在今年的Microsoft
Build 2023大会上,来自OpenAI的研究员Andrej
Karpathy在5月24日的一场汇报中详细讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。本文来自DataLearner官方博客:来自Microsoft
Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State
of GPT详解
| 数据学习者官方网站(Datalearner)
Andrej Karpathy是李飞飞的学生,曾经作为OpenAI的创始成员在OpenAI工作了2年,然后又去特斯拉工作了5年,2022年又回到了OpenAI。可以说是人工智能领域的顶尖人才了!
本场汇报共40多分钟,包含2个方面,一个是如何训练出GPT这样的大语言模型,里面包含了大语言模型的训练过程以及相关的技术,虽然是一种high-level的讲解,但是对于理解ChatGPT的训练十分有用。关于这部分的内容有一些十分有价值的信息:
1. ChatGPT全流程的训练过程涉及的步骤和技术
2. 大模型分为基础模型、SFT模型和RLHF模型,它们是不同阶段的模型,有不同的特点,适合不同的任务
3. 不同阶段产生的模型能力不同,训练的成本也不一样,预训练阶段的基础模型资源消耗最高
4. 文中也给出了一些解释,包括有了基础模型的有监督微调,为什么还需要做RLHF模型
目前,官方网站未注册的用户无法观看视频,只能去YouTube观看。等到Build大会结束之后官方应该会有视频和材料放出。已注册用户可以直接官网观看,并且可以下载字幕哦~
State of GPT概述
预训练阶段文本的tokenzation预训练阶段的输入和目标OpenAI的基础模型GPT-3与LLaMA对比
有监督微调
奖励模型
强化学习
为什么有了SFT模型还要做RLHF?
RLHF模型并不总是比基础模型好
State of GPT概述
这份汇报的主题名称叫做State
of GPT,整场汇报以GPT-3和MetaAI的LLaMA为例,尽管没有涉及到GPT-4相关的内容,但核心思想应该是一样的。全文围绕如下的这个图展开:

这幅图很好地总结了大语言模型的训练全景,主要包括四个阶段:
预训练阶段:基于原始数据训练一个基础模型,得到的是一个base
model,可以部署使用
有监督微调阶段:基于高质量的数据继续训练这个基础模型,得到的是一个sft
model,也可以部署使用
奖励建模阶段:这也是ChatGPT中著名的RLHF的一个阶段,即训练一个奖励函数对齐模型,该阶段训练的结果一般不建议部署使用
强化学习阶段:基于阶段三的奖励模型继续进行强化学习,可以得到一个能支持与用户对话的类似“ChatGPT”的模型
这四个阶段,每个阶段都涉及到一些训练技术和数据集,以及产出和硬件消耗等,十分清晰明了。本文也根据这三个阶段详细介绍里面涉及到的内容。
预训练阶段
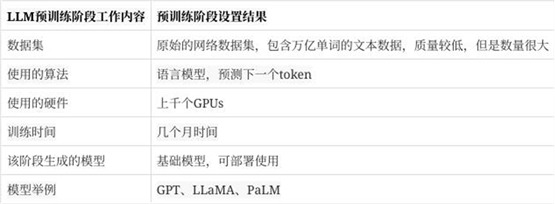
预训练阶段的主要目的是为了训练一个基础的语言模型。核心是基于transformer架构,利用大量的无标注数据来训练模型对下一个token的预测,这也是整个大模型阶段最消耗时间和算力的地方。
根据Andrej
Karpathy的报告,这个阶段消耗了全过程99%的计算时间和FLOPS(每秒浮点操作次数)。这个阶段主要使用的数据集和技术如下:
接下来Andrej
Karpathy详细介绍了预训练阶段里面的几个方面,我们也跟随这个思路做一个简介。
文本的tokenzation
在这个阶段,对数据集的处理一个重要的步骤是做tokenizer。大语言模型原始训练数据都是文本,是不能直接输入的,采用tokenizer将文本变成整数,利于模型学习每个词元的表示和上下文信息,并且可以在不同数据集上迁移。如下图所示,是来自OpenAI做tokenzier的例子:
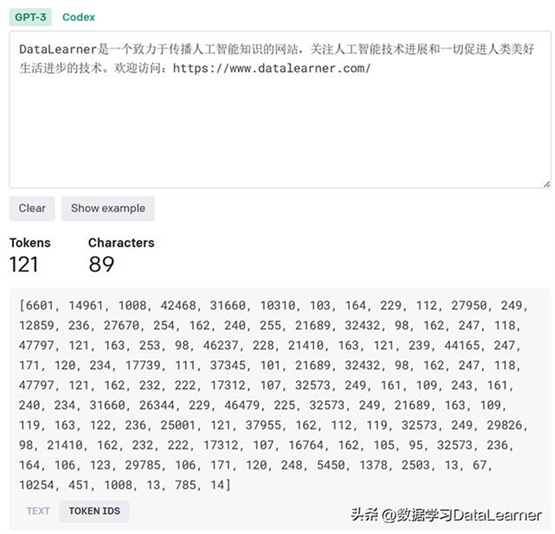
tokenizer是将原始数据转换成整数数值(OpenAI提供了一个开源实现:byte
pair encoding:https://www.datalearner.com/blog/1051671195543180
),这是transformer模型能够接受的输入。一般来说需要将原始的文本变成tokens,再变成每个token对应的整数数值即可。
如下图所示:

