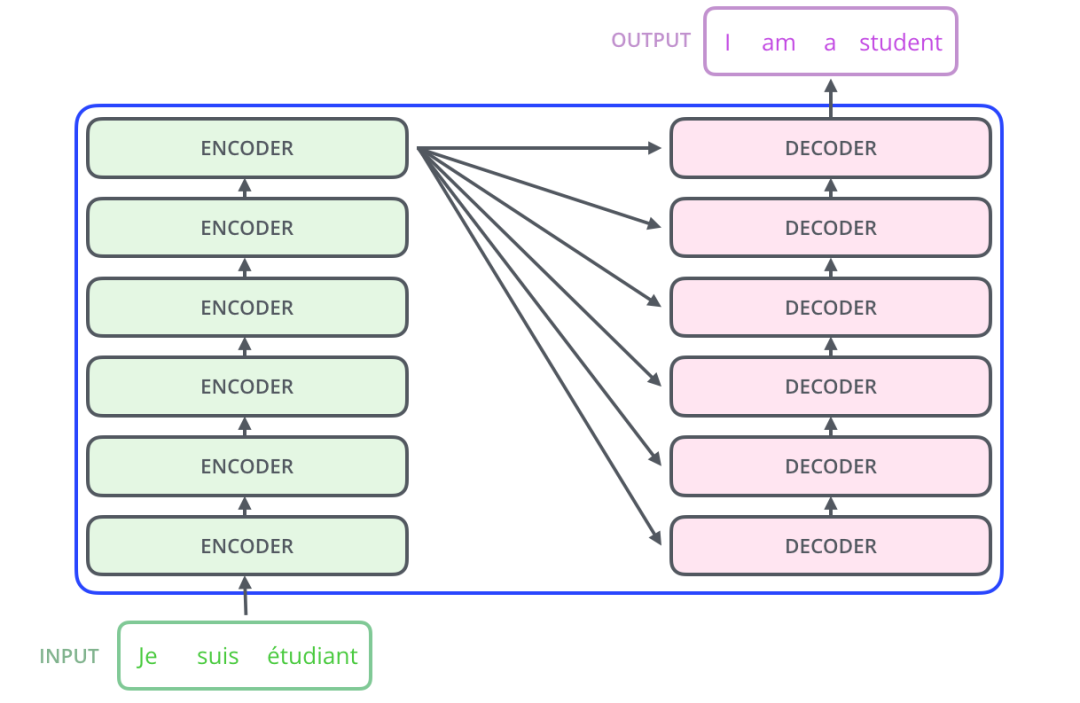
显然,Transformer 主要分为两大部分,分别是编码器和解码器。
整个 Transformer 是由 6 个这样的结构组成,为了方便理解,我们只看其中一个Encoder-Decoder 结构。
以一个简单的例子进行说明:

Why do we work?,我们为什么工作?
