第二部分:斯坦福大学加州小镇观察
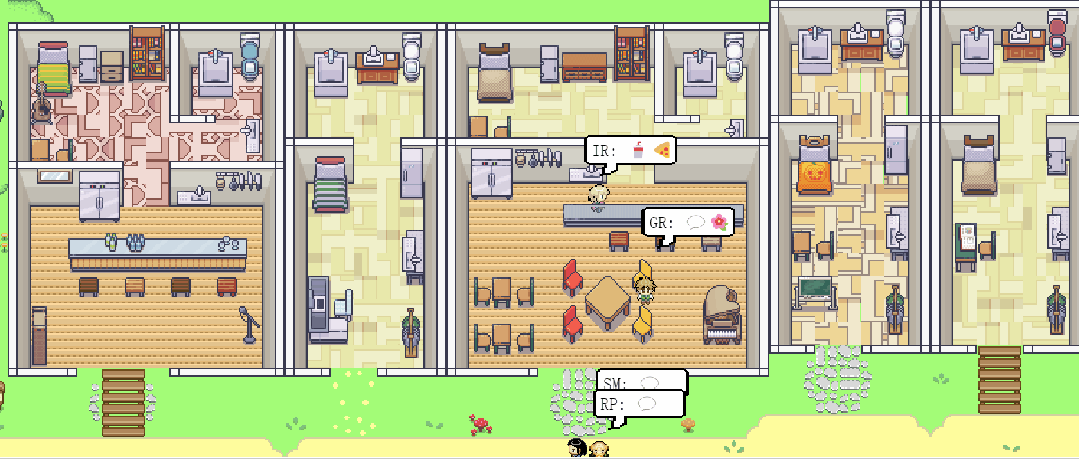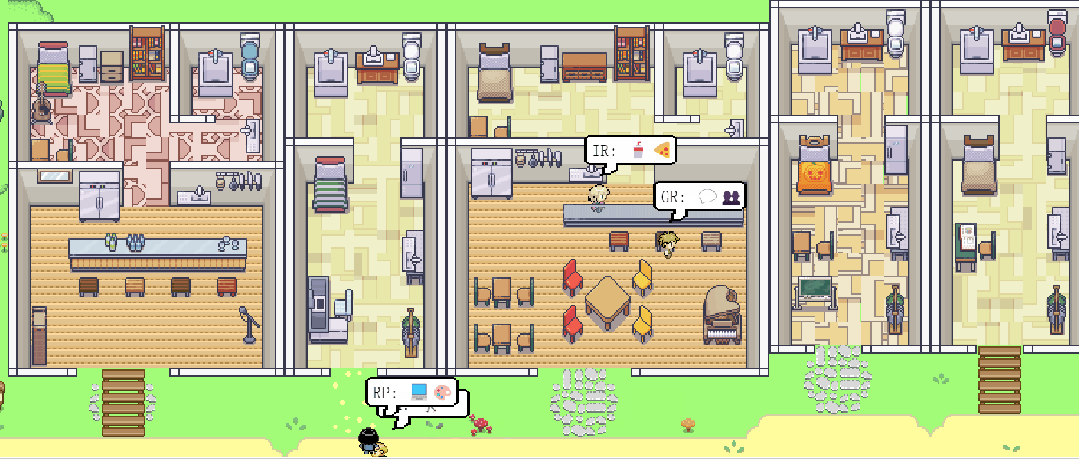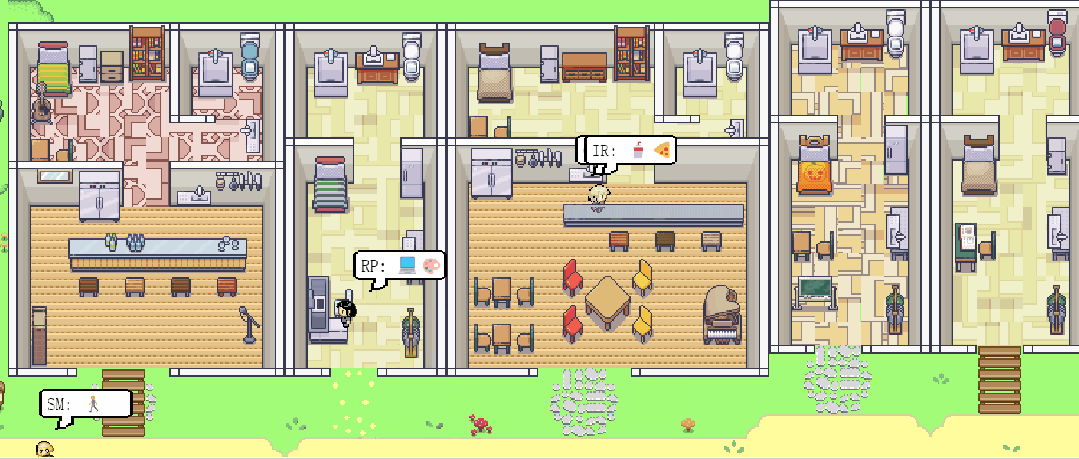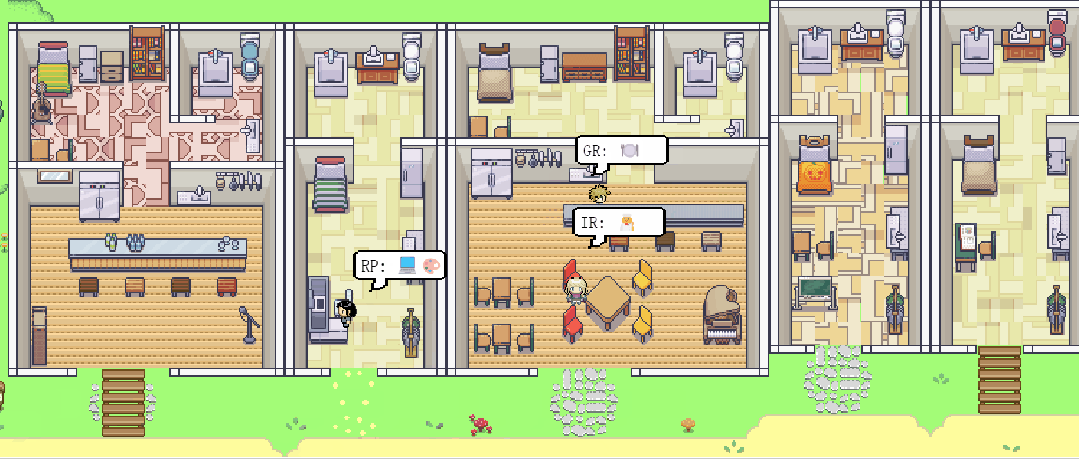
斯坦福大学和Google的研究团队发表了一篇《Generative Agents: Interactive Simulacra of Human Behavior》的论文,论文中介绍了一个应用大语言模型实现模仿可致信人类行为的生成式智能体。研究团队创造了一个虚拟社区,通过应用大语言模型以自然语言的方式存储并合成了多个智能体的经验、记忆和计划。这些智能体被隔离在一个类似于模拟人生的可交互的沙盒环境中,人类用户可以使用自然语言和智能体直接交互。生成式智能体的行为和互动虚拟智能体简介虚拟社区包含25个独立智能体,每个智能体都有自己的独特性格,居住在一个名为Smallville的封闭空间中。每一个智能体的身份、职业和与其他人的关系,都包含在一个一段话的提示词之中。
例子:Hailey Johnson
内在倾向:想象力、精力旺盛、有资源
经验倾向:HJ是一个作家,总是寻找新的方式去讲故事。她喜欢把自己沉浸到不同的文化之中并且探索他们的文学作品。
当下状态:HJ正在写一部关于一群艺术家在一个共同空间一起居住的故事。她还在计划做一个播客。
生活方式:HJ一般凌晨2点睡觉,早上10点起床,傍晚6点吃饭。
在沙盒环境中,每个智能体都使用自然语言和行动与环境及其他智能体进行互动。智能体会通过输出一段自然语言描述他们的行动,如”IR正在写她的日志“。这段文字会被转换成一个具体的行动影响沙盒环境并在页面上展示出来,同时大语言模型会把智能体的行动以一个表情包的方式展示出来。智能体会使用自然语言和其他智能体进行沟通,一个智能体能否见到以及是否会和一个智能体沟通会被系统架构所影响。