搞大模型训练,最重要的就是高质量的数据集。所以得数据者得天下。全球最大的AI开源社区Huggingface上,已经有5万多的开源数据集了,其中涉及中文的数据集只有区区可怜的151个。中国的AI产业要迎头赶上,中文的数据集是最大的短板之一。
CTO范凯
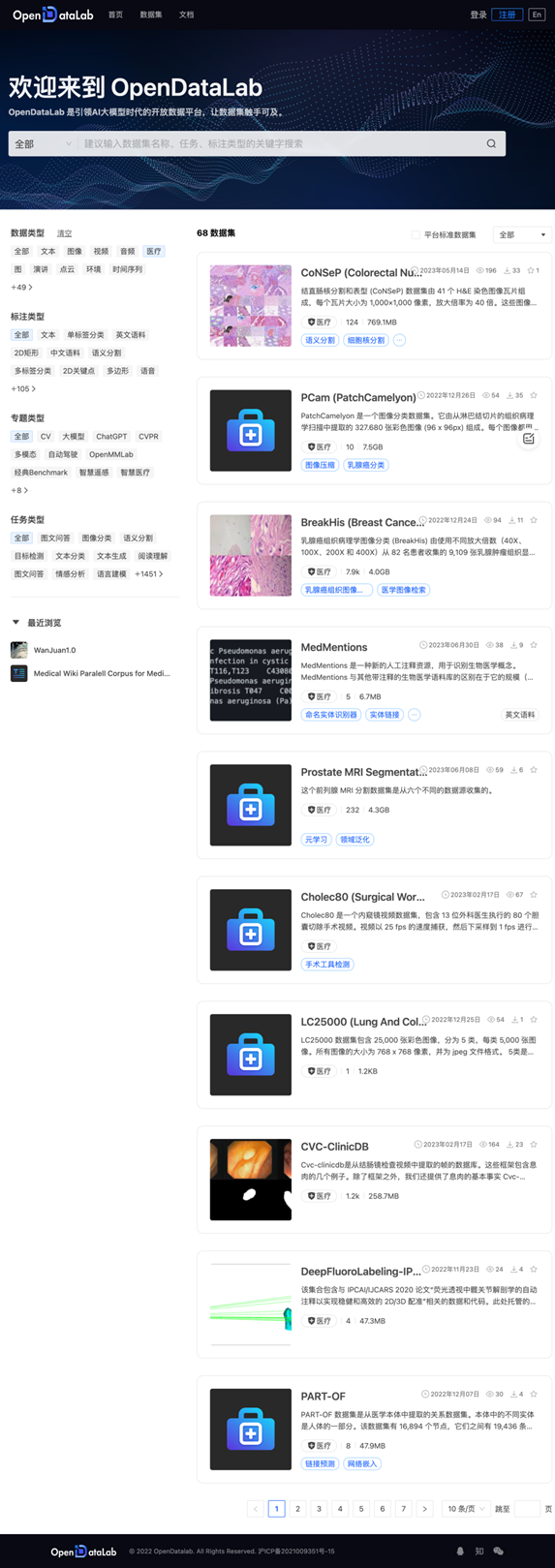
好在上海人工智能实验室搞了一个OpenDataLab,上面发布了5000+的中文的开源数据集,可以随意下载下来,用来训练自己的AI大模型的,真的是功德无量啊。
我看最近OpenDataLab自己发布一份非常齐全的用来做大模型预训练的中英文语料库,叫做:「书生·万卷」,取意于:读书破万卷之意。
书生·万卷这个语料库,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。既然包含了文本、图像和视频数据,所以完全可以拿过来训练多模态的大模型了。
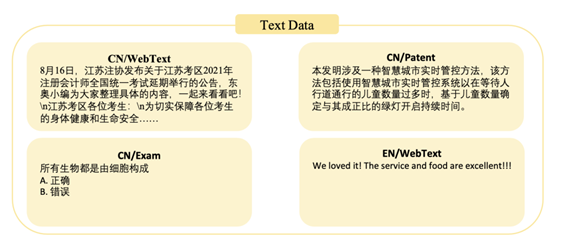
其中的文本数据集,来源于网页、维基百科、专业书籍、教材和考试题,超过5亿个文档。中文和英文大约各占一半。

其中的图像数据集,主要来源于网页、维基百科等,大约2220万个文档。

视频数据不多,主要来自央视和上海卫视的电视节目,大约1000+个视频。这个视频数据说实话不太行:一方面是数据太少,另一方面视频的来源过于单一,所以价值不太大。
但不管怎么说,这都是我看到的第一个包含了多模态的开源数据集,总的容量也超过了2TB了。对于国内的很多想搞开源的大模型,或者想基于LLaMA
2预训练中文大模型来说,这个数据集也算是弥足珍贵了。毕竟,高质量的中文数据集实在太稀缺了,要自己从头来积累数据集,都是一个旷日持久的事情。
另外,OpenDataLab上还是有不少好的数据的,特别是「医疗」领域,颇有一些不错的数据集,真是是一个宝库。
最后还是希望中文的高质量开源数据集多多益善,中国的AI社区发展越来越好。
出自:https://mp.weixin.qq.com/s/-_Tg1y2xxZpMulHQoIqdrQ