自2022年底OpenAI发布ChatGPT以来,大模型涌现式的智能引起了世界的广泛关注,大模型在商业场景的应用方兴未艾。与大模型交谈时,我们惊讶于它可比真人的理解能力、创作能力,而究其根源,我们更惊叹于支撑大模型智能的海量高质量数据。可以说,数据的准备决定了大模型应用的成败。然而,针对大模型在垂直应用场景中的数据准备,还有诸多问题并不明确:在业务场景中,大模型对数据准备有什么要求?谁来参与数据准备?数据准备的工作中可能遇到哪些难点,有什么解决思路?本文将着眼于大模型在业务领域的优化训练,对这些问题做一下探讨。
01
大模型对于训练数据有何要求?
大模型在理解能力、推理能力、创作能力上的突破,建立在大量级、高质量的训练数据的基础之上。因此,无论是从政策法规的角度,还是从应用效果的角度,都需要对大模型的训练数据有一定的要求。
1.政策法规的要求
8月15日,国家网信办等7部门联合发布的《生成式人工智能服务管理暂行办法》正式施行。《生成式人工智能服务管理暂行办法》专门提出在训练数据选择上,要采取有效措施防止产生歧视;在预训练、优化训练中,要采取有效措施提高训练数据质量,增强训练数据的真实性、准确性、客观性、多样性,并在数据来源、知识产权、个人信息使用上满足相关法律法规。
2.业务应用效果的要求
从大模型的应用效果上看,其优劣很大程度上也取决于训练数据的质量。比如以ChatGPT为代表的大模型,其出色能力的基础即是高质量、多领域、多行业及多样性的海量丰富数据。针对大模型在商业银行垂直场景的应用,下面我们分环节、分场景地围绕大模型训练数据的要求进行探讨。 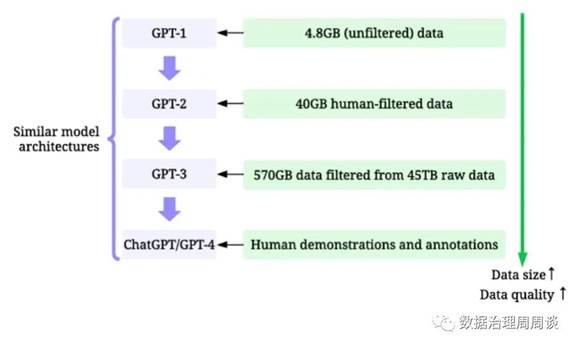
来源:Zha, D., Bhat, Z. P., Lai, K.-H., Yang, F.,
Jiang, Z., Zhong, S., & Hu, X. (2023). Data-centric Artificial Intelligence: A
survey. arXiv.org. https://arxiv.org/abs/2303.10158
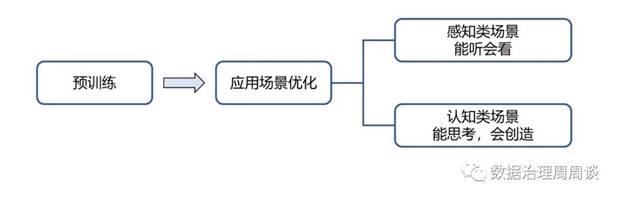
从训练环节上看,大模型的训练分为预训练和应用场景优化两个环节。比如ChatGPT,就是经过预训练后的通用大模型,展现出其在多领域的通用能力。同时,商业银行应用场景对于大模型回答的准确性、无害性要求高,仅依靠预训练大模型,容易产生张冠李戴、胡编乱造的问题。要想让大模型发挥潜力,产生业务价值,还需要对其进行应用领域知识的优化,就像应届毕业生要经过岗位培训后才能真正上手工作一样。
应用场景优化环节,又可以细分为两个场景:感知类场景和认知类场景来思考大模型对训练数据的要求。什么是感知类场景和认知类场景?简单来说,感知类场景就是“能听会看”,指的是有明确的规则,不需要理解复杂的逻辑即可完成任务的场景,比如OCR图片识别、语音转写、文本情绪判断等;而认知类场景要求的是“能思考、会创造”,需要在感知场景要素的基础上,进行复杂的理解、推理、创作,比如撰写营销文案,根据制度规范进行问答,编写代码等。
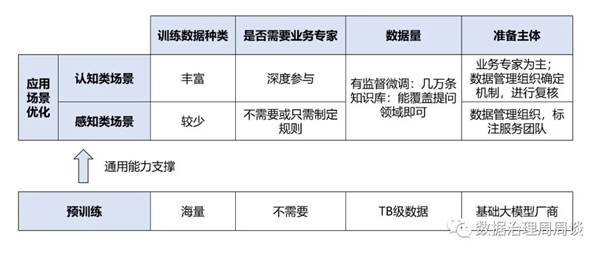
(1)预训练环节的要求
预训练环节,大模型对数据的要求是多领域、多类型的海量高质量数据,由OpenAI等基础大模型厂商负责准备。(2)感知类应用场景的要求应用场景优化中的感知类场景,对于训练数据种类的要求不高,不需要业务专家参与,一般可以由数据管理组织和标注服务团队进行准备。感知类场景所涉及的任务通常包括转写或分类等相对简单的操作,所用的数据类型包括原始材料和相应的转写、标签。这部分数据的准备依靠常识或简单规则即可完成,业务专家不需要参与,或者只需制定标注规则即可,具体的数据准备工作可以由数据管理组织和标注服务团队承担。(3)认知类应用场景的要求应用场景优化中的认知类场景,对训练数据有两个突出的要求,一是训练数据的种类要多,二是需要业务专家的深度参与,因此往往以业务专家为主,数据管理组织确定机制并进行复核。