随着Diffusion(扩散算法)的异军突起,AIGC(AI Generate Content)让曾经在脑海里的想象快速地成为具体的画面,每个人拥有自己的数字分身还是只存在电影或者小说里的桥段吗?虚拟偶像AYAYI、虚拟品牌代言人“花西子”、美妆数字达人柳叶熙、新华社AI合成主播-新小浩…技术新潮下数字人层出不穷。
但,普通人能有自己的数字分身吗?

▲ 虚拟数字人为了探究普通用户做数字人的可行性,淘宝设计内容生态小组专门成立了AIGC小组,挑选了一位素人美女同事作为样本对象,帮她做一个AI数字分身!

▲ 淘宝设计内容生态组选中的AI幸运儿为什么是素人美女呢?毕竟AI美女美得千篇一律像是流水线产物,而素人美女各有各的美丽。但如何捕捉真人的骨骼和个人特点,避免样本个例导致毫无置信度才是我们本次探究的关键!
那么结果如何呢?请看!

▲ 自己都有点分不清吧!美女同事惊呼妈妈见了都觉得像的程度!不仅高度还原,还能美得出乎意料!

▲ Amazing看来普通用户拥有数字分身大有可为。那么,分身后用户行为能发生哪些改变,又能带来什么样的体验呢?一起来看我们的创新体验探索吧~
01.有了数字分身竟然可以#开个脑洞🤯
数字分身,顾名思义包含用户的样貌、肤色肤质、身材特点等生理特质的虚拟人,也常被称为“数字孪生”、“数字人”等。

▲ 我的数字分身
未来可以不再退货?想象一下,如果用分身去购物,是不是可以不再退货了。这好像听起来有点难以想象。就像以前人们想不到,原来要跑大老远去买东西,现在动动手指就能完成。
线上购物给我们带来便利的同时,也会带来一定程度上的烦恼。货不对版、尺码过大过小、尝试新风格总觉得别扭…每个人买到心仪的宝贝的背后,都一定有无数次的换货、退货。
上述的现阶段购物方式体验痛点,可以通过与我有相似外观特征的数字分身解决。

▲ 分身试衣
突破单点的购物动线现有的用户购物动线,是以单品或单店的单点发散的。用户往往从某个商品卡片进入店铺,以此发现自己可能感兴趣的其他宝贝。但想搭配某个商品与另一个店铺的商品时,全凭不同的商品图或模特图进行脑补想象。
拥有数字分身后,能实现跨店多品搭配、现实场景化的选购方式。


▲ 超强代入感与真实感的购物体验不仅如此,结合AI的数据分析能力,未来的线上购物体验能做到不仅适体,更合心意。
做你所想,无限可能数字分身的潜力不仅仅在购物,还能提供无限可能的新奇体验,甚至给你新的生活方式的想象。
看到海边完美身材的自己,为了穿上曾经买了但美穿过的热辣短裙,下定决心坚持运动、吃干净又健康的食物,真实世界的自己也可以拥有更好的体魄。

▲ 海边辣妹“如果我是男的,我都想嫁给我自己”可以不再是一句玩笑话,嫁给性转后的我自己,婚纱照都拍好啦。(没想到男版的我酷似周杰伦?

