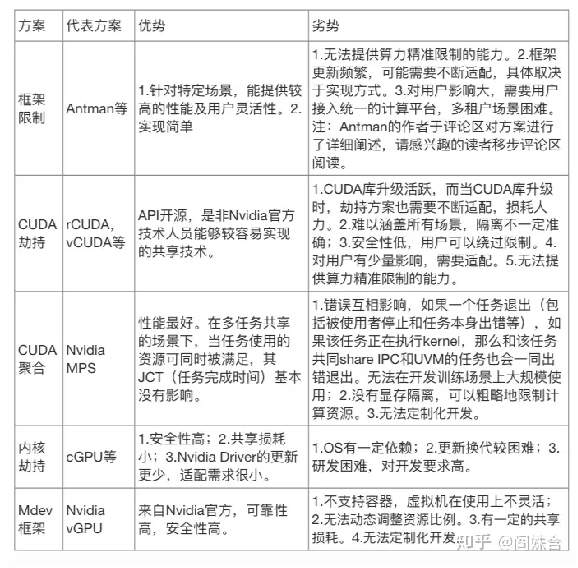
进年来工业界一直孜孜不倦地寻求提升GPU利用率的方案,能被更多用户理解和使用的GPU共享走进工程师的视野中。本文将总结目前有公开PR的、来自工业界的部分GPU容器计算共享方案,看看工业界对GPU共享的定位和需求。本文将依旧着眼于unix-like os上计算容器场景的资源隔离能力,不包括win os,VM,视频,游戏相关方案。受限于笔者能力,可能出现一些错漏,希望多多指正。
首先,回顾一下GPU共享方案的分类[21]。以下类型中,仅CUDA聚合为空分,其余为时分。
阿里 cGPU
来自阿里的cGPU(container
GPU)[1]是最早提出的通过内核劫持来实现容器级GPU共享的方案。cGPU实现了一个内核模块cgpu_km,该模块可以对一个物理GPU虚拟出16个虚拟GPU设备。在容器挂载设备时,修改后的container runtime将挂载虚拟GPU设备,而不是真实GPU设备。通过这种方式实现了GPU劫持。当用户程序的请求下发至内核模块cgpu_km时,模块通过修改请求及回复来限制GPU显存资源。同时,内核模块也实现了简单的算力调度,通过限制每个容器可下发kernel的时间片来隔离算力资源。可以提供公平/抢占/权重三种算力分配模式。值得注意的是,cGPU目前不能中止已经发送到GPU上的请求,因此如追求算力隔离,需要延长时间片的长度,会造成一定的算力浪费。出于某些考虑未有开源。
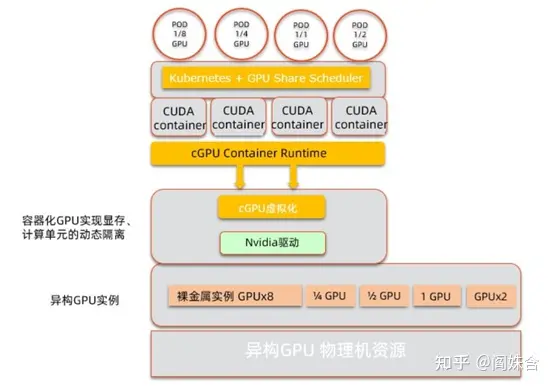
既然是容器级的GPU共享,接入到K8s的组件是必不可少的。阿里开源了相应的device plugin[3]和调度器[2]。设计的device plugin提供的核心资源是显存,这和cGPU是一脉相承的。另外由于当前K8s支持的资源类型是一维的,而GPU共享资源是二维的。为了实现调度能力,应用了一些tricky 的技巧,也让device plugin不得不和APIServer直接通信。
腾讯 GaiaGPU
腾讯提供了一整套GPU共享解决方案GaiaGPU[4],是完全开源的GPU共享方案,salute。GaiaGPU中的vCUDA(virtual CUDA)[5]是GPU资源限制组件,属于CUDA劫持。vCUDA通过劫持CUDA的显存申请和释放请求,为每个容器管理它的显存使用量,进而实现了显存隔离。唯一需要注意的是申请context并不通过malloc函数,因此无法知道进程在context使用了多少显存。因此vcuda每次都去向GPU查询当前的显存使用量。