Midjourney虽然出图精美,使用方便,但是出图的灵活性方面是一大硬伤,Stable Diffusion 作为Midjourney的开源替代品,由于其丰富的插件,灵活可控,受到社区的热捧,一直被寄予厚望,这次Stable Diffusion发布了 XL 1.0版本,让它又大火了一把。下面我们一起来认识下它。
Stable Diffusion XL 简称 SDXL,是 最新的图像生成模型,在它出现之前,Stable Diffusion已经有2个大版本在用了,stable 1.5和 stable 2.1。SDXL 1.0 出现前,同样经历了0.9和beta版本的过渡阶段, SDXL 1.0 在 stable 1.5的基础上做了改进,参数数量从0.98B扩大到6.6B。在AI领域,更大的参数意味着更好的质量。
在介绍SDXL的优秀表现之前,有必要说明下为什么它这么受欢迎?
官方介绍了几点,我在这里再引用一下,并做个详细说明。
更有艺术感的图像。
在SDXL之前,应用Stable Diffusion 生成图像是基于SD的基础模型,比如sd 1.5,sd2.1 那种,但是基础通用的模型不仅缺少风格等特征,而且不够真实。为此,社区在基础模型上做了大量的精调,生成特定领域的风格或场景图,比如训练各种各样的LoRA来改变风格。
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,在微软的论文《LoRA: Low-Rank Adaptation of Large Language Models》提出了一种低秩adapters学习技术LoRA,实现大规模语言模型的跨领域与跨语言迁移。
LoRA不仅可以实现跨领域与跨语言的迁移,当应用于Stable Diffusion模型中,可以实现该模型在不同领域与任务中的迁移。比如Stable Diffusion是一个多模态语言-图像模型,LoRA可以学习将其语言表征迁移到图像modal中,从而获得跨模态语义一致的表示。还可以将Stable Diffusion模型从一个生成样式或风格迁移到其他样式与风格,如从写实主义迁移到动漫风格等。比如我之前的文章曾介绍的示例,它可以将真人模型转为迪士尼风格的图片,常用于个人头像订制等场景。

LoRA仅需要少量的数据就可以进行训练的一种模型。在生成图片时,LoRA模型会与大模型结合使用,从而实现对输出图片结果的调整。
与LoRA相对的是checkpoint模型。checkpoint模型在基础模型之上的再训练,通过追加更多的数据,checkpoint模型包含生成图像所需的一切,可以独立使用,不需要额外的文件。但是它们体积很大,通常为2G-7G。
前比较流行和常见的checkpoint模型有Anything系列、AbyssOrangeMix3、ChilloutMix、Deliberate、国风系列等等。这些checkpoint模型是从Stable Diffusion基本模型训练而来的,相当于基于原生安卓系统进行的二次开发。目前,大多数模型都是从 v1.4 或 v1.5 训练的。它们使用其他数据进行训练,以生成特定风格或对象的图像。
而有了SDXL之后,就可以一步到位生成照片级的图像,SDXL默认生成1025*1024,而stable之前的图片是512*512,像素大小提高4倍,更清晰。

而且还可以在一个模型中生成比如动画风格的人物形象。
anime, photorealistic, 1girl, collarbone, wavy hair, looking at viewer, upper body, necklace, floral print, ponytail, freckles, red hair, sunlight
disfigured, ugly, bad, immature, photo, amateur, overexposed, underexposed

更真实的图像
在SDXL之前,通过Stable Diffusion生成绘画,经常会出现恐怖片场景,SD基础模型特别不擅长进行真人绘制,所绘制的人物要么多头,要么少胳膊,要么多手指,要么少腿,总之人物经常会发生变形。举几个不那么让人不适的图片:



为此,如果要生成一张富有美感的照片,需要输入非常多的描述词,比如为了得到下面这张图片:

需要提供者这么多的正向提示词:

有时候不放心,还要追加一连串重复的形容词:
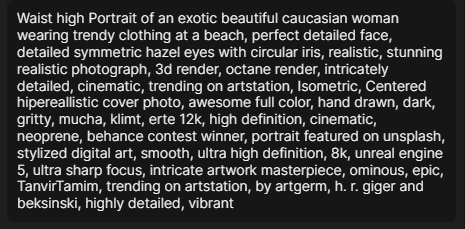
同时再提供一堆的负向描述:
bad anatomy, disfigured, blurry, cloned face, low contrast, over/underexposed,bad hands,cloned face ,disfigured ,extra limbs,extra legs,fused fingers,extra fingers,extra arms,long neck,poorly Rendered face,deformed body features,poorly rendered hands,malformed limbs,
bad anatomy,ugly,missing arms,missing legs,bad proportions,cloned face,cropped, poorly drawn feet,extra limbs ,mutated hands,morbid,dehydrated,cut off,body out of frame,out of frame,malformed limbs
尽管如此,你仍然无法保证能得到一张好的图像,而这些正反提示词本身就足够吓退初学者。
在Midjourney中,这再简单不过了,自动有了SDXL之后,我们生成图像的难度进一步降低,更接近Midjourney了,尽管还有不少的差距。
举一个示例,这里随意生成一张中国女性的图像:


虽然图像很普通,但至少没有出现恐怖场景,提示词只需要简单的 “chinese woman”即可,负向提示词都可以省略,更关键的是,再也不需要使用其他特别训练的大模型或者搭配类似国风LoRA模型了。
提示词只需要简单的 chinese woman即可,负向提示词都可以省略,更关键的是,再也不需要使用其他特别训练的大模型或者搭配类似国风LoRA模型了。
更清晰可读的字体
在之前的stable中图像中添加文字,可是一件非常难以办到的事,比如在之前的模型中在生成的图像中生成下面的文字:
A fast food restaurant on the moon with name “Moon Burger”
它可能是这种效果:

在SDXL中,不出意外可能是这种:

关于图像文字生成,额外介绍一下,尽管SDXL也很优秀,但是可能在这方面不如DeepFloyd/IF.
比如在DeepFloyd/IF中生成下面的图片:
a photo of a violet baseball cap with yellow text: "JZ AIGC". 50mm lens, photo realism, cine lens. violet baseball cap says "JZ AIGC". reflections, render. yellow stitch text "JZ AIGC"


而在SDXL中是这样的:

反正我是尝试了N次,这是最好的结果,要么多字符,要么少字符,还有字符漂移到帽子之外的。当然DeepFloyd/IF 也不是每次都能保证好质量。
讲到zhel,大家应该明白为什么SDXL为什么这么火,这么受欢迎了,确实它在一个模型之中,帮助我们节省了更多的精力,为什么它有这种能耐的,这得从其工作原理说起:
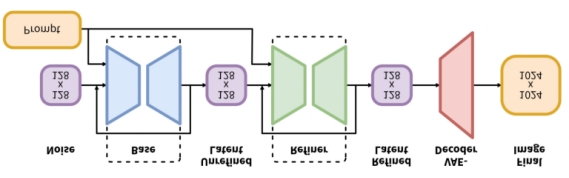
我们简单看一下工作原理,它包括两个模型:base基础模型和一个Refiner精炼模型。基础模型设置全局的构图,精炼模型在其基础上增加更多细节,当然你也可以单独使用基础模型。
语言模型结合了OpenClip (ViT-G/14) 和 OpenAI CLIP ViT-L。而StableDiffusionV2仅仅使用了 OpenClip ,导致很难写prompts。此外,Stable Diffusion中最关键的 U-Net是之前的3倍,加上更大的语言模型,使得SDXL能够用prompts匹配到更高质量的图像。
最后,前面提到SDXL默认生成图像大小为1024×1024,是 之前的4倍。
接下来,我们再一起过一下,怎么来用SDXL?
如果你喜欢使用现成的网页,你可以选择在 Clipdrop 上线的SDXL 1.0 ,地址:
https://clipdrop.co/stable-diffusion
这个免费网站不足之处是需要排队,而且免费生成的图像细节和质量都不如收费的。
下面几个免费网站值得去看看,尤其是playgroundai,它做的类似智能版本的线上PS:
https://playgroundai.com/ 目前是SDXL1.0
https://canvas.krea.ai/files/recent 目前是SDXL1.0
leonardo.ai 目前是SDXL0.9
另外,DreamStudio也具有可用于图像生成的 SDXL 1.0,每个账号试用 25 个credits,大概12张图片的试用额度。
http://dreamstudio.ai/
其他商用版的还有:AWS Sagemaker和AWS Bedrock:
https://aws.amazon.com/bedrock/
Stable Foundation Discord也开放用于 SDXL 模型的实时测试。Discord是SDXL的测试渠道,可以趁着测试期间,薅一波羊毛:
https://discord.com/channels/1002292111942635562/
如果你想接入API,这几个网站可以尝试:
https://platform.stability.ai/
https://clipdrop.co/stable-diffusion
http://dreamstudio.ai/
如果你倾向于写Python代码去调用SDXL模型,可以看这个:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
如果你倾向于源码部署可以看下面的资源链接:SDXL 1.0的权重和相关源代码已在Stability AI GitHub上发布,地址:
https://github.com/Stability-AI/generative-models
相关模型下载地址:
Download SDXL 1.0 base model:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
Download SDXL 1.0 refiner model:
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
Download SDXL VAE file:
https://huggingface.co/stabilityai/sdxl-vae/resolve/main/sdxl_vae.safetensors
下面是一些有用的colab 平台部署代码:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
https://github.com/TheLastBen/fast-stable-diffusion
https://colab.research.google.com/github/R3gm/InsightSolver-Colab/blob/main/SDXL_0_9.ipynb#scrollTo=WC7GtSaEHY9F
https://colab.research.google.com/github/camenduru/sdxl-colab/blob/main/sdxl_v1.0_webui_colab.ipynb
https://colab.research.google.com/github/yilundu/reduce_reuse_recycle/blob/main/notebooks/image_tapestry.ipynb#scrollTo=gMRVuthGU0y2
https://github.com/jduke99/DeepFloyd-Colab/blob/main/Deep_Floyd_from_HF_Spaces.ipynb?short_path=7f7ad36
https://github.com/TonyLianLong/stable-diffusion-xl-demo
出自:https://mp.weixin.qq.com/s/JHptOi3r99eEpdenhgNEeQ