人类用户可以以两种方式影响智能体的行为:与智能体对话或者给智能体发出一段的”内心声音“。比如用户可以向智能体John发出一段”内心声音“让他参加选举与另一个候选人竞争,John会决定参训并与他的家人分享他的想法。环境交互所有25个智能体都居住在这个名为”Smallville“的虚拟社区,里面有餐厅、酒吧、公园、学习、宿舍、住房、商店等等。智能体会在虚拟社区里面逛来逛去与环境及其他智能体互动。人类用户可以以其中一个角色或者访客形式进入社区。智能体和人类用户都可以影响虚拟社区中物体的状态,比如用户可以使用自然语言把厨房”炉子(stove)“的状态从”开启“到”点燃“,智能体就会根据炉子的状态做出反馈。此外,智能体也会自动根据环境的变化,比如修理一个坏了的莲蓬头,而做出反应。涌现出的社会行为智能体会与其他智能体交换信息、形成新的关系,并且共同组织活动,这些社会行为都是”涌现“而非提前编程实现的。信息扩散:智能体之间会相互接触、进行对话,对话中所包含的信息会从智能体到智能体传播。关系记忆:智能体之间会形成新的关系并形成互动的记忆。例如一个开始智能体Sam并不认识Latoya,但是在与她和Johnson
Park见面并了解了她的的摄影项目后,Jonh会记住他们之间的互动并在之后的见面中向Latoya询问摄影项目的进展。协作:在虚拟空间中,智能体之间会相互协作,Isabella本身被植入了组织情人节聚会的意图,她会邀请她的朋友和顾客来参加聚会。Isabella的朋友Maria喜欢Klaus,Maria也为聚会装饰了餐厅。Maria随后邀请了Klaus来参加聚会。在聚会当天,包括Maria和Klaus在内的共五个智能体都参加了聚会。人类用户仅仅是最初设定了Isabella想举办情人节聚会的想法和Maria喜欢Klaus,但是后续的信息传递、餐厅装扮、相互邀请和在聚会上的互动都是智能体自发生成的。
生成式智能体架构
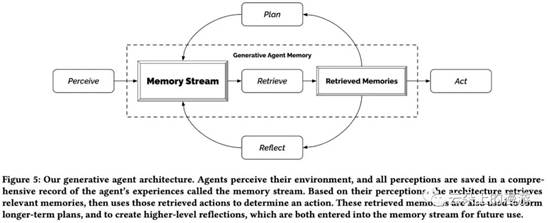