在算力隔离方面,使用者可以指定容器的GPU利用率。vCUDA将会监控利用率,并在超出限制利用率时做一些处理。此处可以支持硬隔离和软隔离。两者的不同点是,如果有资源空闲,软隔离允许任务超过设置,而硬隔离不允许。由于使用的是监控调节[22]的方案,因此无法在短时间内限制算力,只能保证长时间的效率公平。所以不适合推理等任务时间极短的场景。
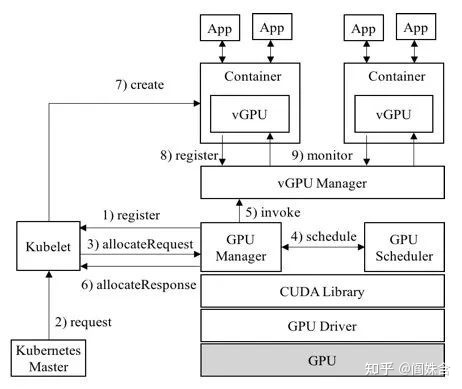
GaiaGPU也提供了Device
plugin GPU manager[6]和调度器 GPU admission[7],GPU admission既允许用户申请一张虚拟卡,也允许用户像之前一样申请一机多卡,这可能可以满足一些小型集群的需要。GPU manager除实现了device plugin该实现的,也做了很多繁杂的功能,使得apiserver的负担更重了。
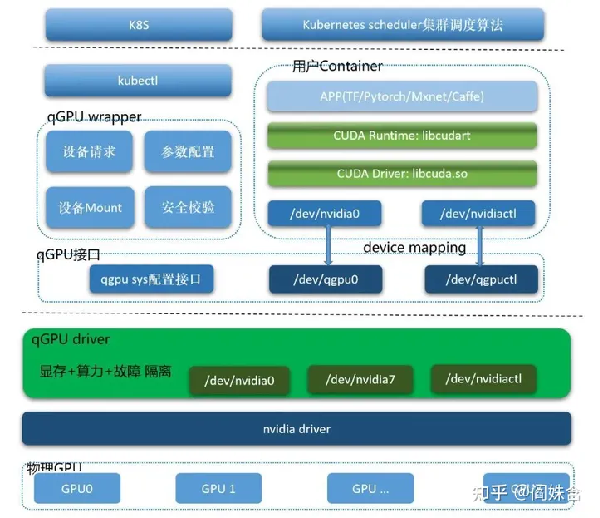
腾讯 qGPU
腾讯在内核劫持类GPU共享方向上,也推出了资源隔离方案qGPU(qos GPU)[8]。从架构图中就可以看出,qGPU和同属于内核劫持方案的cGPU类似。但值得注意的是,qGPU效仿Nvidia vGPU在必要时context switch,实现了强算力隔离,这也是其名字的由来。出于某些考虑未有开源。
百度 MPS+CUDA Hook的GPU隔离方案
百度推出的GPU共享方案[9]也是一个CUDA劫持方案,通过经典CUDA劫持限制显存,在算力隔离方面使用了MPS。没有开源代码。MPS在限制算力方面,除了众所周知的错误影响问题,其实算力限制并不严格,且无法根据GPU状态灵活调节算力的限制。期待下一代方案。
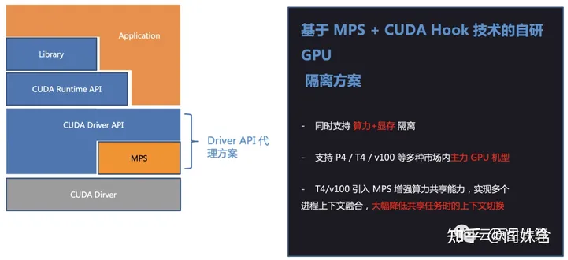
在K8s接入部分,也实现了Device
plugin和调度器extender,不过未开源。

爱奇艺 vGPU
爱奇艺的GPU共享方案也叫vGPU(和Nvidia的虚拟机方案vGPU重名)[10],也是CUDA劫持方案。在显存隔离上也是使用了经典的CUDA函数劫持的方法,由于没有开源代码因此不清楚context问题是如何解决的。在算力隔离方面比较特别,和RTA2019的Fractional GPU[11][12]思想颇为近似,通过将kernel限制在某些SM上来限制使用部分算力。但这实质上是一种空分的方法,需要将上下文合并才可以实现共享GPU,因此也会有错误传播的问题,场景限制颇大。
在K8s接入部分,使用和阿里同样的方案。
