原文:https://zhuanlan.zhihu.com/p/635710004
1. 开源基座模型对比
大语言模型的训练分为两个阶段:(1)在海量文本语料上的无监督预训练,学习通用的语义表示和世界知识。(2)在小规模数据上,进行指令微调和基于人类反馈的强化学习,更好地对齐最终任务和人类偏好。LIMA[1]证明了LLM的几乎所有知识都是在预训练过程中学习到的,只需要有限的指令微调数据就可以生成高质量的回复。因此,基座模型的性能是至关重要的,如果基座模型的性能不够好,指令微调和强化学习也难以取得很好的效果。
目前,主流的开源大语言模型主要有三个:LLaMA、ChatGLM和BLOOM。基于这三个开源模型,业界进行了指令微调或强化学习,衍生出了许多不同的大模型。下面从训练数据、tokenizer和模型结构上对这三个大语言模型进行比较。
| 模型 |
训练数据 |
训练数据量 |
模型参数量 |
词表大小 |
| LLaMA |
以英语为主的拉丁语系,不包含中日韩文 |
1T/1.4T tokens |
7B、13B、33B、65B |
32000 |
| ChatGLM-6B |
中英双语,中英文比例为1:1 |
1T tokens |
6B |
130528 |
| Bloom |
46种自然语言和13种编程语言,包含中文 |
350B tokens |
560M、1.1B、1.7B、3B、7.1B、176B |
250880 |
| 模型 |
模型结构 |
位置编码 |
激活函数 |
layer norm |
| LLaMA |
Casual decoder |
RoPE |
SwiGLU |
Pre RMS Norm |
| ChatGLM-6B |
Prefix decoder |
RoPE |
GeGLU |
Post Deep Norm |
| Bloom |
Casual decoder |
ALiBi |
GeLU |
Pre Layer Norm |
1.1 LLaMA
LLaMA[2]是Meta提出的大语言模型。训练数据是以英语为主的拉丁语系,另外还包含了来自GitHub的代码数据。训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的,分词之后大约有1400B的tokens。
按照模型参数量,LLaMA模型有7B、13B、33B、65B这四个不同参数规模的模型版本。7B和13B版本使用了1T的tokens进行训练,33B和65B的版本使用了1.4T的tokens进行训练。[3]证明了在给定训练预算的情况下,即使减少模型参数量,只要增加预训练的数据大小和训练时长(更多的训练tokens数),可以达到甚至超过原始大小模型的效果。作为对比,280B的Gopher模型只训练了300B的tokens,176B的BLOOM模型只训练了350B的tokens,GLM-130B只训练了400B的tokens,LLaMA模型则训练了1T/1.4T的tokens,显著增大了训练数据量。从结果来看,虽然LLaMA-13B模型参数量只有GPT3的不到1/10,但在大部分任务上效果都超过了GPT3。
模型结构上,与GPT相同,LLaMA采用了causal decoder-only的transformer模型结构。在模型细节上,做了以下几点改动:
- layer normalization:为了提升训练的稳定性,没有使用传统的post layer norm,而是使用了pre layer Norm。具体地,去除了layer normalization中的偏置项,采用了RMS Norm(即均方根 Norm)。
- 激活函数:没有采用ReLU激活函数,而是采用了SwiGLU激活函数。FFN通常有两个权重矩阵,先将向量从维度d升维到中间维度4d,再从4d降维到d。而使用SwiGLU激活函数的FFN增加了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了
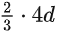 而不是4d。
而不是4d。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码RoPE。
在训练目标上,LLaMA的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,LLaMA的训练语料以英文为主,使用了Sentence Piece作为tokenizer,词表大小只有32000。词表里的中文token很少,只有几百个,LLaMA tokenizer对中文分词的编码效率比较低。
下面是一些基于LLaMA衍生出来的大模型:
- Alpaca:斯坦福大学在52k条英文指令遵循数据集上微调了7B规模的LLaMA。
- Vicuna:加州大学伯克利分校在ShareGPT收集的用户共享对话数据上,微调了13B规模的LLaMA。
- baize:在100k条ChatGPT产生的数据上,对LLaMA通过LoRA微调得到的模型。
- StableLM:Stability AI在LLaMA基础上微调得到的模型。
- BELLE:链家仅使用由ChatGPT生产的数据,对LLaMA进行了指令微调,并针对中文进行了优化。
1.2 词表扩展: Chinese LLaMA
