一、引言与摘要
Q:这些年,我们在做什么?
A:自从图灵测试在1950年代提出以来,人类一直在探索如何让机器掌握语言智能。为了理解和掌握语言,开发能力强的人工智能算法面临着重大挑战。语言模型LM在过去的二十年中被广泛研究,用于语言理解和生成,从统计语言模型发展到神经语言模型。
Q:你说的这些都是比较老的事情了,现在在做什么?
A:确实,那近几年的话,研究人员提出了预训练语言模型PLM,通过对大规模语料库进行Transformer模型的预训练,展现了解决各种NLP任务的强大能力。并且,由于研究人员发现模型缩放可以导致模型容量的提高,他们进一步通过增加参数规模来探究缩放效应。
Q:等会儿等会儿,听不懂了,解释解释什么叫模型缩放,模型容量?
A:
·
模型缩放:增加模型的参数规模以提高其表现的过程。
·
模型容量:模型能够学习的函数族的大小,该函数族由模型的参数空间定义。增加模型的参数规模可以增加模型的容量,从而使其能够学习更复杂的函数。
补充一点有趣的,当参数规模超过一定水平时,这些扩大的语言模型不仅可以实现显著的性能提升,还表现出一些特殊的能力,比如上下文学习能力等等,这是小规模语言模型(例如BERT)所没有的,这种现象被称为涌现Emergence。
Q:这么厉害?那是不是越涌现就越好?
A:你都这么问了,显然心存疑虑,实际上,涌现现象也可能导致模型出现一些意外的错误或偏见,因此需要在模型设计和训练中加以注意和控制。
Q:那这么多参数的模型是不是应该给赋予一个新的名字?
A:没错,为了区分不同参数规模的语言模型,研究界为具有包含数十亿或数百亿参数的PLM创造了LLM这一术语,也就是大语言模型Large Language Model。
Q:那就是所谓的ChatGPT了!
A:是的,但LLM不只有ChatGPT,还有很多很多...
下图是近年来现有LLM时间轴,另外,如果没有相应的论文,我们将模型的发布日期设定为其公开发布或公告的最早时间。由于篇幅限制,我们只包括公开报告评估结果的LLM。
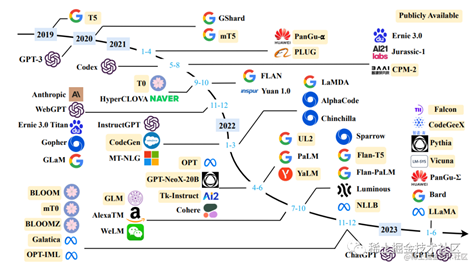 image.png
image.png
Q:这么多?我想更多的了解LLM,你能介绍一下吗?
A:当然可以,我们今天读的这篇综述就是在介绍LLM的背景、关键发现和主流技术。
这篇综述从预训练、适应调整、利用和能力评估四个方面对LLM的最新进展进行了文献综述,并总结了LLM的关键发现、技术和方法。我们主要关注的就是LLM的这四个方面:
·
预训练Pre-training
·
适应调整Adaptation
·
利用Utilization
·
能力评估Capacity Evaluation
二、LM的四个发展阶段
一般而言,LM的目标是建模单词序列的生成概率,以预测未来的或缺失的token的概率。
LM的研究在文献中受到广泛关注,可以分为四个主要发展阶段:
1 统计语言模型SLM:
Statistical Language Model是一种基于统计方法的语言模型,它通过计算给定上下文条件下各个可能的下一个词出现的概率,来对自然语言进行建模。