第四范式 OpenAIOS vGPU
第四范式的GPU共享方案还叫vGPU[13],也是CUDA劫持方案。由于没有开源资源隔离部分的代码,从文档中推测,其实现和GaiaGPU的vcuda较为类似:显存隔离使用的是经典CUDA劫持方法,通过预估获得context大小;使用监控隔离的方案隔离算力。同样地,方案的优缺点也和vCUDA类似。较为特别的一点是,和阿里Antman[18]相同地,第四范式vGPU通过Nvidia UVM实现了虚拟显存。不过UVM实质上是使用内存来虚拟显存,因此会消耗较大的内存,且性能会有较大下降。若要使用虚拟显存功能,还需思考程序本身占用的内存和虚拟显存的trade off。
第四范式开源了device plugin[14],使用了和nvidia device plugin中处理MIG设备一样的思路,将节点上所有虚拟GPU设备设定为同一大小。这丧失了一定的用户自由,但对大型集群来说,这样做更通用且更容易维护。同时,采用这种方案不需重新设计调度器。
AWS aws-virtual-gpu
AWS提供了一套非常简单的GPU共享方案[15],该方案通过tensorflow框架的参数per_process_gpu_memory_fraction实现了显存隔离,通过MPS的CUDA_MPS_ACTIVE_THREAD_PERCENTAGE实现了算力的限制。方案受限于tf框架,且使用了MPS,显然是个玩具之作。
在接入K8s方面,AWS开源的device-plugin[16]没有考虑资源的二维关系,实现了非常简化的资源allocate。

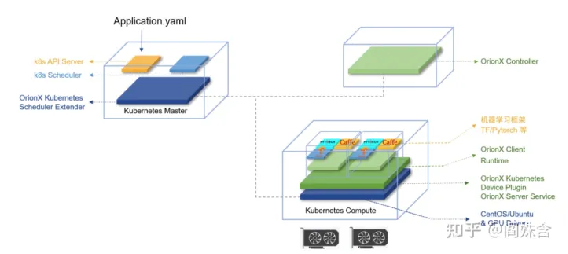
趋动科技 OrionX
趋动科技在AI算力资源池化解决方案OrionX中实现了GPU共享的能力[17]。在资源隔离方面,使用了CUDA劫持的方案,通过MPS以及其他方式限制算力。OrionX中也包含定制的device plugin和调度器方案,亦无开源。
另,OrionX属于GPU池化类解决方案,GPU资源隔离仅为OrionX的部分能力,详细请参见评论区。
总结
通过列举上述方案,可以看出各大公司主要还是处于试验期,应用尚不成熟。在设计上,倾向于对用户更易使用的,更通用的方案,而非考虑计算任务特性进而定制适合的方案。对规模很大的云场景,面向更多类型和水平的用户,如此设计是必行之举。对于GPU共享,一些资深工程师亦有深刻意见[19][20],讨论分析了在不同场景下技术的适用性问题。也推荐读者兼听则明。
出自:https://zhuanlan.zhihu.com/p/398369404