0 前言
本次分享是大规模训练技术系列的第一篇,主要包括两个部分:
· 大规模训练技术的意义
· 大规模训练的技术挑战
1 大规模训练技术的意义
1.1 训练的精度极限
深度学习发展历程中,模型精度提升主要依赖神经网络在结构上的变革。 例如,从 AlexNet 到 ResNet50,再到 NAS 搜索出来的 EfficientNet,ImageNet Top-1 精度从 58 提升到了 84。 但是,随着神经网络结构设计技术逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。
1.2 数据与模型规模对精度的影响
近年来,随着数据规模和模型规模的不断增大,模型精度也得到了进一步提升,一些列研究实验表明,从大模型与大数据入手提高模型精度是可行的。
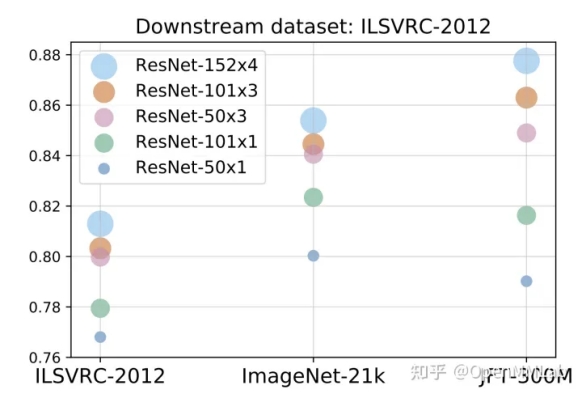
一般的,构造大模型可以通过在现有的模型结构上进行加宽、加深、拼接得到。 更多的 featuremap 意味着更强的学习能力,因此对比相同结构的小模型,大模型有着更好的精度。 以 Google的Big Transfer (BiT): General Visual Representation Learning 中的实验为例。 图中在 ILSVRC-2012 数据集上训练不同规模的模型,精度能从 ResNet50 (2600 万参数)的 77%,提升到 ResNet152x4 (2.4 亿参数)的 81.3%,精度提升 4.3%。 类似的,扩大数据规模也能带来精度提升,如使用 ILSVRC-2012 (128 万张图片,1000 个类别)和 JFT-300M(3 亿张图片,18291 个类别)两个数据集来训练 ResNet50,精度分别为 77% 和 79%。 可以发现,单独使用大数据集或者是大模型,均能带来一定的精度提升。 这些精度提升看起来比较有限,甚至在一些 case 下几乎没有提升,但是当我们同时使用大模型和大数据集时,则会有明显的突破。 还是在图 2 中,使用 JFT-300M 训练 ResNet152x4,精度可以上升到 87.5%,相比 ILSVRC-2012+ResNet50 提升了 10.5%。
NLP 领域的大规模训练发展快速,从 BERT 到 GPT-3,再到 Switch Transformer,无论是模型大小还是计算资源占用都在疾速增长。 规模大到什么程度呢?GPT-3 的参数量达到了 1750 亿,训练数据超过了 45TB,需要的算力(flops)是 BERT 的 1900 多倍,3.14E23 FLOPS。 换句话说,即使是在理论情况下(算力利用率 100%),使用单卡完整训练 GPT-3 也需要 V100 训练 355 年[4]。
目前 CNN 领域的模型参数规模普遍还在 1 亿以内。 例如 EfficientNet-B7 也不过 6000 万参数。但最新研究中,CNN 大模型也开始不断涌现。 如 ResNeXt WSL (8 亿参数)、GPipe (6 亿参数),Google 也通过 EfficientNet-L2 (4.8 亿参数)与未公开的 JFT-300M 数据集刷新了 ImageNet 的榜单,Top-1 Acc 首次突破 90。
可以看出,模型和数据规模的增大确实能突破现有的精度局限
1.3 从分布式训练到大规模训练
模型和数据规模的增大意味着训练时间的增长。 为了提升模型训练的速度,可以增加计算资源来缩短训练时间,于是出现了分布式训练。
简单来说,分布式训练实质就是将单卡的负载拆到了多卡上。
数据并行通过修改 Sampler 切分输入,每张卡只需要处理一部分数据;
模型并行通过修改层内的计算方式,将单层的计算负载和显存负载切分到多张卡上;