虚拟社区为智能体提供了一个开放式框架,可以让智能体之间相互协作并对环境变化做出反应。虚拟社区所基于的架构是:大语言模型+相关信息的综合与提取从而引导LLM的输出。存储了智能体所有记忆的数据库是整个架构的核心。目前架构所基于的大语言模型是OpenAI的GPT,智能体的核心组件包括”记忆、计划和反思“。记忆及提取

架构使用了记忆提取功能,在考虑到智能体现有状态的情况下会从记忆中提取子集。在提取子集的过程中,系统设定主要考虑三个要素:近期性,重要性和相关性
·
近期性:近期性会为近期访问的记忆分配更高的分数,使用指数衰减函数。
·
重要性通过为重要的记忆分配更高的分数来区分日常和核心记忆。语言模型被用来输出重要性的整数分数。
·
相关性为与当前情境相关的记忆分配更高的分数,基于一个查询记忆进行条件设置。语言模型为每个记忆的文本描述生成嵌入向量,相关性被计算为这些向量之间的余弦相似性。
最终的检索分数通过标准化并结合近期性、相关性和重要性的分数来计算,权重均等。适应语言模型上下文排名最高的记忆被包含在提示词中。反思如果智能体仅使用原始的观察记忆,很难进行泛化或推断。为了解决这个挑战,开发者引入了第二种类型的记忆,“反思”。反思是智能体生成的更高级、更抽象的思考,并与观察记忆一起纳入推理过程之中。当近期事件的重要性分数之和超过某个阈值时,会触发周期性的反思生成。智能体每天反思大约两到三次,使它们能够做出更好的决策和泛化。反思过程涉及智能体根据其近期经验识别的显著问题。它们使用最近100条记忆记录查询大语言模型并生成候选问题。这些问题随后会被提取,相关的记忆会被收集。大语言模型提取见解,并引用记录作为这些见解的证据。然后,这些见解作为反思存储在记忆流中,还附有指向被引用记忆对象的指针。反思可以基于观察和其他反思,创建一个树状结构,树状结构的上部有更抽象、更高级的思考。示例:
·
提取最近的100条记录(例如:“Klaus Mueller正在阅读有关士绘化的书”,“Klaus
Mueller正在与图书管理员讨论他的研究项目”);
·
向大语言模型输入提示词:“根据上述信息,我们可以回答关于记录主题的3个最显著的高级问题是什么?”