左侧红框是编码器,右侧红框是解码器,
编码器负责把自然语言序列映射成为隐藏层(上图第2步),即含有自然语言序列的数学表达。
解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,如情感分析、机器翻译、摘要生成、语义关系抽取等。
简单说下,上图每一步都做了什么:
- 输入自然语言序列到编码器: Why do we work?(为什么要工作);
- 将得到的第二字再落下来,直到解码器输出 <𝑒𝑛𝑑> (终止符),即序列生成完成。
解码器和编码器的结构类似,本文以编码器部分进行讲解。即把自然语言序列映射为隐藏层的数学表达的过程,因为理解了编码器中的结构,理解解码器就非常简单了。
为了方便学习,我将编码器分为 4 个部分,依次讲解。
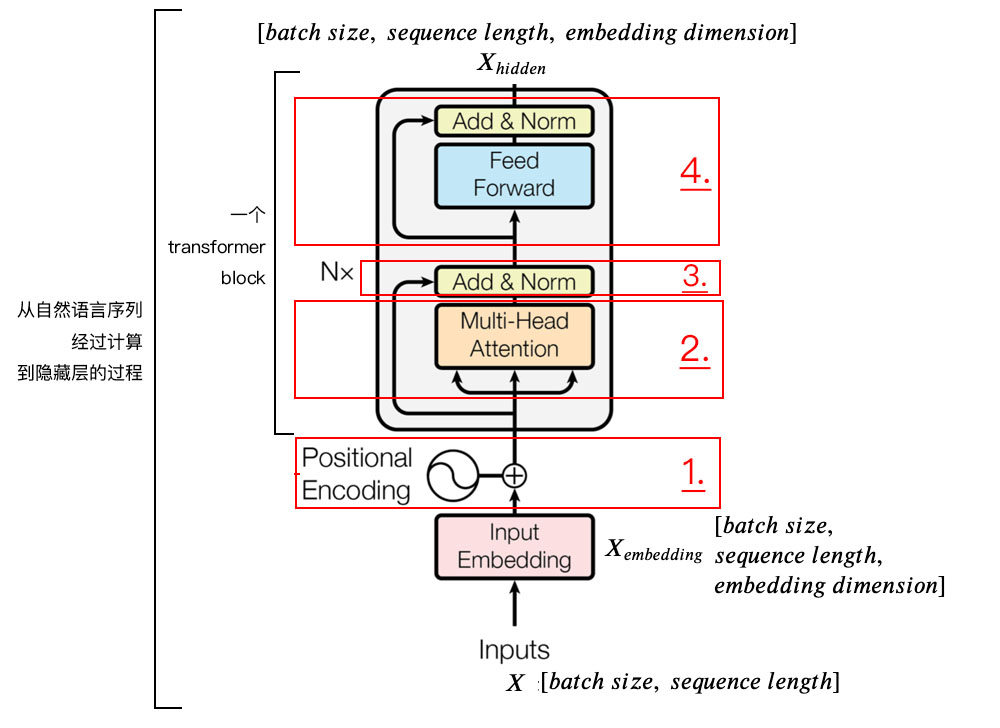
1、位置嵌入(𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑎𝑙 𝑒𝑛𝑐𝑜𝑑𝑖𝑛𝑔)
我们输入数据 X 维度为[batch size, sequence length]的数据,比如我们为什么工作。
batch size 就是 batch 的大小,这里只有一句话,所以 batch size 为 1,sequence length 是句子的长度,一共 7 个字,所以输入的数据维度是 [1, 7]。
我们不能直接将这句话输入到编码器中,因为 Tranformer 不认识,我们需要先进行字嵌入,即得到图中的 Xembedding 。
简单点说,就是文字->字向量的转换,这种转换是将文字转换为计算机认识的数学表示,用到的方法就是 Word2Vec,Word2Vec 的具体细节,对于初学者暂且不用了解,这个是可以直接使用的。
得到的 Xembedding 的维度是 [batch size, sequence length, embedding dimension],embedding dimension 的大小由 Word2Vec 算法决定,Tranformer 采用 512 长度的字向量。所以 Xembedding 的维度是 [1, 7, 512]。
至此,输入的我们为什么工作,可以用一个矩阵来简化表示。

我们知道,文字的先后顺序,很重要。
比如吃饭没、没吃饭、没饭吃、饭吃没、饭没吃,同样三个字,顺序颠倒,所表达的含义就不同了。
文字的位置信息很重要,Tranformer 没有类似 RNN 的循环结构,没有捕捉顺序序列的能力。
为了保留这种位置信息交给 Tranformer 学习,我们需要用到位置嵌入。
加入位置信息的方式非常多,最简单的可以是直接将绝对坐标 0,1,2 编码。
Tranformer 采用的是 sin-cos 规则,使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