流水并行则是将不同的层放到不同的卡上,进而将计算负载和显存负载切分至多张卡上。
通过对负载进行切分,分布式训练减少了单卡的负载,一方面大大提升了训练任务的吞吐量(切分计算负载),另一方面使得原本单卡无法训练的任务变得可能(切分显存负载)。
这里基于一个数据并行的例子进行更细致的分析。 假设深度学习模型,参数足够量小,能够放到单张 GPU 上。 但是由于训练数据集相当大,所以整体任务的计算量非常大。 此时,数据并行的作用就可以体现了:对于这些深度学习训练来说,直接增大数据并行的计算资源是比较有效的,投入数倍的计算资源基本上能获取到相应的加速倍数。 但是随着训练数据集进一步增大,数据并行就会出现一些局限性: 当训练资源扩大到一定规模时(比如说上百卡),由于通信瓶颈的存在,添加资源的边际效应就会越来越明显,甚至增加再多资源都无法再加速。
更系统来说,随着数据和模型的不断增大,会触碰到两方面的问题,大数据和大模型所产生的显存墙问题(模型是否能跑起来)以及计算墙(能否在合理时间内完成训练)问题,使得普通的分布式训练不再适用于此类任务。
00001. 显存墙:单卡无法直接装下模型,模型无法直接训起来。为了能够将模型运行起来,需要使用模型并行、流水并行等技术,但是这些技术会降低 GPU 的运算强度。
00002. 计算墙:大数据+大模型意味着巨大的计算量,而由于显存墙的缘故,这时不仅单卡的运算强度低,多卡的加速比 (scale factor) 也非常差,事实就是,就算花钱加再多资源也可能训不完。
此时,需要引入大规模训练技术。 大规模训练技术在解决显存墙的同时,也不会被计算墙给拦住,以实现高效训练。
2 大规模训练的技术挑战
相比普通的分布式训练,大规模训练技术考虑的问题更加复杂。 首先,面对单卡无法装载的大模型,如何利用多卡来突破显存瓶颈是个问题; 其次,大规模训练会用到大量的计算资源,大量计算资源间如何通信、协作是另一个难题; 最后,如何 balance 各类层出不穷的大规模训练技术,使得众多技术形成一个完整高效的训练方案,更是一大学问。
本系列中,将大规模训练技术面临的挑战分为三部分:显存、通信和计算,每部分都会有对应文章进行详细介绍。 其中,显存部分主要阐述大规模训练中如何解决显存墙问题,其它两部分则是为了解决计算墙问题。
2.1 大规模训练之显存挑战
大模型训练最先遇到的问题就是显存墙。事实上,在进行 ResNeSt269 (1 亿参数)的 ImageNet 训练时,显存就已经逼近了 V100 32GB 的上限,训练占用达到了 28GB (注:Batch size 为 16,Input size 为 416×416)。当模型进一步加大,或者加大 Batch size 后,模型训练的显存占用也会随之增长,最后高于显卡的显存容量,触碰到了显存墙,模型无法训练。
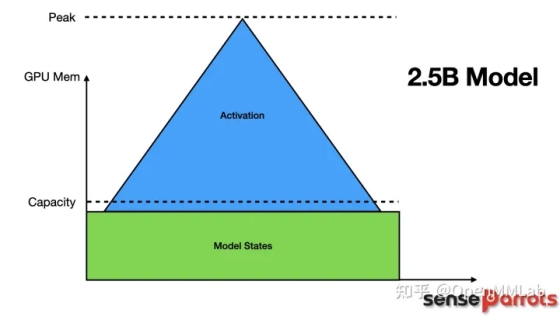
要理解显存墙问题的本质,就需要了解显存增长的本质。下图是 ResNeSt269 在 1 轮迭代间的显存占用变化:

00001. Forward 开始后,显存占用不断飙升,在 Forward 结束后达到峰值 28GB。
00002. Forward 结束,Backward 开始后,显存占用不断下降,在 Backward 结束后为 1.2GB。
00003. Backward 结束后,仍有一部分显存驻留在显卡中,大小保持在 1.2GB。
从图中可以分析出一些有趣的信息:
第一,可以发现,模型训练对显存的占用可以分为两部分:一部分是模型 forward 时保存下来的临时变量,这部分显存会在反向传播时会逐渐释放掉,这部分一般被称为 Activations。另一部分则是参数、梯度等状态信息占用的显存,这部分一般被称为 Model States。