·
大语言模型生成问题示例:“Klaus Mueller对什么话题充满激情?”
·
使用这些问题作为检索的查询,并检索相关的记忆;
·
提取见解:
关于Klaus
Mueller的记录;Klaus Mueller正在写一篇研究论文;Klaus Mueller喜欢阅读关于绘化的书;Klaus Mueller正在与Ayesha Khan讨论锻炼[…]从上述记录中,你可以推断出哪5个高层次见解?(示例格式:见解(考虑记录1, 5, 3))
计划和反应
虽然大型语言模型可以生成看似合理的行为,但难以保持长期的连贯性。为了解决这个问题,开发者设计了让智能体使用制定计划来保持其行为随时间的一致性。智能体的计划描述了一系列未来的行动,包括地点、开始时间和持续时间。计划的内容存储在记忆流中,允许智能体在决定如何行动时考虑观察、反思和计划。如有必要,智能体也可以在中途更改其计划,确保行动更为可信。为了为智能体创建现实和有趣的计划,该方法从上到下开始,并递归生成更多的细节。首先,根据智能体的简要描述和前一天的活动,创建一个初始计划,概述当天的日程。这个计划被保存在记忆流中,然后分解为细颗粒度的动作,以一小时为单位,然后进一步分解为5-15分钟的块。粒度的级别可以根据需要进行调整,以便为智能体的活动提供详细和吸引人的计划。反应与更新计划。生成型智能体在行动循环中运行,感知周围的世界,并在其记忆流中存储观察结果。语言模型使用这些观察来决定智能体应该继续他们现有的计划还是对情况作出反应。当需要作出反应时,使用相关查询生成上下文摘要。从反应的时间开始重新生成智能体的现有计划。如果行动涉及智能体之间的互动,会生成它们之间的对话。示例:[智能体的简要描述]现在是2023年2月13日,下午4:56。John Lin的状态:John提前下班回家了。观察:John看到Eddy在他的工作地点附近散步。从John的记忆中提取的相关上下文摘要:Eddy Lin是John Lin的儿子。Eddy Lin一直在为他的课程制作音乐作品。Eddy Lin喜欢在思考或聆听音乐时绕花园走走。John应该对观察作出反应吗?如果需要,什么反应才合适?沙盒环境的实现Smallville沙盒游戏环境使用了Phaser网页游戏开发框架。服务器对该框架进行了补充,使沙盒中的信息可以被智能体所使用,让智能体能够移动并影响环境。服务器维护关于每个智能体信息的JSON数据结构,并对其进行任何更改的更新。为了使智能体的推理与沙盒世界联系起来,环境被表示为一个树状数据结构。此树状结构会转化为自然语言供智能体使用。评估智能体旨在基于它们的环境和经验产生可信的行为。这些智能体的评估分为两个阶段。首先,评估单个智能体的反应,以了解它们在特定上下文中是否产生可信的行为。然后,对智能体社区在两个整天内全面分析,检查它们作为一个整体的紧急行为,包括错误和边界条件,看它们是否可以展示信息扩散、关系形成和智能体间的协作。评估程序为了评估Smallville中的智能体,智能体被“采访”以探测它们维护自我知识、检索记忆、生成计划、反应和反思的能力。因变量是行为的可信度。采访包括五个问题类别,每个问题都被设计用于评估关键指标。两天游戏结束时从智能体中取样。为了收集关于智能体反应可信度反馈,开发者招募了100名人类评估者观看随机选择的智能体在Smallville的生活回放。评估者对同一智能体的四种不同智能体架构和一个人类作者条件生成采访反应的可信度进行排名。条件被评估的智能体架构与三种削减架构和一个人类生成条件进行比较。削减的架构对记忆类型(如观察、反思和计划)的访问受到限制。无观察、无反思、无计划状态代表了通过大型语言模型创建智能体之前的状态。为了提供一个人类基准线,一个独立工作者会扮演一个智能体,观看智能体的沙盒生活回放,并检查其记忆流。然后,他们以智能体的声音回答采访问题。人类生成的反应经过手工检查,以确保它们达到了基线质量。这一比较旨在确定架构是否通过了基本的行为能力水平。分析实验产生了100组排名数据,比较了每个条件的可信度。使用TrueSkill评级进行了可解释的比较。