词表扩充的必要性。 LLaMA原模型的词表大小是32000,tokenizer主要是在英文语料上进行训练的,在中文上和多语种上效果比较差。LLaMA在中文上效果差,一方面是由于LLaMA模型是在以英文为主的拉丁语系语料上进行训练的,训练语料不包含中文;另一方面,与tokenizer有关,词表规模小,可能将一个汉字切分为多个token,编码效率低,模型学习难度大。LLaMA词表中只包含了很少的中文字符,在对中文文本进行分词时,会将中文切分地更碎,需要多个token才能表示一个汉字,编码效率很低。扩展中文词表后,单个汉字倾向于被切分为1个token,避免了一个汉字被切分为多个token的问题,提升了中文编码效率。
如何扩展词表呢?[6]尝试扩展词表,将中文token添加到词表中,提升中文编码效率,具体方式如下。
1. 在中文语料上使用Sentence Piece训练一个中文tokenizer,使用了20000个中文词汇。然后将中文tokenizer与原始的 LLaMA tokenizer合并起来,通过组合二者的词汇表,最终获得一个合并的tokenizer,称为Chinese LLaMA tokenizer。词表大小为49953。
2. 为了适应新的tokenizer,将transformer模型的embedding矩阵从 
,新加入的中文token附加到原始embedding矩阵的末尾,确保原始词表表的embedding矩阵不受影响。
3. 在中文语料上进一步预训练,冻结和固定transformer的模型参数,只训练embedding矩阵,学习新加入中文token的词向量表示,同时最小化对原模型的干扰。
4. 在指令微调阶段,可以放开全部模型参数进行训练。
扩展词表的效果。 从Chinese-LLaMA-Alpaca和BELLE的结果来看,扩充中文词表,可以提升中文编码效率,并提升模型性能。
1.3 ChatGLM-6B
ChatGLM-6B是清华大学提出的支持中英双语问答的对话语言模型。ChatGLM-6B采用了与GLM-130B[4]相同的模型结构。截止到2022年7月,GLM-130B只训练了400B的tokens,中英文比例为1:1。ChatGLM-6B则使用了更多的训练数据,多达1T的tokens,训练语料只包含中文和英文,中英文比例为1:1。
模型结构上,ChatGLM-6B采用了prefix decoder-only的transformer模型框架,在输入上采用双向的注意力机制,在输出上采用单向注意力机制。在模型细节上,做了以下几点改动:
- embedding层梯度缩减:为了提升训练稳定性,减小了embedding层的梯度。具体地
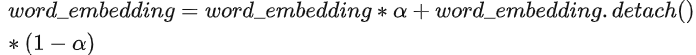
,其中 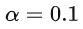 ,这里detach()函数的作用是返回一个新的tensor,并从计算图分离出来。梯度缩减的效果相当于把embedding层的梯度缩小了10倍,减小了梯度的范数。
,这里detach()函数的作用是返回一个新的tensor,并从计算图分离出来。梯度缩减的效果相当于把embedding层的梯度缩小了10倍,减小了梯度的范数。
- layer normalization:采用了基于Deep Norm的post layer norm。
- 激活函数:采用了GeGLU激活函数。相比于普通的FFN,使用线形门控单元的GLU新增了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了
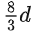 而不是4d。
而不是4d。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码RoPE。
在训练目标上,ChatGLM-6B的训练任务是自回归文本填空。相比于采用causal decoder-only结构的大语言模型,采用prefix decoder-only结构的ChatGLM-6B存在一个劣势:训练效率低。causal decoder结构会在所有的token上计算损失,而prefix decoder只会在输出上计算损失,而不计算输入上的损失。在有相同数量的训练tokens的情况下,prefix decoder要比causal decoder的效果差,因为训练过程中实际用到的tokens数量要更少。另外,ChatGPT的成功已经证明了causal decoder结构的大语言模型可以获得非常好的few-shot和zero-shot生成能力,通过指令微调可以进一步激发模型的能力。至于prefix decoder结构的大语言模型能否获得相当的few-shot和zero-shot能力还缺少足够的验证。
关于tokenizer,ChatGLM在25GB的中英双语数据上训练了SentencePiece作为tokenizer,词表大小为130528。
下面是一些基于ChatGLM衍生出来的大模型应用:
- langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答。
- 闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能。