▲ 我嫁给我自己如果这些还不够,你还可以旧时代的梦女郎、是异星球的不速之客、是拯救地球手持光剑的未来女战士。从过去到未来,你可以在任何时空、场景、甚至族群……

▲ 我的分身在平行宇宙无所不能这些原来只存在脑海里的想象能够变成具体的图像、视频,未来可以成为淘宝逛逛里有趣的内容被更多人看到。同时,你可能会发现跟自己相似的人,你们可能有相似的脸庞、身材、品味、爱好…在淘宝,不再是完成个人购物,而是链接更广阔世界的可能。
02.怎样才能拥有 # 一眼像,美三分的用户体验
这个解决方案的核心在于“一眼像”和“美三分”。如果“我”不像我,那再极致的体验都与我无关,“一眼像”是代入感的基础。同时,没有精致的布光和妆造,真实摄像头下的自己也很难有消费或创作欲望。因此,“像”并不是100%还原,在“一眼像”的基础上“美三分”是体验把控的重点。
对于普通用户而言,使用计算机图像学、类脑科学、语音合成、计算科学等聚合学科创设的具有多重人类特征的数字人实为无稽之谈。以StableDiffusion为例,创建仅外观特征相似的数字分身,在硬件设备、软件操作、模型训练及出图品质等各个方面都困难重重。那么,我们应该如何降低操作门槛,减少等待时长为普通用户构建数字分身呢?
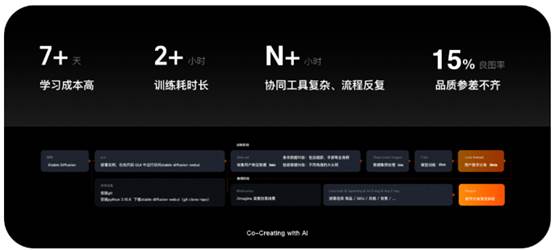
▲ 普通用户构建分身难点
工具选择选用当下最成熟火热的AI生成工具Midjourney、StableDiffusion,对比了二者的优劣势后,选用StableDiffusion作为主要的生图工具,其LoRA模型的训练能力能实现目标对象的多角度、高相似度效果。此外,Midjourney在生图难度低、速度快、质量高的特点可以用于场景构建。
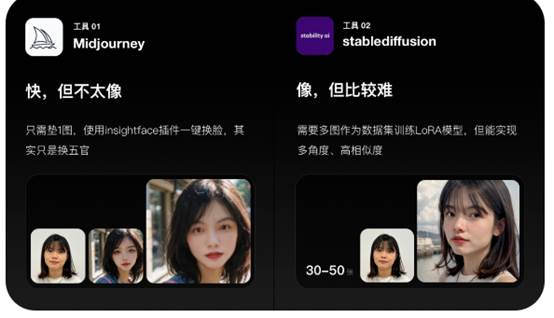
▲ 工具对比
训练流程首先,为了达成“像”的目标,我们把模型训练分为两步,一是人脸,再是身材。

▲分步训练其中,在模型训练上只需要两步。第一步,我们需要收集30-50张自恋大赏作为人脸模型训练的数据集,然后再到Stable Diffusion里注入代码进行模型训练。
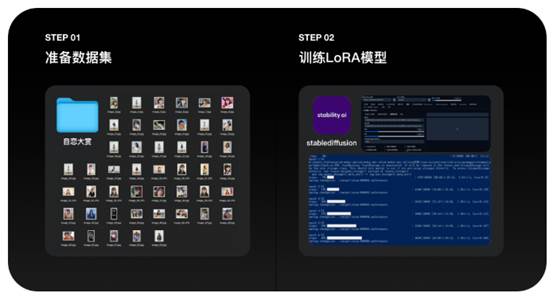
▲训练步骤这样好像又很简单吼。但…

▲ 有没有搞错啊实际上,LoRA模型的训练不仅需要足够多样化的数据集,还需要打乱数据集顺序并进行打标处理,避免AI连续学习相似图片导致过快拟合。然后,还需要进行LoRA模型最佳权重、泛化性等变量测试,选取兼顾真实感、相似度与美颜效果的参数组合。