SLM通常使用N-gram模型来表示上下文,即假设下一个词的出现只与前面N个词有关。
SLM在NLP和信息检索等领域有着广泛的应用,但是其表现受限于数据量和特征选择,主要的应用如统计机器翻译SMT和GMM+HMM模型。
2 神经网络语言模型NLM:
Neural Network Language Model是一种基于神经网络的语言模型,它通过将自然语言转化为向量表示,利用神经网络建模词汇之间的关系来预测下一个词。
NLM通常使用RNN或者变种(如LSTM、GRU)来处理序列数据,并将上下文表示为隐藏状态。
NLM在NLP中表现较好,但是其训练时间较长,且需要较大的数据集和计算资源。
3 预训练语言模型PLM:
Pre-trained Language Model是一种在大规模数据上进行预训练的语言模型,它通过无监督的方式学习自然语言的特征表示,从而为不同的任务提供通用的特征提取器。
PLM通常使用自编码器、Transformer等模型结构,在大规模数据上进行预训练,并通过微调FT等方式适应不同的下游任务。
PLM的出现极大地促进了NLP的发展,如BERT、GPT等模型就是PLM的代表。
4 大型语言模型LLM:
Large Language Model是一种具有大量参数的语言模型,它通过增加模型的容量和训练数据量来提高模型的表现。
LLM通常基于PLM进行设计,通过增加模型规模、调整模型结构、加入更多的任务等方式来增加模型的复杂度和泛化能力。
LLM在NLP领域表现出了惊人的性能,在PLM的基础上,增大模型参数,使得LLM出现PLM不具有的涌现能力,同样采用预训练+微调的形式。
趋势与问题:
LM与LLM已经逐渐成为热点话题,事实上,我们通过近年来包含这两个关键词的Arxiv论文数量的变化趋势便可窥见一斑:
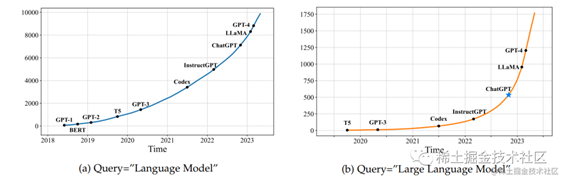 image.png
image.png
LLM的研发需要大量的数据处理和分布式训练经验,这与传统的研究和工程界限已经模糊。
目前,LLM对于人工智能领域产生了巨大的影响,ChatGPT和GPT-4已经引发了对于AGI的重新思考。
不过,虽然LLM已经取得了很大的进展和影响,但其底层原理仍然没有得到很好的探索。其中一个很浅显而又重要的问题是,为什么LLM会出现新的能力,而较小的PLM不会?
其次,研究人员很难训练出有能力的LLM,因为需要大量的计算资源,而训练LLM的许多重要细节(如数据收集和清洗)也没有被公开。
再者,如何使LLM符合人类价值观和偏好也是一个挑战,因为它们可能会产生有害的内容。
三、LLM的关键技术
1 五项关键技术
LLM已经演变成目前的状态,成为通用和有能力的学习器,这得益于多项重要技术。
其中,缩放、训练、能力激发、对齐调整和工具操作是导致LLM成功的关键技术。
简要解释一下:
·
缩放:是指通过增加模型的规模和数据量来提高模型的容量。 这可以通过增加模型的层数、参数数目、模型结构的复杂度等方式来实现。同时,为了支持更大的数据量,需要使用高效的分布式训练算法来训练模型。缩放技术的优点是可以提高模型的表现和泛化能力,但也面临着训练时间长、计算资源消耗大等问题。