PE(pos,2i)PE(pos ,2i+1)=sin(pos/100002i/dmodel )=cos( pos /100002i/dmodel )
上式中 pos 指的是句中字的位置,取值范围是 [0, 𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ),i 指的是字嵌入的维度, 取值范围是 [0, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛)。 就是 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 的大小。
上面有 sin 和 cos 一组公式,也就是对应着 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 维度的一组奇数和偶数的序号的维度,从而产生不同的周期性变化。
可以用代码,简单看下效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 导入依赖库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
# 归一化, 用位置嵌入的每一行除以它的模长
# denominator = np.sqrt(np.sum(position_enc**2, axis=1, keepdims=True))
# position_enc = position_enc / (denominator + 1e-8)
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
|
可以看到,位置嵌入在 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 (也是hidden dimension )维度上随着维度序号增大,周期变化会越来越慢,而产生一种包含位置信息的纹理。
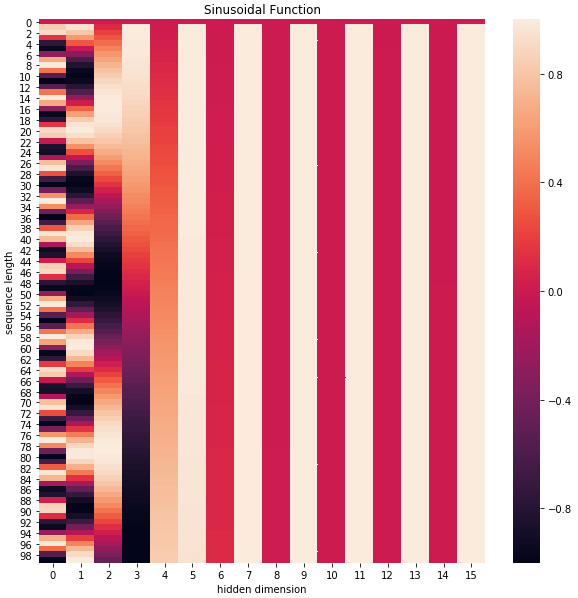
就这样,产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
最后,将 Xembedding 和 位置嵌入 相加,送给下一层。
2、自注意力层(𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑚𝑒𝑐ℎ𝑎𝑛𝑖𝑠𝑚)
直接看下图笔记,讲解的非常详细。
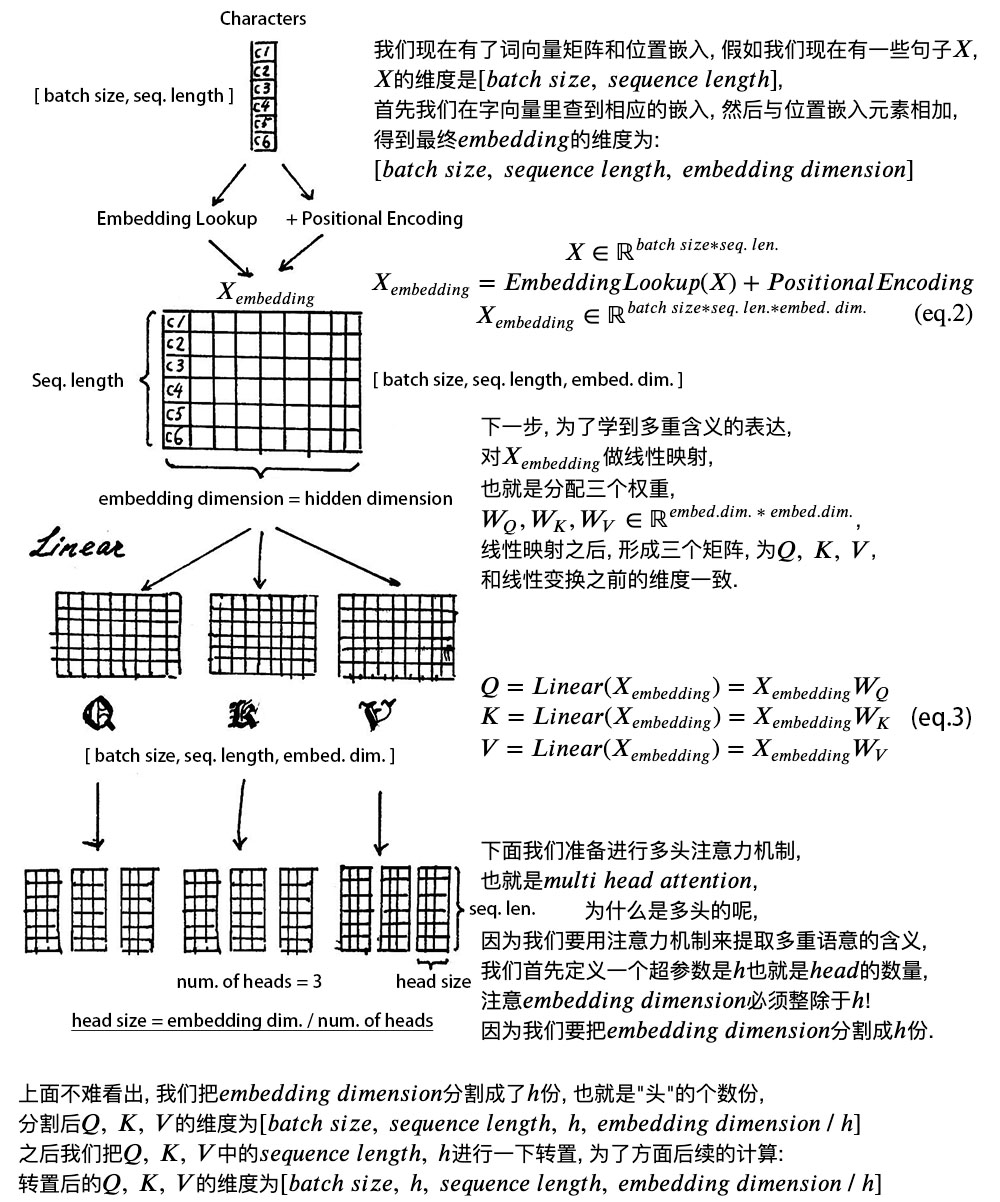
多头的意义在于,QKT 得到的矩阵就叫注意力矩阵,它可以表示每个字与其他字的相似程度。因为,向量的点积值越大,说明两个向量越接近。
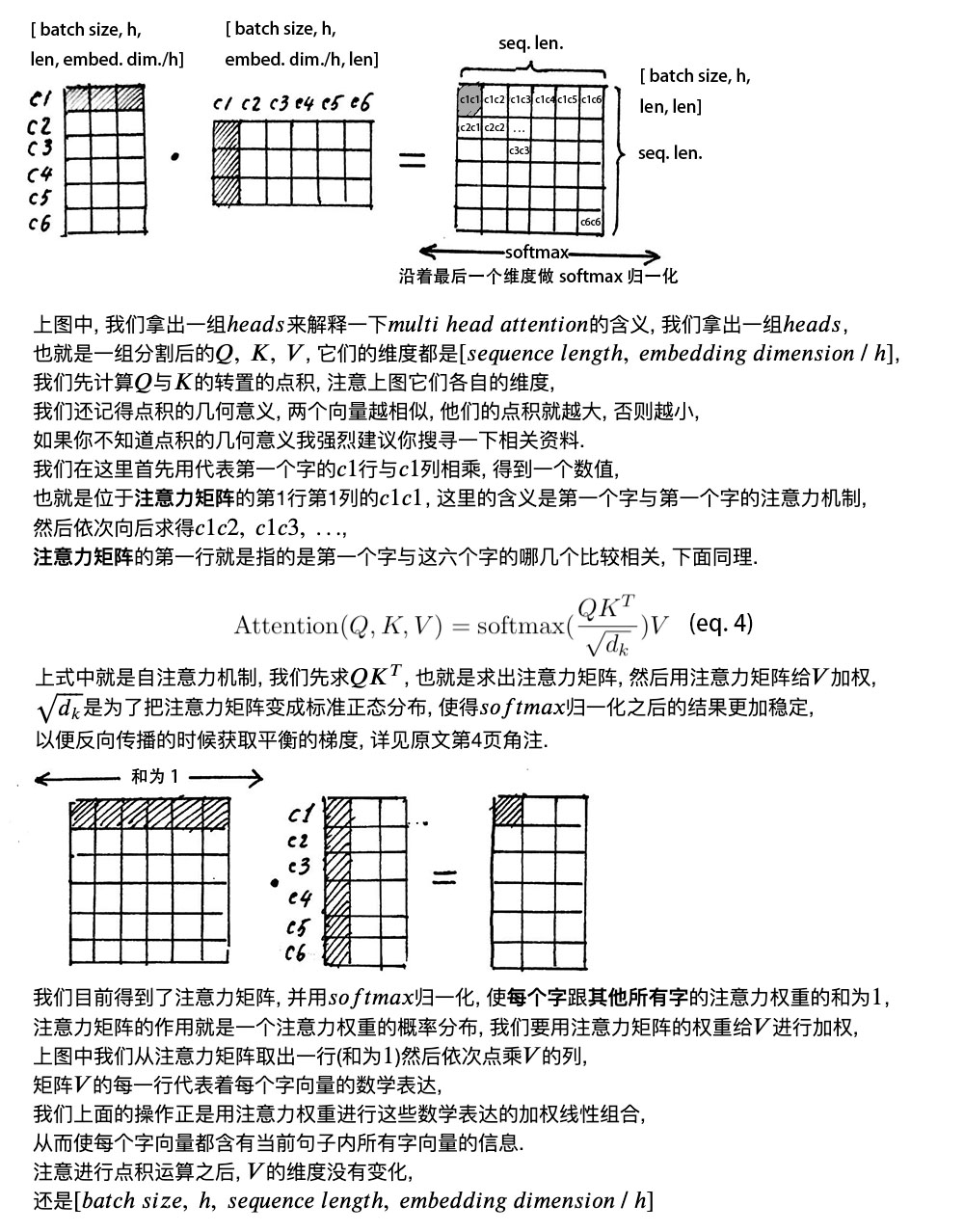