▲ 变量测试经过大量的的测试,最终确定了高相似度的基础上再美三分的成像效果,以保证用户又像又美的愉悦感受。

▲ 渐变色使用规律
先“人”一步预置模型身材特征也是重要的外观特征,但身材数据采集是一大难题,受限于修身衣着与全身拍摄。
人脸特征是独一无二的,但身材特征是可以穷举的。我们把身材特征拆解为身高体重、三维数据与典型身材类型,通过用户数据微调与模型预置,就能在获得相似身材特征的同时减少用户操作成本与等待时长。
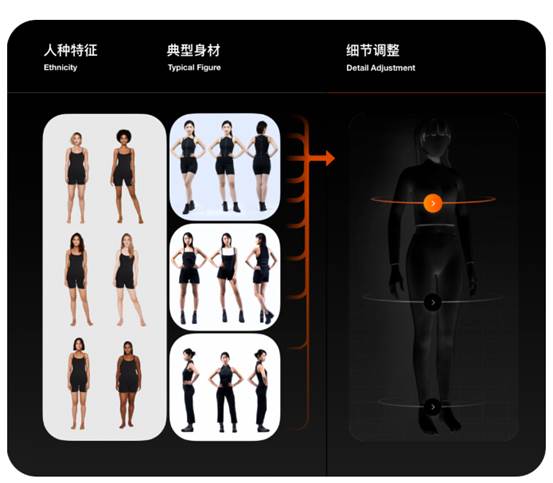
▲ 身材模型同时,我们还可以预制开心、惊喜、沮丧、悲伤等表情模型,赋予数字分身鲜活的情绪表达,以此展开有生命力的互动。

▲ 情绪表情
03.设计师的大锅是美感转译 # 我说的美和AI理解的美
目前,AIGC还处于“开盲盒”、“抽卡”阶段,设计师需要调教AI,将美学感受转译为AI能理解的技术语言,让AI也能做出符合大众审美认知的优质内容。
美感标准建立设计师还是AI的“训练师”,与AI的交互全靠prompt的构建。如何把设计师认为美的感觉描述给AI呢?在「合规」的基础上,确立「主体明确」、「合理自然」、「适度美化」的美感标准,构建及其对应的提示词库、嵌入式模型库,骨架模型库,以保证AI输出质量。

▲ 美感标准prompt不是万能的,AI能识别的提示词也是有限的。我们把相同画面感受的图片作为数据集,训练嵌入式模型Embedding(把数据向量化,可理解为prompt合集),帮助AI理解更好地理解美感风格。
例如,我们可以在Midjourney中生成法式庭院的主题场景作为环境描述的数据集,再在StableDiffusion中训练相应的Embedding,以此控制场景的生成效果。

▲ 嵌入式模型库
为AI减负当前的商品模特图中,有大量夸张动作、复杂场景设置以营造画面的生活感、氛围感。但复杂的人景关系、物体遮挡会极大提高生图难度。现阶段我们直接去掉这些画面构成类型,以减低劣图、破图出现造成的用户负向感受。

▲避免复杂画面构成类型同时,将人体姿势归总为站姿、坐姿两大类,将姿态自然的姿势用 3Dopenpose生成骨架模型,结合ControlNet插件控制人物姿势。
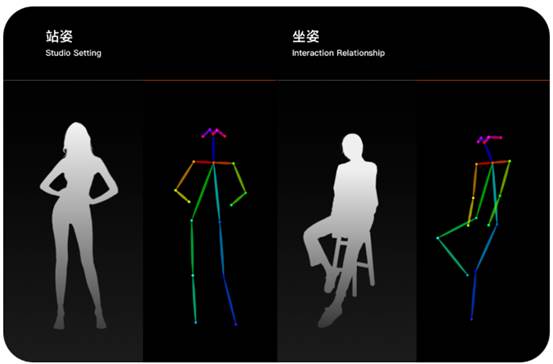
▲ 3D openpose骨架模型将画面构成分为人体、背景两层后,就能更加明确主体,从而生成高质量图片。

▲ 画面构成
🤤
is that possible…
那是不是可以…
可以预见不久后,数字分身不仅可以还原外观,还能在行为表达、思维决策上也更“像样”。而基于MR(空间交互)、LLM(自然语言交互)等人工智能技术的发展,又会有全新的交互方式和产品形态,崭新的时代即将到来。
随着技术的革新,梦想照进现实,是不是有一天,我的分身可以帮我画稿子…

▲ 其实已经能画啦数字分身不算一个新颖的概念,我们在太多电影桥段里看过类似的场景,同时我们也深知背后还有着巨大的实现成本和数据安全合规等卡点,但充足的设计储备会带着我们不断向前。
对于设计师而言,方案构建的初衷绝不是为了追赶技术热点,而是思考如何巧妙地应用技术并解决用户问题,并不断推进用户体验的提升,那些原来不可能的事发生,让理想的生活简单又美好。