1.4 BLOOM
BLOOM[5]系列模型是由BigScience团队训练的大语言模型。训练数据包含了英语、中文、法语、西班牙语、葡萄牙语等共46种语言,另外还包含13种编程语言。1.5TB经过去重和清洗的文本,转换为350B的tokens。训练数据的语言分布如下图所示,可以看到中文语料占比为16.2%。
按照模型参数量,BLOOM模型有560M、1.1B、1.7B、3B、7.1B和176B这几个不同参数规模的模型。BLOOMZ系列模型是在xP3数据集上微调得到的,推荐用于英语提示的场景。BLOOMZ-MT系列模型是在xP3mt数据集上微调得到的,推荐用于非英语提示的场景。
模型结构上,与GPT相同,BLOOM采用了causal decoder-only的transformer模型结构。在模型细节上,做了以下几点改动:
- embedding layer norm:在embedding层后添加了一个 layer normalization,来使训练更加稳定。
- layer normalization:为了提升训练的稳定性,没有使用传统的post layer norm,而是使用了pre layer Norm。
- 激活函数:采用了GeLU激活函数。
- 位置编码:去除了绝对位置编码,采用了相对位置编码ALiBi。相比于绝对位置编码,ALiBi的外推性更好,即虽然训练阶段的最大序列长度为2048,模型在推理过程中可以处理更长的序列。
在训练目标上,BLOOM的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,BLOOM在多语种语料上使用Byte Pair Encoding(BPE)算法进行训练得到tokenizer,词表大小为250880。
下面是一些基于BLOOM衍生出来的大模型应用:
- 轩辕: 金融领域大模型,度小满在BLOOM-176B的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。
- BELLE: 链家仅使用由ChatGPT生产的数据,对BLOOMZ-7B1-mt进行了指令微调。
2. 语言模型细节
2.1 tokenizer比较
以上几个基座模型的tokenizer的词表大小不同,对同一个中文文本的分词结果会产生不同的结果。在news_commentary的6.9万条中英文平行语料上进行分词处理,对比分词结果和分词耗时,结果如下。“中文平均token数”表示了tokenizer分词后,每个中文字符对应的平均token数。
| 模型 |
词表大小 |
中文平均token数 |
英文平均token数 |
中文处理时间(s) |
英文处理时间(s) |
| LLaMA |
32000 |
1.45 |
0.25 |
12.60 |
19.40 |
| Chinese LLaMA |
49953 |
0.62 |
0.249 |
8.65 |
19.12 |
| ChatGLM-6B |
130528 |
0.55 |
0.19 |
15.91 |
20.84 |
| Bloom |
250880 |
0.53 |
0.22 |
9.87 |
15.60 |
从结果来看,
- LLaMA的词表是最小的,LLaMA在中英文上的平均token数都是最多的,这意味着LLaMA对中英文分词都会比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着LLaMA大概率会将中文字符切分为2个以上的token。
- Chinese LLaMA扩展词表后,中文平均token数显著降低,会将一个汉字或两个汉字切分为一个token,提高了中文编码效率。
- ChatGLM-6B是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加。
- BLOOM虽然是词表最大的,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。需要注意的是,BLOOM的tokenizer用了transformers的BloomTokenizerFast实现,分词速度更快。
从两个例子上,来直观对比不同tokenizer的分词结果。“男儿何不带吴钩,收取关山五十州。”共有16字。几个tokenizer的分词结果如下:
[ '男', '<0xE5>', '<0x84>', '<0xBF>', '何', '不', '<0xE5>', '<0xB8>', '<0xA6>', '<0xE5>',
'<0x90>', '<0xB4>', '<0xE9>', '<0x92>', '<0xA9>', ',', '收', '取', '关', '山', '五', '十',
'州', '。']
- Chinese LLaMA分词为14个token:
[ '男', '儿', '何', '不', '带', '吴', '钩', ',', '收取', '关', '山', '五十', '州', '。']
[ '男儿', '何不', '带', '吴', '钩', ',', '收取', '关山', '五十', '州', '。']
['男', '儿', '何不', '带', '吴', '钩', ',', '收取', '关', '山', '五十', '州', '。']