我们的目的是,让每个字都含有当前这个句子中的所有字的信息,用注意力层,我们做到了。
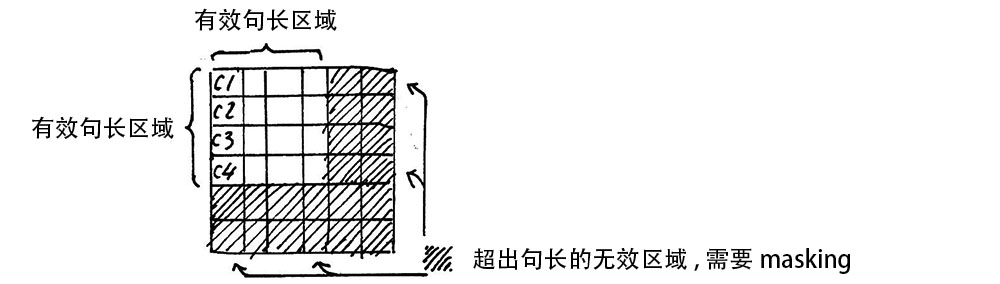
需要注意的是,在上面 𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 的计算过程中,我们通常使用 𝑚𝑖𝑛𝑖 𝑏𝑎𝑡𝑐ℎ,也就是一次计算多句话,上文举例只用了一个句子。
每个句子的长度是不一样的,需要按照最长的句子的长度统一处理。对于短的句子,进行 Padding 操作,一般我们用 0 来进行填充。
3、残差链接和层归一化
加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
1) 残差设计
我们在上一步得到了经过注意力矩阵加权之后的 𝑉, 也就是 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄, 𝐾, 𝑉),我们对它进行一下转置,使其和 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 的维度一致, 也就是 [𝑏𝑎𝑡𝑐ℎ 𝑠𝑖𝑧𝑒, 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛] ,然后把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致:
Xembedding+Attention(Q, K, V)
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
X+SubLayer(X)
2) 层归一化
作用是把神经网络中隐藏层归一为标准正态分布,也就是 𝑖.𝑖.𝑑 独立同分布, 以起到加快训练速度, 加速收敛的作用。
μi=1m∑i=1mxij
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求均值:
σ2j=1m∑i=1m(xij−μj)2
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求方差:
LayerNorm(x)=α⊙xij−μiσ2i+ϵ−−−−−√+β
然后用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归一化后的数值,ϵ是为了防止除0;
之后引入两个可训练参数α, β来弥补归一化的过程中损失掉的信息,注意⊙表示元素相乘而不是点积,我们一般初始化[/latex]\alpha[/latex]为全[/latex]1[/latex],而β为全0。
代码层面非常简单,单头 attention 操作如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# self.temperature是论文中的d_k ** 0.5,防止梯度过大
