黑话
| 缩写/术语 |
解释 |
| oneshot |
一张图 |
| LAION |
一个图像数据集库 https://laion.ai |
| aug (augmentaion) |
通过裁切、翻转获取更多数据集的方式 |
| ucg |
unconditional guidance |
| ML |
机器学习 |
| Latent Space |
潜在空间 |
| LDM |
Latent Diffusion Model 潜在扩散模型 |
| 缩写 |
解释 |
| NAI |
(NovelAI ,一般特指泄露模型) |
| 咒语/念咒 |
提示词组合 (prompts) |
| 施法/吟唱/t2i |
文本转图像 (txt2img) |
| i2i |
图像转图像 (img2img) |
| 魔杖 |
图像生成所涉及到的参数 |
| inpaint/outpaint |
局部重绘,一种 img2img 的方法 |
| ti/emb/嵌入模型 |
模型微调方法中的 Textual Inversion,一般特指 Embedding 插件 |
| hn/hyper |
模型微调方法中的 hypernetwork,超网络 |
| 炸炉 |
指训练过程中过度拟合,但炸炉前的日志插件可以提取二次训练 |
| 废丹 |
指完全没有训练成功 |
| 美学/ext |
Aesthetic Embeddings,一种嵌入模型,特性是训练飞快,但在生产图片时实时计算。 |
| db/梦展 |
DreamBooth,目前一种性价比高(可以在极少步数内完成训练)的微调方式,但硬件要求过高 |
| ds |
DeepSpeed,微软开发的训练方式,移动不需要的组件到内存来降低显存占用,可使 db 的 vram 需求降到 8g 以下。开发时未考虑 win,目前在 win 有兼容性问题故不可用 |
| 8bit/bsb |
一般指 Bitsandbyte,一种 8 比特算法,能极大降低 vram 占用,使 16g 可用于训练 db。由于链接库问题,目前/预计未来在 win 不可用 |
损失
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。例如,线性回归模型通常将均方误差用于损失函数,而逻辑回归模型则使用对数损失函数。
损失函数
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。 在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
关于 损失函数 (Archive)
潜在空间
压缩数据的表示,其中相似的数据点在空间上更靠近在一起。
关于潜在空间的中文解释见 理解机器学习中的潜在空间。
过拟合 (Overfitting)
创建的模型与训练数据过于匹配,以致于模型无法根据新数据做出正确的预测。
收敛 (Convergence)
通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
ENSD
在设置页中的 eta noise seed delta 是 eta 噪声种子增量。
它对处理你种子的操作增加了一些偏移量。
NovelAI 官方在此处使用 31337。
CLIP
CLIP 是一个非常先进的神经网络,可以将提示词文字转换为数字表示。神经网络在这种数值上工作得很好,这就是为什么 SD 的开发人员选择 CLIP 作为 Stable Diffusion 生成图像方法中涉及的 3 个模型之一。由于 CLIP 是一个神经网络,这意味着它有很多层。您的提示词以一种简单的方式被数字化,然后经过网络层层处理。在第一层之后得到的运算结果,会输入第二层,结果再输入第三层,等等,直到到达最后一层,这就是 SD 中 CLIP 模型的使用方法。Stop At last layers of CLIP model 滑块的默认值是 1,代表通过 CLIP 神经网络的所有运算层。但是您可以提前结束运算,直接使用倒数第二层的输出 - 即滑块值 2。您停止的越早,神经网络在提示词上工作的层数就越少。
> https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#ignore-last-layers-of-clip-model
要让 AI 作画,先要让程序“听懂”你的指令,比如
text
a big cherry tree above a lake with flying petals in the sky.