“杂申椒与菌桂兮,岂维纫夫蕙茝。”的长度为15字。几个tokenizer的分词结果如下:
[ '<0xE6>', '<0x9D>', '<0x82>', '<0xE7>', '<0x94>', '<0xB3>', '<0xE6>', '<0xA4>',
'<0x92>', '与', '<0xE8>', '<0x8F>', '<0x8C>', '<0xE6>', '<0xA1>', '<0x82>', '<0xE5>',
'<0x85>', '<0xAE>', ',', '<0xE5>', '<0xB2>', '<0x82>', '<0xE7>', '<0xBB>', '<0xB4>',
'<0xE7>', '<0xBA>', '<0xAB>', '夫', '<0xE8>', '<0x95>', '<0x99>', '<0xE8>', '<0x8C>', '<0x9D>', '。']
- Chinese LLaMA分词为17个token:
[ '杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '纫', '夫', '蕙', '<0xE8>',
'<0x8C>', '<0x9D>', '。']
[ '杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '纫', '夫', '蕙', '<0xE8>',
'<0x8C>', '<0x9D>', '。']
['杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '�', '�', '夫', '蕙',
'�', '�', '。']
从上面的例子可以看到,LLaMA词表中包含了极少数的中文字符,常见字“儿”也被切分为了3个token。Chinese LLaMA、ChatGLM-6B和Bloom的词表中则覆盖了大部分中文常见字,另外也包含了一些中文常用词,比如都把“收取”这个词切分为了一个token;对于一些生僻词,比如“茝”也会切分为2-3个token。总的来说,LLaMA通常会将一个中文汉字切分为2个以上的token,中文编码效率低;Chinese LLaMA、ChatGLM-6B和Bloom对中文分词的编码效率则更高。
2.2 Layer Normalization
如下图所示,按照layer normalization的位置不同,可以分为post layer norm和pre layer norm。
post layer norm。在原始的transformer中,layer normalization是放在残差连接之后的,称为post LN。使用Post LN的深层transformer模型容易出现训练不稳定的问题。如下图所示,post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
pre layer norm。[7]改变layer normalization的位置,将其放在残差连接的过程中,self-attention或FFN块之前,称为“Pre LN”。如下图所示,Pre layer norm在每个transformer层的梯度范数近似相等,有利于提升训练稳定性。相比于post LN,使用pre LN的深层transformer训练更稳定,可以缓解训练不稳定问题。但缺点是pre LN可能会轻微影响transformer模型的性能。大语言模型的一个挑战就是如何提升训练的稳定性。为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
layer normalization的计算过程如下:
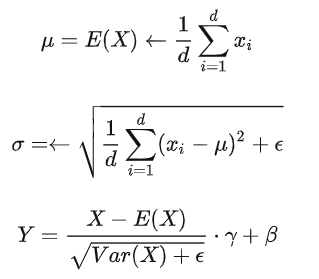

layer normalization重要的两个部分是平移不变性和缩放不变性。 [8]认为layer normalization取得成功重要的是缩放不变性,而不是平移不变性。因此,去除了计算过程中的平移,只保留了缩放,进行了简化,提出了RMS Norm(Root Mean Square Layer Normalization),即均方根norm。计算过程如下: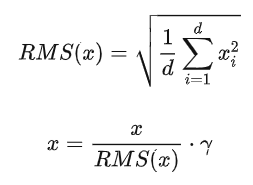
相比于正常的layer normalization,RMS norm去除了计算均值进行平移的部分,计算速度更快,效果基本相当,甚至略有提升。Gopher、LLaMA、T5等大语言模型都采用了RMS norm。

2.3 激活函数

2.4 位置编码
对于transformer模型,位置编码是必不可少的。因为attention模块是无法捕捉输入顺序的,无法区分不同位置的token。位置编码分为绝对位置编码和相对位置编码。
最直接的方式是训练式位置编码,将位置编码当作可训练参数,训练一个位置编码向量矩阵。GPT3就采用了这种方式。训练式位置编码的缺点是没有外推性,即若训练时最大序列长度为2048,在推断时最多只能处理长度为2048的序列,超过这个长度就无法处理了。