训练数据种类方面,认知类场景涵盖制度规定条款、操作说明、运营经验、传统知识库等业务文档,经过专家归纳整理生成的问答合集,以及实际工作中采集得到的客服对话等多种类型、来源的数据。参与人员方面,认知类场景中数据准备的专业性、场景性,都决定了它需要业务专家的深度参与。一是认知类任务的专业性强,依赖业务领域的专业知识,编撰训练数据时,需要结合不同来源的知识,进行复杂的推理、创作,才能给出有价值的回答;二是认知类任务的场景性强,对于大模型进行有监督微调时,需要业务专家编写真实业务场景中的提问和专业回答,利用prompt工程优化后,才能实现垂直领域的有效训练。在业务专家深度参与数据准备的同时,数据管理组织基于认知类数据标注中总结出的共性方法论,固化为机制流程、标注工具等,实现数据标注经验的有效共享。此外,数据管理组织还可以对训练数据进行复核,确保数据符合政策法规的要求。
02
大模型数据准备的难点
目前,大模型在商业银行领域还处于探索阶段,几无可借鉴的经验,企业在数据准备的实践中,可能会遇到跨项目规划和方法论不成熟,业务参与文化的建设难,以及知识更新管理等难点。大模型数据准备的难点,首先是跨项目规划和方法论不成熟:现阶段,大模型应用呈现烟卤式建设的特点,没有统一规划或方法论可以参考,导致项目的成功经验无法充分共享,数据准备无法复用的问题,影响企业级大模型应用的落地。同时,当前大模型的数据准备工作主要由技术人员完成,缺少业务专家的参与,这影响了大模型在复杂认知类场景中的应用效果。另外,目前大模型知识库的更新缺乏统一规范,可能向用户提供过时的信息,给大模型的推广应用带来风险。
03
数据准备难点的解决思路探讨
针对实践中碰到的工作难点,我们可以在管理层面和实施层面共同探索解决思路,创造高质量、高时效的训练数据,助推大模型释放业务价值。1.管理层面探索思路一是总结方法论,赋能大模型整体规划。梳理整合大模型项目数据准备工作中呈现的共性问题和推进方案,固化出数据准备的流程机制,以数据服务的模式整合不同项目的训练数据,实现数据互通,经验共享。以此为基础,可以为大模型的整体规划提供参考,评估大模型的优先发展领域。二是建设大模型应用中的业务参与意识和文化。对业务部门和业务人员开展大模型基础知识的培训,明确业务专家在大模型落地中的关键作用,推动大模型应用需求提出方的深度参与,聚焦业务最痛、感知范围最大的场景,尽快形成业务有感的落地成效,建立正反馈,促进业务人员形成对于大模型应用的主人翁意识。三是构建知识库更新管理机制。应在项目初期就明确知识库的责任人、更新速度、质量要求等,同时考虑到新增知识与存量知识的相互干扰问题,设立测试-审核机制,降低大模型知识更新不及时带来的业务风险。2.实施层面探索思路一是建立业务专家+标注团队+大模型生成协同机制。大模型的数据准备需要业务专家参与,但业务专家的时间价值高,因此建立辅助协同机制来减轻业务专家负担很有必要。基于大模型self-instruct自生成训练数据的能力,可以进一步尝试延伸为业务专家撰写问答样例+标注团队模仿编写更多问答+大模型自生成大量问答+业务专家审核修正的模式,充分发挥专家能力。二是完善数据准备工具,实现调优方案共享。比如,在大模型有监督微调的环节,往往需要按照prompt工程建议的格式进行提问。依托系统化工具,实现prompt工程模板的统一存储、共享、自动转换,并在不同项目间共享行之有效的prompt工程模板,大大加快有监督微调环节的数据准备效率。
04
结语
大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。大模型应用效果的基础是高质量的训练数据,这对业务领域训练数据的准备,尤其是认知场景训练数据的准备提出了更高的要求。针对数据准备实践中的难点,我们可以从管理层面和实施层面共同发力,建立跨项目的数据准备流程和管理机制,提升业务专家的参与度,规范知识更新的频率、流程,助推大模型应用尽快落地,产生业务价值。未来,大模型数据准备的规范化、体系化,有望加速大模型与金融服务的深度融合,对内革新信息获取、内容生成模式,对外重塑客户的交互体验。
出自:https://mp.weixin.qq.com/s/7O_QNmMdHXfY9hB9Gkx2Xw