Ai绘画有一个很现实的问题,要保证每次画出的都是同一个人物的话,很费劲。
Midjourney就不必说了,人物的高度一致性一直得不到很好的解决。而在Stable Diffusion(SD)中,常用办法是通过同一个Seed值(种子值),或者通过训练同一个人物的高质量Lora去控制。
Seed值控制虽然可大体达到目的,但是画出的人物姿态也高度趋同,而且稍微改变描述就会画出另外一个人来,而训练「高质量」模型则更费时费力。
直到最近SD的Controlnet插件推出了Reference only功能,这个问题才得到较好的改善。
一张稳定的人脸,配合不同的场景和动作,意味着角色人设可以得到继承和发挥。如应用到连贯的绘画场景中,例如漫画、虚拟角色设计等领域,意味着提高产能的可行性。
先看看效果。下面是SD画出的一张动漫人物参考图。

我们通过Reference Only功能,基于参考图去生成新的图片,大致效果如下(点击可看大图):

可以看到,在改变了姿势、场景、构图之后,人物的脸部特征,包括发型,仍然得到很好的保留,维持了高度统一的形象。
同时也留意到,人物服装只是部分相同。这个时候,如果要保持一致性,应该通过更详细的Tag描述去控制,具体指定服装的颜色、样式和风格等。
换个「真人」图看看。下图是SD画的参考图:

修改描述词后,通过Reference Only生成新的图片例:

以看到,“真人”效果和动漫人物效果结论相近,而且即使变换底模(大模型),人物脸部仍然可以得到很好的继承。
需要指出的是,在测试过程中发现:
1.并不是所有底模,都可以跟Reference only契合得很好,个别模型在成像过程中,有时候会出现色彩走样。
2.一些底模结合Reference only绘图时,并不总是支持多动作、多场景、多视角变换,个别场景很难被画出,例如,要把背景换成“大海”,即使“大海”的权重再高,也是无法实现,不知是何原因。
无论如何,Reference only可免去训练高质量模型即可保持人物一致,算是一个较大进步,如果下个版本可以解决上述2个问题,相信可以更好地赋能内容生产领域。
Reference only目前一共有3个预处理器可用,分别为:
Reference only:绘制与参考图类似的风格和脸部;
Reference adain:自适应规范,会更偏向于使用的模型,结果可能偏离参考图;
Reference adain+attn:结合了上述两种。
具体的安装使用方法如下:
.
确保你的controlnet版本为最新(如果你用的是整合包,很可能包含了最新版,或者可一键更新),地址如下(需科学上网):
Controlnet插件的安装和更新方法很简单,之前的文章也谈到过,或自己百度一下。
Reference only的官方说明:
2.建议在SD中生成参考图,并将参考图上传到Controlnet的图片作业区域,如下图界面:

3.勾选启用Controlnet,选择Reference
only三个预处理器中的一个,并将Style Fidelity值设置为1,如下:
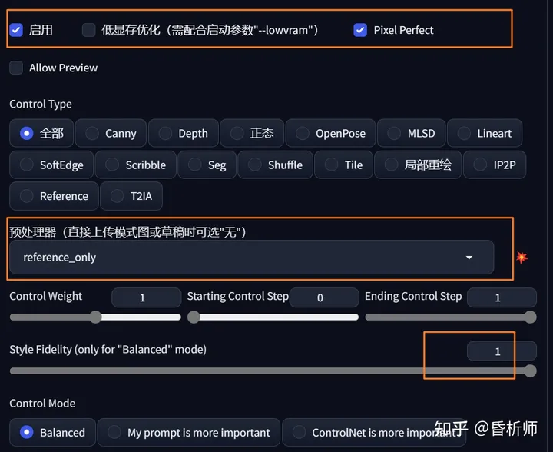
4.基于参考图的描述词生成图片即可,如需变换场景或细节例如发型等,可在正面提示词中调整,不会影响人脸继承。
出自:https://zhuanlan.zhihu.com/p/636670339?utm_id=0