苏神[11]提出了旋转位置编码RoPE。训练式的位置编码作用在token embedding上,而旋转位置编码RoPE作用在每个transformer层的self-attention块,在计算完Q/K之后,旋转位置编码作用在Q/K上,再计算attention score。旋转位置编码通过绝对编码的方式实现了相对位置编码,有良好的外推性。值得一提的是,RoPE不包含可训练参数。LLaMA、GLM-130B、PaLM等大语言模型就采用了旋转位置编码RoPE。
ALiBi(Attention with Linear Biases)[12]也是作用在每个transformer层的self-attention块,如下图所示,在计算完attention score后,直接为attention score矩阵加上一个预设好的偏置矩阵。这里的偏置矩阵是预设好的,固定的,不可训练。这个偏置根据q和k的相对距离来惩罚attention score,相对距离越大,惩罚项越大。相当于两个token的距离越远,相互贡献就越小。ALiBi位置编码有良好的外推性。BLOOM就采用了这种位置编码。
3. 高效参数微调方法
随着大语言模型的参数量越来越大,进行大模型的全量微调成本很高。高成本主要体现在硬件资源要求高,显存占用多;训练速度慢,耗时长;存储成本高。高效参数微调(parameter-efficient finetuning techniques,PEFT)在微调大模型时只训练一小部分参数,而不是训练全量多模型参数。高效参数微调方法有以下几方面优点:
- 显存占用少,对硬件资源要求低
- 训练速度快,耗时更短
- 更低的存储成本,不同的任务可以共享大部分的权重参数
- 可能会有更好的模型性能,减轻了过拟合问题
3.1 prompt tuning
prompt tuning[13]原本的含义指的是通过修改输入prompt来获得更好的模型效果。这里的提示是“硬提示(hard prompt)”。我们直接修改输入prompt,输入prompt是不可导的。
与“硬提示”相对应,“软提示微调(soft prompt tuning)”将一个可训练张量与输入文本的embeddings拼接起来,这个可训练张量可以通过反向传播来优化,进而提升目标任务的模型效果。这里的可训练张量可以理解为prompt文本对应的embedding,是一个soft prompt。如下图所示,这个可训练张量的形状是 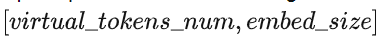 。
。
prompt tuning冻结大模型原始的参数,只训练这个新增加的prompt张量。prompt tuning随着基座模型参数量的增大效果会变好。
3.2 prefix tuning
prefix tuning[14]与prompt tuning相似,将一个特定任务的张量添加到输入,这个张量是可训练的,保持预训练模型的参数不变。主要区别如下:
1. prefix tuning将prefix参数(可训练张量)添加到所有的transformer层,而prompt tuning只将可训练矩阵添加到输入embedding。具体地,prefix tuning会将prefix张量作为past_key_value添加到所有的transformer层。
2. 用一个独立的FFN来编码和优化prefix参数,而不是直接优化soft prompt,因为它可能造成不稳定并损害性能。在更新完soft prompt后,就不再使用FFN了。
prefix tuning与prompt tuning的作用位置不同,有点类似于可训练式位置编码和旋转位置编码RoPE。前者是直接作用在输入embedding上,后者是作用在所有transformer层的self-attention块,在计算得到K和V后,与可训练的prefix张量拼接起来。

3.3 adapter
adapter[16]在某种程度上与prefix tuning是类似的,二者都是把额外的可训练参数添加到每个transformer层。不同之处是:prefix tuning是把prefix添加到输入embedding;而adapter在两个位置插入了adapter 层,如下图所示。
3.4 LLaMA-Adapter
LLaMA-adapter[16]结合了prefix tuning和adapter。与prefix tuning类似,LLaMA-adapter在输入embed上添加了可训练的prompt张量。需要注意的是:prefix是以一个embedding矩阵学习和保持的,而不是外部给出的。每个transformer层都有各自不同的可学习prefix,允许不同模型层进行更量身定制的适应。
如上图所示,LLaMA-adapter引进了零初始化的注意力机制和门控机制。动机是adapter和prefix tuning结合了随机初始化的张量(prefix prompts和adapter layers)很大可能会损害预训练语言模型的语义学知识,导致在训练初始阶段的微调不稳定和很高的性能损失。
另一个重要的区别是,LLaMA-adapter只给L个深层transformer层添加了可学习的adaption prompts,而不是给所有的transformer层都添加。作者认为,这种方法可以更有效的微调专注于高级语义信息的语言表示。
LLaMA-adapter与prefix tuning的基本想法是相关的,都是添加可训练的soft prompts。二者之间存在一些细微差别,添加soft prompt时只修改输入的key和value 序列,而不修改query。另外,取决于门控因子(在训练开始阶段设置为0),决定是否使用prefix修改的注意力机制。