·
训练:由于LLM模型庞大,训练具有挑战性。因此,需要使用高效的分布式训练算法来学习LLM的网络参数。 这些算法可以将训练任务分配给多个计算节点,并使用异步更新和梯度累积等技术来加速训练过程。此外,还需要考虑如何处理模型的权重衰减、学习率调整等问题,以提高训练的效率和稳定性。
·
能力激发:能力激发是指通过设计适当的任务说明或特定的上下文学习策略,以激发LLM的潜在能力。 例如,可以设计模型在文本生成、问答、机器翻译等多个任务上进行训练,从而提高模型的泛化能力。同时,还可以通过设计更加复杂的任务和目标,来促进模型的进一步发展和学习。
·
对齐调整:对齐调整是指将LLM与人类价值观保持一致的必要条件。在LLM中,需要考虑到模型的公平性、透明度、隐私保护等因素。对齐调整的过程中,需要进行模型的监督和审查,以确保模型的行为符合人类价值观。
·
工具操作:涉及使用外部工具来弥补LLM的缺陷。例如,可以使用注释、可视化工具等来帮助分析LLM的输出,发现问题并进行调整。同时,还需要开发更加智能的自动化工具,以帮助开发人员更加高效地构建、部署和管理LLM模型。
2 GPT系列LLM技术演进
下图是GPT系列LLM技术演进简图。主要根据OpenAI的论文、博客文章和官方API绘制了这个图。
需要指出的是,实线表示两个模型之间的演化路径存在明确的证据,虚线表示演化关系相对较弱。
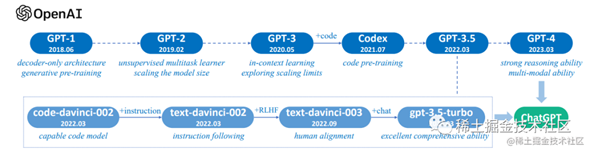 image.png
image.png
四、LLM所需的资源
1 公开可用的模型检查点或API
训练大型语言模型需要大量的计算资源和时间,因此,很多研究人员和公司会公开发布他们训练好的模型检查点或API,以供其他人使用。
这些模型通常采用预训练的方式进行训练,并具有较高的性能和泛化能力。OpenAI的GPT系列模型和Google的BERT模型等都是公开可用的模型检查点。
2. 常用语料库
训练大型语言模型需要大量的文本数据,因此,常用语料库是训练大型语言模型所需的重要资源之一。
常用语料库包括Common Crawl、维基百科、新闻数据、网络文本等。这些语料库通常可以通过互联网公开获取,并且已经被清洗和标记。
3. 深度学习框架和相关工具
训练大型语言模型需要使用一些常用的深度学习框架和相关工具,例如PyTorch、TensorFlow等。
这些框架和工具提供了丰富的API和函数库,可以帮助研究人员和开发人员更加高效地构建、训练和评估大型语言模型,比如:
·
TensorFlow:Google开发的深度学习框架,支持分布式训练和推理。它具有广泛的API和函数库,可以帮助研究人员和开发人员轻松构建、训练和部署大型语言模型。
·
MXNet:Amazon开发的深度学习框架,支持分布式训练和推理,具有高效的计算性能和易于使用的API。
·
Horovod:Uber开发的分布式深度学习框架,支持TensorFlow、PyTorch和MXNet等多种深度学习框架,提供高效的分布式训练和通信。
·
etc.
此外,还需要一些数据处理、可视化和模型调试等工具来辅助训练和分析。这些工具和资源通常可以通过互联网免费获取。