为了调查统计显著性,使用了Kruskal-Wallis检验和Dunn事后检验,使用Holm-Bonferroni方法调整p值。此外,开发者进行了归纳分析,研究每个条件中的反应之间的定性区别。结果结论是具备完整架构的生成型智能体产生了最可信的行为。在切除条件中去除每个组件后(如观察,反思和计划),智能体产生致信反应的性能下降。拥有完整记忆模块的智能体可以回忆过去的经验并根据他们的自我知识一致地回答问题,虽然他们的记忆并不是完美的。他们可能无法检索正确的例子,导致不完整或不确定的反应。虽然智能体很少编造知识,但它们可能会对其知识进行"幻觉"修饰或基于大语言模型已有的真实世界知识来作出反应。反思对智能体来说至关重要,因为它能使他们综合自己的经验并做出合理决策。智能体能够访问反思记忆使其能够自信地回答问题,从过去的互动和知识中提取信息。在开发者提供的例子中,当Maria Lopez可以访问反思记忆时,她能够根据Wolfgang Schulz的兴趣为他建议一个生日礼物。涌现的社会行为
研究者通过跟踪两条信息的传播来研究虚拟环境中智能体的信息扩散:Sam竞选村长和Isabella的情人节派对。开始时,只有Sam和Isabella知道这些事件。经过两个游戏天后,对25个智能体进行了访问,分析了他们的回应,以确定他们是否知道这些信息。如果回应表示知道,就标为“是”,如果不知道就标为“否”。研究还通过检查他们的记忆流验证了智能体没有幻觉他们的回应。研究者还研究了智能体之间的关系形成和协作性。在模拟开始和结束时,询问智能体对其他智能体的了解情况。如果两个智能体都知道对方,就认为他们之间形成了关系。此外,研究者还调查了智能体进行团体活动的协作能力,如Isabella的情人节派对。智能体需要听说这个活动并计划在正确的时间和地点参加。在模拟中,研究观察到了涌现的结果。在没有用户干预的情况下,知道Sam竞选村长的智能体从4%增加到32%,知道Isabella派对的智能体从4%增加到48%。网络密度从0.167增加到0.74,表示形成了关系。关于智能体对其他智能体的了解情况的回应中,只有1.3%是幻觉。在协作方面,受邀参加Isabella派对的12个智能体中有五个参加了。其中七人没有参加,三人表示有冲突,四人表示有兴趣但没有计划在派对当天来。边界和错误研究者发现了三种常见的智能体的异常行为模式:随着智能体了解更多的位置,他们在选择最相关的信息和在适当的空间采取行动时遇到了挑战,这导致他们的行为随着时间的变化而变得不那么可信。例如,他们起初在咖啡馆吃午饭,但后来在了解到附近的酒吧后,他们选择去那里。由于位置的物理规范没有被正确地转化为自然语言,导致智能体没有正确选择适当的行为。例如,几个人同时访问了宿舍的浴室。指令调优使智能体变得过于有礼貌和有协作性,导致对话过于正式,智能体很少拒绝别人的建议,即使这与他们的兴趣不符。这也导致智能体的兴趣会随着时间的推移受到他人的影响。
讨论生成型智能体的应用生成型智能体可以用于填充在线论坛、元宇宙,甚至在物理空间中作为社交机器人。另一个应用是在以人为中心的设计过程中,生成型智能体可以作为用户的代理,学习他们的行为模式和偏好。这将允许更个性化和有效的智能体验,如自动冲咖啡、处理例行程序,以及调整环境设置以匹配用户的心情。未来的研究工作和局限性 对生成型智能体的未来研究可以集中在改进架构、性能、成本效益和实时交互性上。伦理和社会影响 生成型智能体引发了伦理上的关注,包括偏见社交关系的风险、错误的影响、现有AI风险的加剧和过度依赖。为了解决这些问题:
·
生成型智能体应该公开他们的运行机制并与价值对齐,以避免不适当的行为。
·
在不同的应用领域,重要的是遵循人与AI交互的最佳实践,以了解错误及其对用户体验的影响。
·
通过维护输入和输出的审计日志,允许检测和干预恶意使用,从而减轻与错误信息和有害信息相关的风险。
·
在设计过程中,生成型智能体不应取代人的主导。
·
遵循这些原则确保了部署生成型智能体的伦理和社会责任。
出自:https://mp.weixin.qq.com/s/RVkHmq6RcCHjNSf0pHKgjw