总的来说,LLaMA-adapter与prefix tuning的主要区别是:LLaMA-adapter只修改深层的L个transformer层,并且引入了门控机制来实现稳定训练。尽管LLaMA-adapter是在LLaMA上进行实验的,但它适用于GPT结构的其他大模型。
如下图所示,LLaMA-adapter每个transformer层都有各自不同的可学习参数,一个prefix张量和一个门控因子。prefix张量的形状是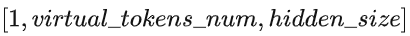
3.5 LoRA
transformer模型中包含了很多进行矩阵乘法的稠密层。有论文认为预训练语言模型存在一个低秩,即使映射到更小的子空间中,依然可以高效地学习。基于这个理论,LoRA(Low-Rank Adaptation)[18]假设模型在适应/微调过程中的权重参数更新也存在一个低的内在维度。

对于LLaMA-6B,采用LoRA在每个transformer层的self-attention块的query和 value上注入旁路模块,可训练参数如下。
4. 高效参数微调实践
huggingface的PEFT库已经实现了上述的这几种高效参数微调方法。在LLaMA-7B、ChatGLM-6B和BLOOM-7B这三个基座模型上尝试不同的高效参数微调方法,对比它们的微调效果。
在单机8卡的40GB A100上进行训练。为了节省显存和加速训练,采用deepspeed框架的ZeRO stage3和CPU offload,开启float16的混合精度训练,不进行激活重计算。设置单卡batch_size为4,最大序列长度为512,梯度累加步数为4,学习率设置为1e-4。在alpaca chinese数据上训练3个epoch。
下图是LLaMA-7B进行高效参数微调和全量微调的损失变化曲线。acc指标衡量了语言模型预测下一个词的准确率。从损失变化曲线来看,对于LLaMA-7B基座模型,prompt tuning和prefix tuning的效果是比较差的,在训练损失上,prompt tuning甚至要好于prefix tuning。这可能是因为prefix tuning在每个transformer层结合了随机初始化的张量,很大可能会损害预训练语言模型的语义学知识,导致微调效果很差。相比于prompt tuning和prefix tuning,LLaMA-adapter的效果有明显提升,这可能得益于LLaMA-adapter引入了门控机制来实现稳定训练。在高效参数微调方法中,LoRA的效果是最好的,从验证损失来看,LoRA的效果只略微逊色于全量参数微调。总的来说,对于LLaMA-7B,全量参数微调 > LoRA > LLaMA-adapter >prompt tuning > prefix tuning。
下图是Chinese LLaMA-7B进行高效参数微调和全量微调的损失变化曲线。Chinese LLaMA-7B是在LLaMA-7B基座模型上进一步预训练得到的。几种轻量化微调方法的效果对比与LLaMA-7B是基本一致的。prompt tuning和prefix tuning的效果是比较差,LLaMA-adapter的效果有明显提升,LoRA的效果与全量参数微调基本相当。
下图是ChatGLM-6B进行高效参数微调和全量微调的损失变化曲线。
从损失变化曲线来看,LoRA的效果甚至要好于全量参数微调。
下图是BLOOM进行高效参数微调和全量微调的损失变化曲线。对于BLOOM-7B基座模型,prefix tuning的效果要略微好于prompt tuning。在验证损失上,prompt tuning和prefix tuning的效果甚至与全量参数微调基本相当。LoRA则取得了比全量参数微调更低的验证损失。
总的来看,汇总四个基座模型的微调损失变化曲线,对于不同的基座模型,全量参数微调的方法都容易出现过拟合问题,随着训练epoch增大,训练损失呈现出阶梯式下降,但验证损失从第三个epoch开始上升。而高效参数微调方法只训练极少数新增参数,冻结预训练语言模型的参数,有效避免了过拟合问题。对于这几种高效参数微调方法,验证损失曲线和训练损失曲线基本是重叠的,走势相同。
对比了不同参数高效微调方法的效果,那哪个基座模型的微调效果要更好呢?不同基座模型的tokenizer和词表大小不同,导致它们之间的训练损失是不可以比较的。下图是不同基座模型上进行LoRA微调的损失变化曲线,由于不可比,没有实际意义。
如下图所示,可以尝试从具体的例子来比较不同基座模型和不同参数高效微调方法的效果。对于LLaMA和Chinese LLaMA模型,prompt tuning和prefix tuning的效果都很差,不能生成流畅通顺的中文回复。虽然LLaMA的预训练数据中不包含中文,但经过指令微调后,仍然能生成不错的中文回复。另外,LoRA微调生成的回复要明显好于LLaMA-adapter的回复。
相比于LLaMA,扩展了词表的Chinese LLaMA微调后生成的回复要更好。这也验证了扩展词表有助于提升LLaMA在中文上的效果。
