停用词(Stop Words)是自然语言处理领域的一个重要工具,通常被用来提升文本特征的质量,或者降低文本特征的维度。这里简单介绍了停用词的起源和定义,并用信息检索和主题建模的例子展示了停用词的价值,然后介绍了几个用来构造停用词表的简单方法
1. 引言
我刚开始接触自然语言处理时,做的第一个练手任务是文本分类。在构造特征的时候,我选择了词袋模型,并按照教材里提示的方法、将词汇表中一些不重要词语给过滤掉,最后得到了一个维度为数千(远小于中文词汇表的大小)的特征。特征工程的结果,类似表1-1所示内容。讲真,过滤掉低得分词语后,分类器的效果提升很大。
表1-1 词语是否进入特征列表
|
序号
|
词语
|
得分
|
是否采用
|
|
1
|
一定
|
555
|
是
|
|
2
|
给
|
222
|
否
|
|
3
|
县长
|
666
|
是
|
|
4
|
一
|
233
|
否
|
|
5
|
个
|
333
|
否
|
|
6
|
惊喜
|
996
|
是
|
|
…
|
…
|
…
|
…
|
这个练习让我意识到,在特定的NLP任务中,一些词语不能提供有价值的信息作用、可以忽略。这种情况在生活里也非常普遍。当我们的任务是判断图1-1所示信息的友好度时,橙色的“上”字虽然很显眼,但是没有太大的辅助作用——我们只需要分析“我从未见过有如此厚颜无耻……”,就可以知道丞相是在施展嘴遁骂人了。

图1-1 丞相大杀特杀(电视剧《三国演义》)
在信息检索领域,大家称前面所述、可以忽略的词语为停用词(stopword)。
我们和机器在处理文本的时候,忽略停用词的操作,合理吗?这种操作是如何出现的呢?有没有一套方法,可以帮助我们合理确定停用词呢?本文是对这几个问题的简单回答。
2. 停用词表的价值和应用
在计算机科学发展的初期,祖师爷们的一个重要任务,是设计足够优秀的信息检索系统,以支持大家从上千篇文档中找到自己需要的那一篇。H. P. Luhn大爷(1957)发现,在我们的沟通过程中,一些词语相对于其他词语承载了更重要的信息。Luhn(1958)换了一个思维方向,认为我们在表示信息的时候,会使用一些高频出现、但是和“noise”一样不重要的词语。后来的学者们为这种高频、低价值的词语起了个名字,即前面提到的”停用词”。
停用词被提出后,经过从业者们几十年的发展,已经被应用在了几乎每一个信息检索系统中。
2.1停用词与信息检索系统
如表3-1,假设我们的文档库里只有3篇文档。一般来说,我们会用倒排索引来存储文档特征与文档编号的映射关系,以实现一个比较快的信息检索系统。如表2-2,是我为表2-1所示文档库构建的倒排索引。这个倒排索引看起来,不仅不会提升检索速度,反而会增加检索的复杂度——随着文档库的规模增加,倒排的作用会逐渐由负变正的。
表2-1文档库内容
|
文档编号
|
文档内容
|
分词结果
|
|
1
|
神木是个好地方。
|
榆林/的/神木/是/个/好/地方/。
|
|
2
|
神木的卤肉夹干烙好吃。
|
神木/的/卤肉夹干烙/好/香/。
|
|
3
|
神木中学是个好学校。
|
神木中学/是/个/好/学校/。
|
表2-2 一个倒排索引的内容
|
key
|
value
|
|
榆林
|
[1]
|
|
的
|
[1,2]
|
|
神木
|
[1, 2]
|
|
是
|
[1,3]
|
|
个
|
[1,3]
|
|
好
|
[1,2,3]
|
|
地方
|
[1]
|
|
。
|
[1,2,3]
|
|
卤肉夹干烙
|
[2]
|
|
香
|
[2]
|
|
神木中学
|
[3]
|
|
学校
|
[3]
|
仔细分析表2-2,我们会发现“。”这个词语,对检索是没有帮助的。在这个场景里,句号不提供任何语义信息,无助于检索系统判断一个文档和查询语句的匹配程度。比如,“神木是好地方吗。”和“神木是好地方吗”这两个query,检索到的文档是完全相同的,都是[1,2,3]。基于我们自身的文本信息处理经验,就可以做出这样一个决策,即词汇表中像“。”这样“没有帮助”的词语删掉。
为什么“。”的信息量低呢?无处不在。“。”的出场率太高了,以至于倒排索引中key=“。”的value包含几乎所有的文档。即使是一个比较小的信息检索系统,需要处理的数据数量级也是万。一旦查询语句包含了“。”,检索系统将召回几乎所有的文档,并计算这些文档与query的匹配度——这时候,用户不得不长时间等待,直至脑海中出现砸电脑的冲动,如图2-1。用户还可能卸载我们的软件哦。