第二,Forward 结束后的显存占用峰值时刻决定了是否会碰到显存墙。降低其余部分的显存占用没有意义,关键在于削低峰值。
接下来具体介绍一下峰值时的 Model states 和 Activations。
2.1.1 Model states
虽然在 ResNeSt269 的 case 里 Model states 仅占用了 1.2GB。但也要考虑到 ResNeSt269 仅 1 亿参数,和当前存在的大模型相比还相差甚远。
但实际上大模型 Model states 的占用非常恐怖,通过以下公式就能够感受到这一点。
P:模型参数量,单位为Billion
当优化器是SGD时,占用大小为:
MS_FP16 = 2P(FP16参数)+2P(FP16梯度)+8P(FP32的参数、动量) = **12P**
MS_FP32 = 12P(FP32的参数、动量、梯度) = **12P**
当优化器是ADAM时,占用大小为:
MS_FP16 = 2P(FP16参数)+2P(FP16梯度)+12P(FP32的参数、动量、variances) = **16P**
MS_FP32 = 16P(FP32的参数、动量、梯度、variances) = **16P**
# SGD下,MS_FP32_ResNeSt269 = 0.1 * 12 = 1.2 GB
# ADAM下,MS_FP16_GPT-3 = 170 * 16 = 2720 GB
因此,一张 V100 32GB 最多能放下参数量为 20+ 亿的模型。不过就算能放下模型,也没有意义,因为已经没有剩余显存留给 Activations 了。
2.1.2 Activations
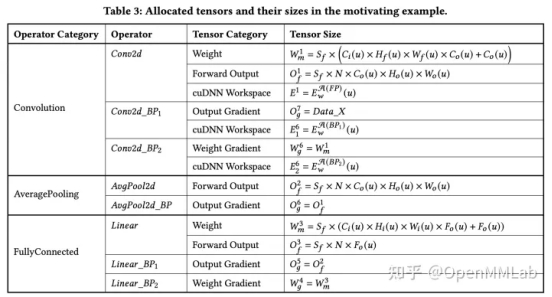
Activations 一般指的是用于 autograd 的中间变量。如上表3中的 Forward Output、Output Gradient 以及 cuDNN Workspace。
因为深度神经网络层数非常多,而每一层的 Forward Output 都需要保存下来给 Backward 用,由此累积下来会造成巨大的内存开销。从 ResNeSt269 中的 case 我们也可以大致看出,Activations 的占用要远远大于 Model States(1.2GB vs 26.8GB)。
事实正是如此,CNN 模型中的 Activations 占了显存的大头, Activations 对 CNN 模型来说是一个非常棘手的问题。
而另一类模型:Transformer 模型的情况则相对更好。原因主要在于 Transformer 中的内部运算以大矩阵乘居多,而大矩阵乘可以拆分做模型并行(CNN 的模型并行非常难),大大减少了 Activations 的占用。
这也是为什么近年来基于 Transformer 的大模型层出不穷,很快模型规模就到了千亿级别,而基于 CNN 的大模型还在亿级。
Model states 和 Activations 都有可能造成显存墙问题。它们相互独立但又相互制约。任意一侧的增大都会导致留给另一侧的显存空间变小,所以单单对一侧做优化是不够的,必须同时优化 Model states 和 Activations。
2.2 大规模训练之通信挑战
在进行分布式训练时对神经网络进行了各种各样的切分,但是神经网络的训练任务仍是一个整体,因而,切分需要通信来进行聚合。
聚合所产生的通信需求隐含了不少问题,首先,深度学习迭代式训练的特性导致更新频繁,需要大量的交换局部更新。但是目前网络的传输速率远远不能匹配 GPU 或 TPU 这种专用加速芯片的运算速率。
有的朋友可能会问,直接用更大的带宽不能解决这些问题吗?