五、LLM的Pre-training
LLM的预训练是指在大规模语料库上进行的无监督学习过程,通过学习语料库的统计规律和语言结构,让模型获得基础的语言理解和生成技能。
预训练为LLM的能力奠定了基础,使得LLM在进行特定任务的微调时能够更快、更准确地收敛,并且可以具备更好的泛化能力。
但我们需要注意的是,在预训练过程中,语料库的规模和质量对于LLM获得强大的能力至关重要。一般来说,有如下规律:
·
大语料库可以提供更加丰富、多样化的语言信息,帮助LLM更好地理解语言的复杂性和多样性。
·
高质量的语料库也很重要,低质量的语料库可能会引入噪声和错误,对LLM的性能产生负面影响。
1 数据收集
1.1 数据来源
为了开发具有强大能力的LLM,需要收集大量自然语言的语料库。
LLM的预训练语料库的数据来源可以分为通用数据和专业数据两种类型。
·
通用数据:包括网页、书籍和对话文本等大规模、多样化、易于获取的数据集,这些数据可以增强LLM的语言建模和泛化能力。通用数据集被广泛应用于LLM的预训练中,可以提升LLM在大多数自然语言处理任务中的性能。
·
专业数据:包括多语言数据、科学数据和代码等针对特定领域的数据集,可以赋予LLM特定任务解决能力。
此外,收集数据集的多样性也很重要,因为不同类型、来源和领域的数据集可以为LLM提供更加丰富和全面的语言信息和知识。
下图是各种数据源在现有LLM预训练数据中的比例:
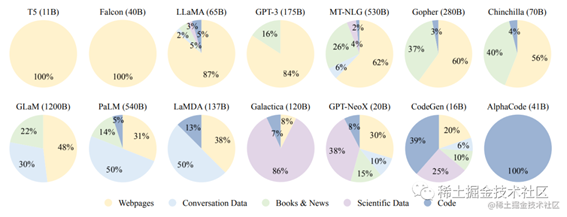 image.png
image.png
1.2 数据清洗
在收集大量文本数据之后,对数据进行预处理以构建预训练语料库非常重要,尤其是需要去除噪声、冗余、无关和可能有害的数据,这些因素可能会严重影响LLM的容量和性能。
典型的数据清洗流程如下:
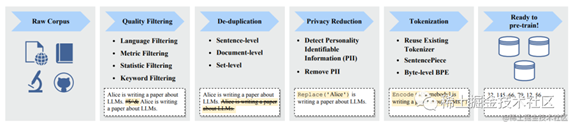 image.png
image.png
2 模型架构
下图是三种主流架构中注意力模式的比较。
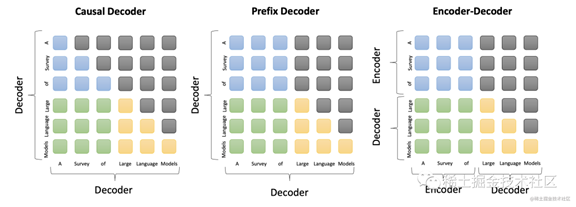 image.png
image.png
其中,蓝色、绿色、黄色和灰色的圆角矩形分别表示前缀符号之间的注意力、前缀与目标符号之间的注意力、目标符号之间的注意力和被掩盖的注意力。
我们来解释一下这几个注意力有什么区别:
1.
前缀符号之间的注意力:这种注意力机制用于编码器中,用于对输入序列中的前缀符号,例如[CLS]符号进行建模,以提供序列级别的表示。这种注意力机制的目的是捕捉输入序列的整体信息,以便更好地进行下游任务的预测。
2.
前缀与目标符号之间的注意力:这种注意力机制用于解码器中,用于将前缀符号与目标符号之间的信息进行交互,以便更好地对目标序列进行建模。这种注意力机制的目的是在解码器中引入输入序列的信息,帮助解码器更好地生成目标序列。
3.
目标符号之间的注意力:这种注意力机制用于解码器中,用于对目标序列中的符号进行建模,以便更好地进行下游任务的预测。这种注意力机制的目的是捕捉目标序列中的局部信息,以便更好地生成下一个符号。
4.