# QxK/sqrt(dk)
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 屏蔽不想要的输出
attn = attn.masked_fill(mask == 0, -1e9)
# softmax+dropout
attn = self.dropout(F.softmax(attn, dim=-1))
# 概率分布xV
output = torch.matmul(attn, v)
return output, attn
|
Multi-Head Attention 实现在 ScaledDotProductAttention 基础上构建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
# n_head头的个数,默认是8
# d_model编码向量长度,例如本文说的512
# d_k, d_v的值一般会设置为 n_head * d_k=d_model,
# 此时concat后正好和原始输入一样,当然不相同也可以,因为后面有fc层
# 相当于将可学习矩阵分成独立的n_head份
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
# 假设n_head=8,d_k=64
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# d_model输入向量,n_head * d_k输出向量
# 可学习W^Q,W^K,W^V矩阵参数初始化
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
# 最后的输出维度变换操作
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# 单头自注意力
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# 假设qkv输入是(b,100,512),100是训练每个样本最大单词个数
# 一般qkv相等,即自注意力
residual = q
# 将输入x和可学习矩阵相乘,得到(b,100,512)输出
# 其中512的含义其实是8x64,8个head,每个head的可学习矩阵为64维度
# q的输出是(b,100,8,64),kv也是一样
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 变成(b,8,100,64),方便后面计算,也就是8个头单独计算
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