对一个相对复杂场景的文本描述,AI 需要能“理解”并匹配到对应的画面,大部分项目依赖的都是一个叫 CLIP 的模型。
CLIP 在生成模型的潜在空间进行搜索,从而找到与给定的文字描述相匹配的潜在图像。
它非常现代且高效。
CUDA
配合 CUDA 技术,显卡可以模拟成一颗 PhysX 物理加速芯片。
使用 CUDA 技术,GPU 可以用来进行通用处理(不仅仅是图形);这种方法被称为 GPGPU。与 CPU 不同的是,GPU 以较慢速度并发大量线程,而非快速执行单一线程。以 GeForce 8800 GTX 为例,其核心拥有 128 个内处理器。利用 CUDA 技术,就可以将那些内处理器做为线程处理器,以解决数据密集的计算。
LDM
Latent Diffusion Model 潜在扩散模型。
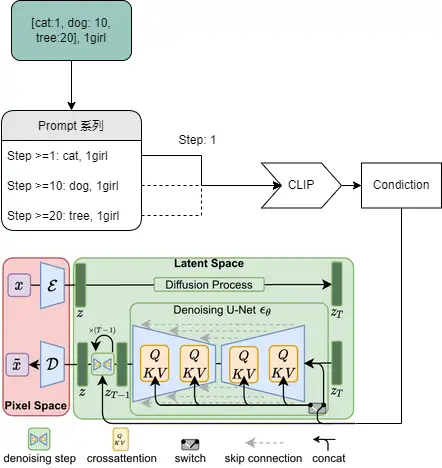
下面的框
潜在扩散模型
VAE
Variational autoencoders (VAEs) 是一种用于学习潜在表示的深度学习技术。它们也被用来绘制图像,在半监督学习中取得最先进的成果,以及在句子之间进行插值。
VAE 作为一个生成模型,其基本思路是把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。那 VAE (变分自编码器) 就是在自编码器模型上做进一步变分处理,使得编码器的输出结果能对应到目标分布的均值和方差。
详见 变分自编码器 (Archive)
CFG
这个词汇为 Classifier Free Guidance Scale 的缩写,用于衡量模型“生成的预期图片和你的提示保持一致”的程度。 CFG Scale 值为 0 时,会生成一个基于种子的随机图像。
打个比方,想象你的提示是一个带有可变宽度光束的手电筒,你将它照到模型的潜在空间上以突出显示特定区域——你的输出图像将从该区域内的某个地方绘制,具体取决于种子。
将 CFG Scale 拨向 零会产生极宽的光束 ,突出显示整个潜在空间——您的输出几乎可以来自任何地方。
将 CFG Scale 拨向 20 会产生非常窄的光束, 以至于在极端情况下它会变成激光指示器,照亮潜在空间中的一个点。
论文地址
超参数 (Hyperparameter)
机器学习算法的参数。示例包括在决策林中学习的树的数量,或者梯度下降算法中的步长。在对模型进行定型之前,先设置超参数的值,并控制查找预测函数参数的过程,例如,决策树中的比较点或线性回归模型中的权重。有关详细信息,见 Wikipedia.
管线 (Pipeline)
要将模型与数据集相匹配所需的所有操作。管线由数据导入、转换、特征化和学习步骤组成。对管线进行定型后,它会转变为模型。
代次 (Epoch)
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次规模)次训练迭代,其中 N 是样本总数。
Batch size
一个批次中的样本数。例如,SGD 的批次规模为 1,而小批次的规模通常介于 10 到 1000 之间。批次规模在训练和推断期间通常是固定的;不过,TensorFlow 允许使用动态批次规模。
迭代 (Iteration)
模型的权重在训练期间的一次更新。迭代包含计算参数在单个批量数据上的梯度损失。
Tensor
TensorFlow 程序中的主要数据结构。张量是 N 维(其中 N 可能非常大)数据结构,最常见的是标量、向量或矩阵。张量的元素可以包含整数值、浮点值或字符串值。
检查点 (Checkpoint)
一种数据,用于捕获模型变量在特定时间的状态。借助检查点,可以导出模型权重,跨多个会话执行训练,以及使训练在发生错误之后得以继续(例如作业抢占)。请注意,图本身不包含在检查点中。
Embeddings
一种分类特征,以连续值特征表示。通常,嵌入是指将高维度向量映射到低维度的空间。例如,您可以采用以下两种方式之一来表示英文句子中的单词:
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都包含一个介于 0 到 1 之间的浮点值。这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数时一样。
激活函数
一种函数(例如 ReLU 或 S 型函数),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层。
权重 (Weight)
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。