被掩盖的注意力:这种注意力机制用于在解码器中处理掩码符号,例如[PAD]符号,以便更好地对生成目标序列的过程进行控制。这种注意力机制的目的是避免模型在生成目标序列时过于依赖掩码符号。
3 模型训练
3.1 优化设置
·
Batch Training:指在训练神经网络时,将数据分成小批次(batch),每次只用一个小批次的数据进行模型参数的更新操作,而不是对整个数据集进行一次性的训练。这可以使训练过程更加高效,减少内存占用,同时也可以防止过拟合。
·
Learning Rate:是神经网络优化算法中的一个重要超参数,它控制着每次模型参数更新的步长大小。较小的学习率可以使模型学习更加稳定,但可能会导致训练过程过慢;而较大的学习率可以加速训练过程,但可能会导致模型不稳定,甚至无法收敛。
·
Optimizer:是神经网络优化算法中的一种,它的作用是根据损失函数对模型的参数进行更新,以使损失函数最小化。常见的优化算法包括梯度下降、Adam、RMSprop等。
·
Stabilizing the Training:指通过一些技巧,使得神经网络训练过程更加稳定,能够更快地收敛到最优解。常见的技巧包括添加正则化项、使用批归一化、使用残差连接等。
3.2 可扩展的训练技术
·
3D Parallelism:是一种并行计算技术,它能够将神经网络模型的计算分配到多个GPU或多台机器上,以加速模型的训练。与传统的数据并行技术不同,3D Parallelism可以同时利用数据并行和模型并行的优势。
·
ZeRO:一种优化技术,它可以将神经网络模型的参数分成多个分组,并分配到不同的GPU上进行计算,以减少GPU之间的通信量,从而加速模型的训练。
·
Mixed Precision Training:它可以将模型参数的存储精度降低到半精度或混合精度,以减少内存占用和计算量,同时加速训练过程。在模型训练过程中,同时使用高精度和低精度的参数进行计算。
·
Overall Training Suggestion:指一些通用的训练技巧,可以帮助提高神经网络模型的训练效果。比如可以使用数据增强来扩充数据集,使用早停法来防止过拟合,使用交叉验证来评估模型性能等。
六、LLM的Adaptation
1 实例格式化:
首先我们要知道,实例格式化是什么?
实例格式化是指将数据实例(如文本、图像、音频等)处理成一种特定的格式,以便它们可以被用于机器学习算法的输入。
下图是实例格式化的说明和用于构造指令格式实例的常见的三种不同方法:
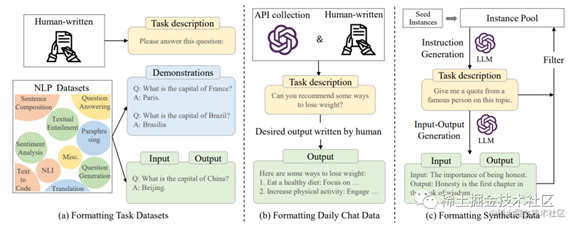 image.png
image.png
·
格式化任务数据集:这意味着将任务数据集中的数据整理成一种特定的格式,以便它们可以被用于训练机器学习模型。通常,格式化数据集的过程包括对数据进行清洗、标记、向量化等处理,以使其适合于机器学习算法的输入。例如,在文本分类任务中,可以将文本转换成词袋模型或词向量表示,并将其与相应的标签一起存储在数据集中。
·
格式化每日聊天数据:这意味着将每日聊天数据整理成一种易于分析的格式。例如,在社交媒体或在线论坛上收集的聊天数据需要进行预处理和清洗,以去除噪声和非重要信息。接下来,可以将聊天数据转换成一种结构化的格式,例如CSV或JSON文件,以便进行数据分析和可视化。
·
格式化综合数据:这意味着将多种数据源中的数据整理成一种一致的格式。综合数据可以来自不同的数据源,如数据库、文件、传感器等。在将这些数据整合在一起之前,需要将它们格式化成相同的格式,以便它们可以被合并和分析。例如,在一个电子商务网站中,可能需要将订单数据、用户数据和产品数据整合在一起,以便分析销售趋势和用户行为。在这种情况下,需要将这些数据格式化为相同的结构,例如JSON或XML格式。
2 调参Tuning:
调参是LLM训练过程中的一个重要环节,目的是找到最优的超参数组合,以提高模型在测试集上的性能。
那么,有几种常见的Tuning方法呢?