# 输出q是(b,8,100,64),维持不变,内部计算流程是:
# q*k转置,除以d_k ** 0.5,输出维度是b,8,100,100即单词和单词直接的相似性
# 对最后一个维度进行softmax操作得到b,8,100,100
# 最后乘上V,得到b,8,100,64输出
q, attn = self.attention(q, k, v, mask=mask)
# b,100,8,64-->b,100,512
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# 残差计算
q += residual
# 层归一化,在512维度计算均值和方差,进行层归一化
q = self.layer_norm(q)
return q, attn
|
4、前馈网络
这个层就没啥说的了,非常简单,直接看代码吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
# 两个fc层,对最后的512维度进行变换
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
|
最后,回顾下 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 𝑒𝑛𝑐𝑜𝑑𝑒𝑟 的整体结构。
经过上文的梳理,我们已经基本了解了 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 编码器的主要构成部分,我们下面用公式把一个 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 𝑏𝑙𝑜𝑐𝑘 的计算过程整理一下:
1) 字向量与位置编码
X=EmbeddingLookup(X)+PositionalEncoding
X∈Rbatch size ∗ seq. len. ∗ embed. dim.
2) 自注意力机制
Q=Linear(X)=XWQ
K=Linear(X)=XWK
V=Linear(X)=XWV
Xattention=SelfAttention(Q, K, V)
3) 残差连接与层归一化
Xattention=X+Xattention
Xattention=LayerNorm(Xattention)
4) 前向网络
其实就是两层线性映射并用激活函数激活,比如说ReLU:
Xhidden=Activate(Linear(Linear(Xattention)))
5) 重复3)
Xhidden=Xattention+Xhidden
Xhidden=LayerNorm(Xhidden)
Xhidden∈Rbatch size ∗ seq. len. ∗ embed. dim.
三、絮叨
至此,我们已经讲完了 Transformer 编码器的全部内容,知道了如何获得自然语言的位置信息,注意力机制的工作原理等。
本文以原理讲解为主,后续我会继续更新实战内容,教大家如何训练我们自己的有趣又好玩的模型。