图2-1 长时间等待后的用户(https://www.17qq.com/biaoqing/2028597.html)
在这个场景中,“。”出现在每一篇文档,是一个人为制造的极端情况。在实际应用中,我们通常遇到的情况是,一些词语出现在大部分或者几乎所有文档中。这信息量不大的词语多多少少对检索效果有一点帮助(短文本例外),有一定价值——然而一般情况下我们需要删掉它们。在我接触过的短文本检索任务中,去除停用词后,召回率可以提升1%以上(应该是若干个百分点,这里保守一下)。
停用词的存在不仅会让搜索的计算复杂度接近穷举搜索,还会让搜索的空间复杂度失控。假设我们有10,000篇文档(目前我了解的,最小的垂直领域所包含的文档数量级),词汇表中包含了700个停用词(哈工大停用词表的容量),那么极端情况(停用词出现在每一个文档里)下,倒排索引里可能会包含700*10000=7000,000个文档id,至少需要消耗7000,000*32*2字节=420,000,000字节=420兆字节。要是文档数量再大一些(一个垂直领域的文档数量一般在百万以上),倒排索引消耗的存储空间还会更大。
表2-2所示倒排索引删掉停用词后,就成了一份更小的数据,如表2-3。
表2-3 去除停用词后的倒排索引
|
key
|
value
|
|
榆林
|
[1]
|
|
神木
|
[1, 2]
|
|
地方
|
[1]
|
|
卤肉夹干烙
|
[2]
|
|
香
|
[2]
|
|
神木中学
|
[3]
|
|
学校
|
[3]
|
2.2停用词与主题模型
在构建主题模型的的过程中,我们会发现“的”“地”“得”这样的词语无助于表达一个主题——由于这样的词语实在是太多了,在主题的词语分布中占有重要位置,导致我们总结一个主题的含义时遇到很大的困难。这个时候,去掉这些价值不大、有负作用的词语成为必需。
如图2-2,是使用LDA从新闻标题数据中学习得到的主题。可以看到,各个主题的词语分布,被“?”、“的”等信息含量很低的标点符号、字、词主导了。这会导致我们无法基于词语分布总结各个主题的含义(换句话说,这些主题没有意义)。

图2-2 未过滤停用词时的主题
为了提升主题的效果,我将语料中的停用词过滤后,再训练LDA,结如图2-3。可以看到,各个主题的高权重词语具有相对比较明确的含义,似乎可以总结出一些话题了。如果要说明停用词过滤对LDA训练效果提升的原因,那就需要使用LDA的基本原理了——我还没有推导明白,暂时无力讲述。

图2-3 过滤停用词后计算得到的主题
3. 如何构建停用词表
前面提到,停用词是在使用词袋模型是必需小心处理的一个现象,而基于停用词表将停用词直接过滤掉就是一个非常有效的处理方式。那么问题来了,如图3-1。

图3-1 哪里可以搞到停用词表呢?(电影《唐伯虎点秋香》截图)
停用词表不需要买。自己制作就可以了。
据我所知,没有一套放之四海而皆准的方法,可以保证我们一定能建设出一个完美的停用词表。我们能做的,是结合自己要解决的问题,选择合适的方法来构建一个“尽可能好的”或者“更好的”停用词表。
3.1统计信息
注意,本小节为了便于本人记忆,选择从信息熵出发理解TF-IDF。这是一种叫做“强行解释”的操作。
我们不能空口白牙说停用词“信息量少”,要有依据。“信息量”的通俗化叫法,就是 “权重”或者“影响力”。注意:“信息量”与“权重”不是完全相同的概念。由于(在不大部分场景里)二者大小成正比,在普通应用中即使混淆了也不会造成重大损失。
最经典的信息量度量指标,那当然是香农(之前写作“香浓“;“香农”是规范的译法。感谢CBG同志的提醒)提出的信息熵了。我们假设说话或写作都是这样一种操作:在按照一定的概率,从词汇表中选择词语,添加到句子或文章中。生成文本的过程中,假设一个词语i出现的概率为
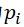
,那么这个词语带来的不确定性的期望值就是

。这个指标的意思是:乘号的左边一项表示一个词语出现的概率;右边一项表示(词汇表中)一个词语的(存在)带来的不确定性。
那么一个词语出现的概率如何获得呢?我们可以基于一份语料数据集来估计。假如我在做马哲相关领域的研究或者应用,那么可以找几本电子版的马哲课本、将其中的文本段落解析出来,然后统计得到这样两个数字:(1)词语“物质”在数据集中出现的次数
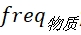
;(2)整个数据集中的词语总数N。那么,词语“物质”出现的概率就是:

,来自“物质”这个词语的熵就是
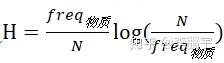
也有人选择用另一种思想来度量词语的信息量。他们认为,如果一个词语i在文档中普遍存在,说明这个词语的存在带来的不确定性较低——这个不确定性可以表示为

。文档频率(Document Frequency)表示包含词语i的文档数量。这样,词语i带来的不确定性的期望值就是
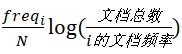
——这个指标非常著名,全称为Term Frequency-Inverse Document Frecuency。
我们可以把TF-IDF值非常低的K个词语找出来,就是一个初步的停用词表了。接下来,我们会请领域专家或工程师,把初版停用词表中有一定价值的剔除掉,这样就得到了一个质量水平比较高(精度高)、可能没有覆盖足够多停用词(召回率较低)的停用词表。在使用停用词表的过程中,我们会发现一些对任务帮助不大的词语,比如3.1节和3.2节中展示的低信息量词语,可以逐步地添加到停用词表中;另外,如果一些停用词的存在导致任务失败,比如某篇文档没有被检索到,那么我们需要将这些停用词重新激活、使之成为普通词语。
3.2使用领域知识
领域知识可以支持我们做一些细致的操作,比如收集停用词。在特定的领域里,有些词语提供的信息较低,不宜用作特征。假设我们在做一个诗歌知识服务工具,那么如图3-2所示的“火星文”字词,是必需被收录到停用词表的——目前为止,我还没听说有用火星文写诗的。
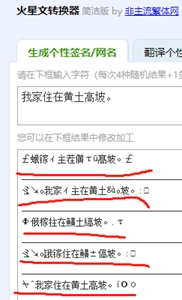
图3-2 “我家住在黄土高坡。”的火星文版本
3.3开源停用词表
一般来说,我们在项目的初期可以考虑使用开源的停用词表,比如funNLP在gitee中开源的4个停用词表(
https://gitee.com/collecthub/funNLP/tree/master/data/%E5%81%9C%E7%94%A8%E8%AF%8Dgitee.com/collecthub/funNLP/tree/master/data/%E5%81%9C%E7%94%A8%E8%AF%8D
)。这4个停用词表分别是:(1)中文停用词库;(2)哈工大停用词表;(3)四川大学停用词表;(4)百度停用词表。
4.停用词表的使用
4.1信息检索系统的query也需要去除停用词吗
在信息检索任务中,我们对倒排索引的key,或者说document特征进行了去除停用词的操作。那么,我们是不是也需要对用户的query进行相同的操作,保持query与document的同分布关系呢?倒排里已经没有停用词了,即使query特征里有停用词,系统也不会召回无用document。看起来没必要多此一举、为query去除停用词了。
事实上,没这么简单。一般的信息检索系统,会考虑未登录词的存在,在计算query与候选文档的关联度时,给词汇表没有收录的词语分配一个默认权重(比如对TF-IDF的各种平滑操作)——如果query的特征包含了停用词,那么系统会把这些停用词看做未登录词,并分配以(不为0哦)的权重。这样一来,停用词就影响到了检索结果,与我们的计划冲突。因此,query特征也需要去除停用词。
4.2什么时候需要去除停用词
任何使用词袋模型表示文本数据的场景,都必需考虑是否需要去除停用词。这几年,我们经常使用字粒度的语言模型,比如BERT、GPT来做NLP任务。这类模型需要把句子中所有的成分都考虑进来,从而更加精准地刻画语言规律。是不是深度学习时代不需要停用词了呢?需要。深度学习模型无法胜任所有的任务,词袋模型仍然会存在,我们还会继续使用停用词。
5. 结语
停用词表是一个非常有价值的工具。它的价值需要通过采用停用词表的系统来体现。我们在构建停用词表的时候,一定要紧紧围绕任务目标来定义评价指标和规则。
最近在参与一个信息检索模块的建设时,发现停用词、同义词、关联词等等数据,都可以帮助我们构造良好的文本表示,从而提升系统的召回率。当然了,用来提升信息检索系统召回率的数据和方法还有很多。至此,我终于理解了大厂土豪行为,即动不动派几百甚至上千人做搜索或推荐——要想建设高水平的系统,就必须把每一个环节的活做细、做扎实,这需要庞大的脑力资源做支撑。
注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即当前页面地址。如有疑问,可发邮件至我的邮箱:lipengyuer@126.com。
参考文献
[1] Rani R , Lobiyal D K . Performance Evaluation of Text-Mining Models with Hindi Stopwords Lists[J]. 2020.
[2] Luhn H P . A Statistical Approach to Mechanized Encoding and Searching of Literary Information[J]. Ibm Journal of Research and Development, 1957, 1(4):309-317.
[3] Luhn, H. P . The Automatic Creation of Literature Abstracts[J]. IBM Journal of Research and Development, 1958, 2(2):P.159-165.
出自:https://zhuanlan.zhihu.com/p/335347401?utm_id=0