2.1 Instruction
Tuning
Instruction Tuning是通过添加一些人工规则或指令来对模型进行微调,以使其更好地适应特定的任务或应用场景。
Example:在文本生成任务中,可以添加一些指令来控制生成的文本的长度、内容和风格。
2.2 Alignment Tuning
Alignment Tuning是通过对齐源语言和目标语言的数据来对模型进行微调,以提高翻译或文本生成的质量。
Example:在机器翻译任务中,可以通过对齐源语言和目标语言的句子来训练模型,以提高翻译的准确性。
2.3 RLHF(reinforcement learning
from human feedback)三阶段
RLHF是使用强化学习算法来对模型进行微调,以使其更好地适应特定的任务或应用场景。
该技术通常分为三个阶段:有监督微调、奖励模型训练和强化学习微调。在RLHF微调阶段,模型会通过与人类交互来学习如何生成更符合人类预期的文本。
下图是RLHF算法的工作流程:
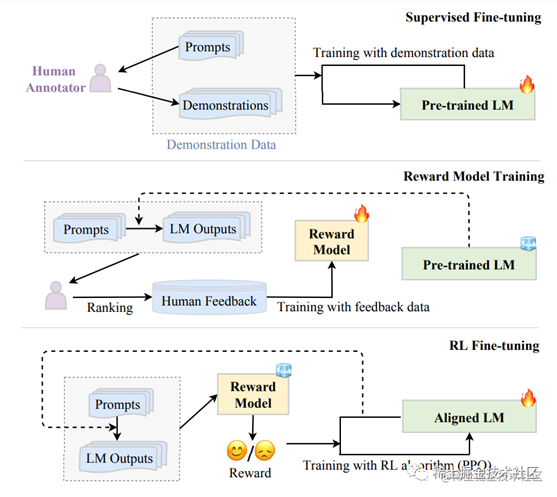 image.png
image.png
2.4 Adapter Tuning
Adapter Tuning是在预训练模型中添加适配器层,以适应特定的任务或应用场景。适配器层可以在不改变预训练模型权重的情况下,对特定任务进行微调。这种技术可以提高模型的效率和泛化能力,同时减少对计算资源的需求。
2.5 Prefix Tuning
Prefix Tuning是通过在输入中添加一些前缀来对模型进行微调,以使其更好地适应特定的任务或应用场景。前缀可以提供一些额外的信息。
Example:任务类型、领域知识等,以帮助模型更准确地生成文本。
2.6 Prompt Tuning
Prompt Tuning是通过设计合适的Prompt来对模型进行微调,以使其更好地适应特定的任务或应用场景。提示是一些关键词或短语,可以帮助模型理解任务的要求和期望输出的格式。
2.7 Low-Rank
Adaptation(LoRA)
LoRA是通过将预训练模型分解成低秩矩阵来进行微调,以提高模型的效率和泛化能力。该技术可以减少预训练模型的参数数量,同时保留模型的表示能力,从而提高模型的适应性和泛化能力。
下图是2.4 2.5 2.6 2.7四种调参方法的对比示意图:
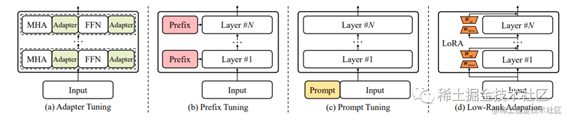 image.png
image.png
七、LLM的Utilization
Utilization是在预训练或自适应调优之后进行的,一种典型的提示方法是上下文学习,它以自然语言文本的形式制定任务描述或演示。
此外,思维链提示可以通过在提示中加入一系列中间推理步骤来增强上下文学习。对于复杂任务的求解,提出了规划,首先将复杂任务分解为更小的子任务,然后生成一个行动计划来逐个解决这些子任务。
LLM大致可分为Pre-train阶段、Tuning阶段,使用Prompt阶段。
·
Pre-train让预训练模型获得基本的语言能力。
·
Tuning阶段对模型调优增强其语言能力、使模型输出符合正确的价值观。
·
Prompt方法,比如ICL和CoT,可以提高模型的推理能力。
接下来,我们将简要介绍这三种Prompt技术,长话短说:
1 In-Context Learning语境学习