答案是 NO!。直接增加通信带宽并不是一个有效的解决方案2:
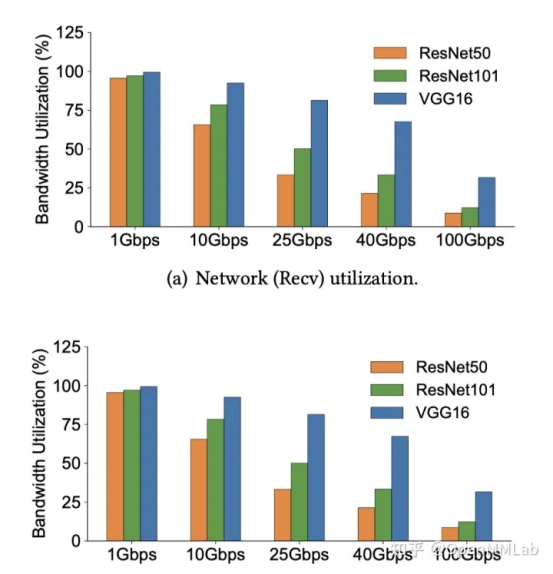
从图中可以看出,随着带宽增大,带宽利用率将越来越低,高带宽的增益非常有限。实际上,其根本原因在于网络协议栈,网络协议栈的开销的导致了训练无法有效利用带宽。幸好,我们能够通过一些方法(会在对应文章中详细阐述)解决掉这部分开销。
但是,即使解决了协议栈的开销,面对大规模的训练任务时,仍然会出现一些新的问题:
00001. 随着机器规模的扩大,基于 Ring-AllReduce 的通信聚合方式所构造的 Ring 将越来越大,延迟将不可接受。
00002. 模型规模的扩大也造成了通信量的剧烈增长:a. 模型变大导致所需通信的梯度变多,带宽还是扛不住;b. 为了训练大模型而引入的模型并行、流水并行等大大增加了通信压力。
00003. 目前普遍采用了同步的通信步调,成百上千卡频繁的进行同步非常容易出现水桶效应,导致单卡上的波动以及单次通信的延迟被疯狂放大。
总的来说,大规模深度学习中的通信瓶颈不单单是通信量大造成的,更多的是复杂的系统问题,还需要从分布式训练架构、通信策略等多方面来考虑解决。
2.3 大规模训练之计算挑战
在一项内部实验中,优化前使用 128 卡进行 25 亿参数量 CNN 模型训练的耗时预估达到了 473.8 天。
大模型+大数据不仅带来了极高的算力需求,同时也在引入各项技术的同时降低了计算资源的利用率。
虽然算力挑战本质来源于大规模训练任务庞大的算力需求,但是一般来说,我们无法直接减少任务的算力需求,因此只能从提高计算效率来考虑。
计算效率问题自底向上可以分为 Operator-level、Graph-level 以及 Task-level 三个层面。
2.3.1 Operator-level
Operator-level 可以理解为算子级别的优化。
大规模训练中的 Operator-level 问题与单卡训练类似。 如:
· 小算子过多
· Kernel实现不够高效
· 内存局部性差
2.3.2 Graph-level
Graph-level 指的是如何对计算图进行优化,进而加速大规模训练。 如:
· 如何搜索出计算效率更高的计算图
· 如何用计算编译技术解决小算子问题
· 如何进行通信和计算的 overlap 等
2.3.3 Task-level
可以理解为训练阶段的系统设计。与传统训练不同,在包含大规模训练技术的训练系统设计时,不仅要考虑到庞大的节点数,也要考虑到在解决显存、通信问题时带来的系统层面的变化。因此,Task-level 的关键挑战在于,如何给出一个最终计算效率最高的系统设计。 如:
· 采用何种分布式训练架构,才能使得大规模训练具备良好的拓展性。在节点数很多时仍能保持较好的加速比(scale factor)
· 如何 balance 显存优化与速度优化
所以,大规模训练中的算力问题是一个综合问题,无法用单一的技术进行解决,而是需要一个整体的解决方案。这个解决方案不仅需要拥有足够的计算资源,也依赖于深度学习框架的运行效率,以及对各项大规模训练优化的 trade off。
引用
· [1] Kolesnikov A, Beyer L, Zhai X, et al. Big transfer (bit): General visual representation learning[J]. arXiv preprint arXiv:1912.11370, 2019, 6(2): 8.
· [2] Zhang, Zhen, et al. "Is network the bottleneck of distributed training?." Proceedings of the Workshop on Network Meets AI & ML. 2020.
· [3] Gao Y, Liu Y, Zhang H, et al. Estimating gpu memory consumption of deep learning models[C]//Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2020: 1342-1352.
· [4] OpenAI's GPT-3 Language Model: A Technical Overview
出自:https://zhuanlan.zhihu.com/p/350707888