对于BLOOM,prompt tuning和prefix tuning都可以生成流畅的中文回复,prefix tuning生成的回复要好于prompt tuning。ChatGLM-6B模型生成回复偏短,比较简单。
5. 总结
本文首先从训练数据、tokenizer和模型结构细节上对比了LLaMA、ChatGLM和BLOOM这三个主流的开源大语言模型,并介绍了这三个基座模型的衍生模型;接着详细介绍了不同大语言模型在tokenizer、layer normalization、激活函数和位置编码的模型细节;然后讲述了prompt tuning、prefix tuning、LLaMA- adapter和LoRA这些参数高效微调方法;最后对比了不同基座语言模型和不同微调方法的效果。
6. 参考链接
1. Zhou C, Liu P, Xu P, et al. Lima: Less is more for alignment[J]. arXiv preprint arXiv:2305.11206, 2023.
2. Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
3. Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
4. Zeng A, Liu X, Du Z, et al. Glm-130b: An open bilingual pre-trained model[J]. arXiv preprint arXiv:2210.02414, 2022.
5. Scao T L, Fan A, Akiki C, et al. Bloom: A 176b-parameter open-access multilingual language model[J]. arXiv preprint arXiv:2211.05100, 2022.
6. Cui Y, Yang Z, Yao X. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca[J]. arXiv preprint arXiv:2304.08177, 2023.
7. Xiong R, Yang Y, He D, et al. On layer normalization in the transformer architecture[C]//International Conference on Machine Learning. PMLR, 2020: 10524-10533.
8. Zhang B, Sennrich R. Root mean square layer normalization[J]. Advances in Neural Information Processing Systems, 2019, 32.
9. Wang H, Ma S, Dong L, et al. Deepnet: Scaling transformers to 1,000 layers[J]. arXiv preprint arXiv:2203.00555, 2022.
10. Shazeer N. Glu variants improve transformer[J]. arXiv preprint arXiv:2002.05202, 2020.
11. Su J, Lu Y, Pan S, et al. Roformer: Enhanced transformer with rotary position embedding[J]. arXiv preprint arXiv:2104.09864, 2021.
12. Press O, Smith N A, Lewis M. Train short, test long: Attention with linear biases enables input length extrapolation[J]. arXiv preprint arXiv:2108.12409, 2021.
13. Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[J]. arXiv preprint arXiv:2104.08691, 2021.
14. Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
15. Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International Conference on Machine Learning. PMLR, 2019: 2790-2799.
16. Zhang R, Han J, Zhou A, et al. Llama-adapter: Efficient fine-tuning of language models with zero-init attention[J]. arXiv preprint arXiv:2303.16199, 2023.
17. Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language models[J]. arXiv preprint arXiv:2106.09685, 2021.