语境学习旨在通过模型自身的学习过程来改进其在特定上下文中的表现。通过对模型进行反馈和调整,可以使模型逐渐适应不同的语境和场景,从而提高其在各种任务中的性能和泛化能力。
2 Chain-of-Thought Prompting思维链提示
思维链提示通过提示来引导模型生成连贯的、具有逻辑关系的文本。
该技术基于思维链的概念,即人们在思考时通常会按照一定的逻辑顺序组织思维和语言。通过在生成文本时引导模型按照特定的思维链顺序组织文本,可以使生成的文本更加连贯和合理。
下图是情境学习ICL和思维链CoT提示的对比说明。ICL用自然语言描述、几个演示和一个测试查询提示LLM,而CoT提示涉及提示中的一系列中间推理步骤:
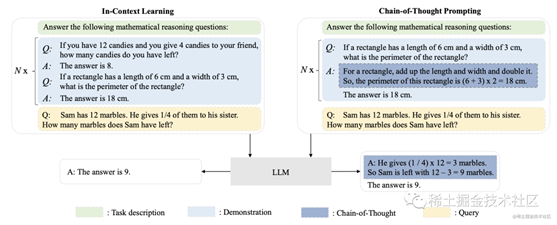 image.png
image.png
3 Planning for Complex Task Solving解决复杂任务的计划
其实就是分治,通过将任务分解为多个子任务,并为每个子任务制定计划来解决复杂任务的技术。
该技术可以帮助模型更好地理解任务的结构和要求,从而更有效地解决复杂任务。此外,该技术还可以通过对任务和子任务之间的依赖关系进行建模,来提高模型的泛化能力和鲁棒性。
By the way,LLM的涌现实际上也表现在这几个方面。
下图是LLM解决复杂任务的基于提示的规划公式示意图:
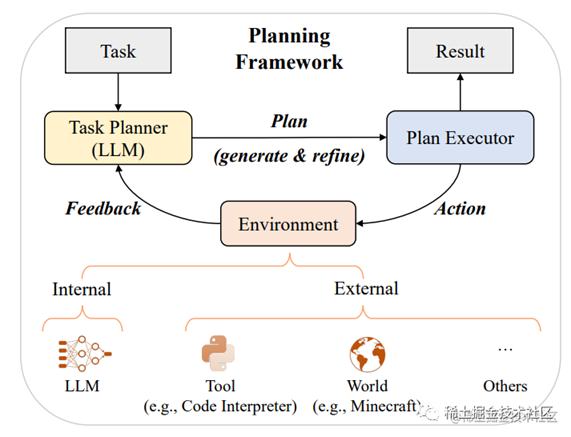 image.png
image.png
八、LLM的Capacity Evaluation
1 基础能力评估
1.1 文本生成
·
Language Modeling语言建模:
·
这是评估LLM基础能力的一种常用方法,即根据前n个token预测第n+1个token。常用的评估指标包括准确率、困惑度等。我们就困惑度PPL做一个更详细的说明:Perplexity困惑度一般来说是用来评价语言模型好坏的指标。语言模型是衡量句子好坏的模型,本质上是计算句子的概率。
·
为什么PPL使用的是几何平均数呢?是因为,当数据最终结果是一个和时,用算术平均数更合适,当数据最终结果是一个积时,用几何平均数更加合适。
·
除此之外,机器翻译经常使用的BLEU指标也是使用了几何平均数。
·
·
Conditional Text Generation条件文本生成:
·
包括机器翻译、文本摘要等任务,评估指标常用的有BLEU、ROUGE等。
·
·
Code Synthesis代码生成:
·
评估指标主要是与人类生成的代码进行比较。
·
1.2 知识运用
·
开卷问答和闭卷问答:评估模型对于知识的理解和应用能力。
·
知识补全:评估模型对于知识图谱等知识库中缺失的信息进行推断的能力。
·
复杂推理:包括基于知识推理、符号推理和数学推理等,用于评估模型的推理能力。
主要挑战:幻觉和缺乏最新的知识。其中幻觉分为内在幻觉(与现有的来源冲突)和外在幻觉(无法被可用的来源验证)。
1.3 复杂推理
·
基于知识推理:通过利用事先获取的知识来推导出新的结论。
·
符号推理:通过对符号或逻辑表达式进行操作,推导出新的逻辑结论。
·
数学推理:通过数学公式、定理和证明等方式,推导出新的数学结论。
2 复杂能力评估
·
Human Alignment(人类价值观一致性):
·
评估模型是否与人类积极的价值观保持一致,例如尊重个人隐私、避免歧视等。
·
·
Interaction with External Environment(与外部环境交互):
·