预训练阶段的输入和目标
做了tokenzier之后就可以针对数据集利用transformer模型进行训练。一般来说,模型的输入可以总结成(B,T),其中B是batch_size,T是最大的context
length,一般来说context
length的长度在几千,当然现在也有更长的例如几十万个tokens了,不过大多数还是几千个。
在实际代码中,训练的序列是以行的形式输入的,以特殊分隔符(如<|endoftext|>)作为分割,表明这是一个段落的结束。如下图所示:

这里以最大的输入长度10为例,尽管似乎这段视频截断了,但是也可以看到右下角那个表格就是我们数据的输入,大量的文本数据变成整数之后按照行接起来,不同文档之间用<|endoftext|>分割,从图中看就是红色的50256,就是告诉模型这是一个文档的结束。算法会按照数据的输入,每隔T长度当作一个批次的输入。可以看到,这里的一个批次的输入并不是要求完整的文档或者语句!
语言模型的训练就是根据这个数据,来预测。取出里面任意一个位置的整数,然后整数之前的T长度作为输入,来预测这个位置是什么。这里面涉及到一个vocabulary
size的概念,即我们要先知道这个数据集包含的词汇数量,也就是不同token的总数,例如,这里可能是50527个词汇,那么也就是说我们预测的结果就是从50527中找出一个值,代表接下来会出现的单词即可。这个数字在模型中数固定的且明确的。
至此,我们就可以训练一个基础的语言模型。这个模型有很强的表示能力。但是所有的目的都是为了生成下一个单词。尽管如此,这样的模型也展示了在下游任务上强大的能力。
在GPT-1的时代,大家收集下游有监督的数据集做微调,GPT-2的时候OpenAI发现就可以通过简单的prompt来让模型有适应下游任务的能力。
OpenAI的基础模型GPT-3与LLaMA对比
以这个阶段为例,最为代表性的两个模型就是GPT-3与LLaMA(GPT-4不会披露细节)。Andrej
Karpathy对比了GPT-3与LLaMA模型,并且承认了LLaMA-65B的模型尽管参数更小,但是比GPT-3更强大。原因在于LLaMA训练使用的数据集中tokens更多。二者对比如下:

不过需要注意的是,这个阶段生成的基础模型并不是一个assistant模型,尽管对它微调或者做prompt工程可以得到想要的结果,但是并不是那么完美。实际上,基础模型不会回答问题,只是在补全文档而已。
这里Andrej
Karpathy也说明了一个知识,就是OpenAI的GPT-3的基础模型可以通过davinci的API访问,但是GPT-4的基础模型已经不是了,访问的其实是assistant。目前没有任何方法可以访问GPT-4的基础模型。
如果需要基础模型有类似“ChatGPT”那样强大的对话能力,就需要后面的训练。
有监督微调
有监督微调阶段是基于预训练阶段训练的基础模型做有监督的训练。这个阶段需要收集高质量的问答数据,但是不需要阶段一那么多的数量(实际上也做不到)。一般来说,也是雇佣外包人员收集1万到10万个prompt-response对的数据集就好了。
不过,这个阶段算法上没有任何变化,用预训练同样的方法继续在这个高质量的prompt-response数据集上训练即可。这个阶段得到的是一个SFT模型(Supervised
Fine-tuning Model,SFT),依然是可以部署使用的模型。目前业界发布的Vicuna
13B就是这个模型(https://www.datalearner.com/ai-models/pretrained-models/Vicuna-13B
)。
基于基础模型训练的SFT模型通常只需要1-100个GPU训练几天即可。
下图展示了业界开源的OASST1和OpenAI的InstructGPT相关的SFT数据集:

可以看到,OpenAI的数据集应该是包含了回复的评价的,包括真实性、有用性和危害性等,涉及到后续的模型训练。
至此,其实我们已经拥有一个可以得到不错回复的模型了。但是,Andrej
Karpathy还继续说明了接下来两个重要的阶段,即来自RLHF的两个阶段。它们对于模型的提升依然很重要,而且与SFT阶段差别也很大。
奖励模型
RLHF全称Reinforcement Learning from Human Feedback,即基于人类反馈的强化学习,可以分成两个阶段,一个是训练奖励模型,一个是做强化学习。
在奖励模型的训练中,主要的工作是将前面收集到SFT数据集变成可比较的数据集。
以下图为例,用相同的prompt,让模型生成3个不同的回复:

接下来依然交给人类,让人类比较这仨个回复的质量,对齐排序。然后形成如下格式的数据集:

其中蓝色部分是prompt,不同行的prompt结果是一样的。黄色部分是模型针对prompt的回复结果。绿色部分是一个标记,表明奖励结果。接下来继续训练语言模型,但是只让它预测这个绿色部分。让模型学会比较同样的prompt中哪个回复更好。
当然,OpenAI本身也有些确定性的ground
truth,确保最终的排序结果符合实际(因为两两比较的结果可能产生非常奇怪的与事实不同的东西,这一点也要考虑)。
奖励模型阶段的训练使用的数据集一般包含10万到100万的比较结果,来自外包人员标注,数量少,质量高。使用的算法是一种类似二分类的方法,用来预测一致偏好的奖励,最终生成的奖励模型一般不会作为模型部署给大家使用。
奖励模型的训练通常和SFT模型一样,1-100GPUs,几天训练即可。奖励模型训练完成之后就要进入强化学习阶段。
强化学习
接下来的强化学习阶段,我们要使用SFT模型和前面的奖励模型。数据集如下:

可以看到,与奖励模型阶段类似。它先初始化一个SFT模型,然后其中绿色部分由RM模型预测得分。黄色部分是训练的目标。这里想让模型学会识别哪些prompt结果是好的,哪些不好。如果奖励函数结果为正,那么黄色部分生成的结论就要在未来更多偏向生成,如果奖励结果为负值,这意味着模型在未来的生成要尽量少生成黄色部分的回复。
奖励模型在第三阶段搞完就不变了,也就是这里的绿色部分不变化。训练的目标是识别黄色部分的好坏。增强模型生成好的回复就是目标。这样反复训练就可以让模型理解黄色部分怎么样生成才能获得更好的得分了。
这个阶段使用的数据集与前面一样,1万-10万个prompts,高质量,数量少。目的是使用强化学习思想,生成tokens以最大化reward。这样的模型也就是最终的ChatGPT模型。通常需要1-100个GPUs,几天训练即可。
为什么有了SFT模型还要做RLHF?
其实答案很简答,就是效果更好。根据InstrcutGPT的论文,相比较SFT模型,在实际测试中,人类更加喜欢经过RLHF训练之后的模型。
而关于为什么RLHF效果更好的真正原因,目前Andrej
Karpathy认为没有一个大家可以都同意的观点。不过,他自己也给出了一种可能解释。那就是,对于一项任务来说,做判断比做生成更加容易。举个例子,如果让你去收集一些数据,来训练模型写诗的能力,你可能要去找关于诗的描述,然后是这个描述对应的诗词。这项工作可能并不容易。但是如果模型针对一个描述,生成了好几首诗,让大家判断哪首诗更好。那么,这项工作相对而言可能更见简单和明确。
Andrej Karpathy提供的这个描述是从数据集收集和标注的角度来说的。前者就是SFT模型的训练数据收集过程,后者其实就是RLHF的过程。
RLHF模型并不总是比基础模型好
那么,在实际应用中,并不是所有情况下,RLHF模型都比基础模型更好。尽管RLHF模型可以更好地遵从人的意图,但是它丢失了一些entropy。意思是基础模型可以生成更加多样性的结果,而RLHF模型会生成更多peaky的结果(注意,peaky的结果可以理解是分布中的峰值结果,也就是说RLHF模型的分布更加峰值化,有较明显的高频词或序列)。

这意味着,如果你想用模型生成多样性的结果,例如给了n个事物,需要基于此生成更多类似的结果,那么RLHF模型并不合适。他举了一个基于宝可梦精灵的名字来生成更多类似的名字的案例,这种情况显然基础模型更适合。
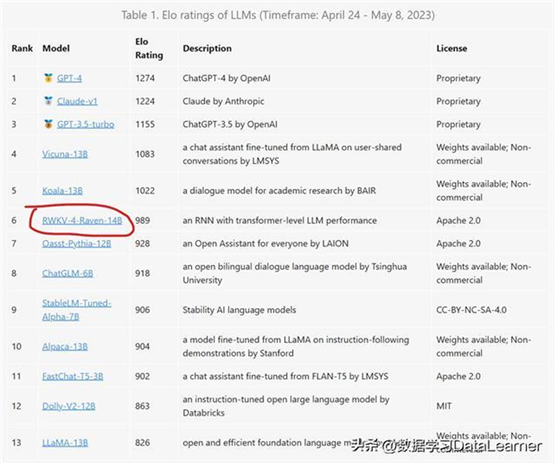
下图是LM-SYS展示的大模型匿名评分结果(就是给定一个问题,随机匿名给出2个模型的答案,让普通用户比较好坏,结果进行排名)。结果显示,排名靠前的3个模型都是RLHF模型。