评估模型在具身智能(embodied AI)任务中的能力,例如机器人导航、语音助手等。
·
·
Tool Manipulation(使用外部工具):
·
评估模型使用外部工具(例如浏览器、计算器等)的能力,例如webGPT使用浏览器作为工具,ChatGPT的计算器插件等。
·
九、提示设计
注意,此处与原文有出入,我们选择了一些原文中提到的细节,但也添加了一些新的内容。
Prompt Creation: 关键成分,设计原则,有用技巧。
1 Key Ingredients关键成分:
1.
Task-specific information: 提示需要包含与任务相关的信息,例如问题描述,输入格式和输出格式等。
2.
Contextual information: 上下文信息可以帮助LLM更好地理解任务,例如领域知识,背景信息和先前的对话历史等。
3.
Examples: 提供示例可以帮助LLM更好地理解任务和期望输出,例如输入/输出示例,解释示例和错误示例等。
4.
Constraints: 约束可以帮助LLM生成符合要求的输出,例如长度约束,格式约束和限制词汇等。
2 Design Principles设计原则:
1.
Clarity and simplicity: 提示应该清晰简洁,易于理解。
2.
Relevance and specificity: 提示应该与任务相关,具体而不是模糊的。
3.
Diversity and adaptability: 提示应该具有一定的多样性和适应性,以适应不同的任务和情况。
4.
Consistency and coherence: 提示应该与任务的目标和期望输出保持一致,同时保持逻辑上的连贯性和流畅性。
3 Useful Tips有用技巧:
1.
Start with a clear goal: 在设计提示之前,需要明确任务的目标和期望输出。
2.
Use natural language: 尽可能使用自然语言来描述问题和期望输出,以帮助LLM更好地理解任务。
3.
Provide examples: 提供示例可以帮助LLM更好地理解任务和期望输出。
4.
Test and iterate: 在设计提示之后,需要进行测试和迭代,以不断改进提示的质量和效果。
十、结论与展望
我们回顾了LLM的最新进展,并介绍了理解和利用LLM的关键概念、发现和技术。
我们重点关注大模型(即大小超过10B的模型),同时排除早期预训练语言模型(例如BERT和GPT)的内容,特别是,我们的调查讨论了LLM的四个重要方面,即预训练、适应调整、利用和评估。对于每个方面,我们突出了对LLM成功至关重要的技术或发现。
此外,我们还总结了开发LLM的可用资源,并讨论了复现LLM的重要实施指南。
接下来,我们总结了本次调查的讨论,并介绍了LLM在以下方面的挑战和未来方向:
1.
提高效率和准确性:LLM需要更高的效率和准确性,以适应越来越多的任务和应用场景。
2.
改进预训练模型:需要进一步改进预训练模型的结构和技术,以提高LLM的性能和效率。
3.
解决过拟合问题:需要解决LLM在特定任务上的过拟合问题,以提高模型的泛化能力。
4.
多模态LLM:需要扩展LLM的能力,使其能够处理多种不同的输入类型,例如图像、语音和视频。
5.
研究LLM的可解释性:需要进一步研究LLM的内部机制和决策过程,以提高其可解释性和可信度。
出自:https://mp.weixin.qq.com/s/F1EQaQC4xWzWeBgi12cwXw