简介: 什么是ReAct框架关于什么是langchain,可以参考:https://ata.alibaba-inc.com/articles/266839?spm=ata.23639420.0.0.1dea7536uD7yhh在使用langchain的过程中,大模型给人留下最深刻的印象无疑是Agent功能。大模型会自己分析问题,选择合适的工具,最终解决问题。这个功能背后的原理就是来自ReAct框架。ReA
什么是ReAct框架
关于什么是langchain,可以参考:
https://ata.alibaba-inc.com/articles/266839?spm=ata.23639420.0.0.1dea7536uD7yhh
在使用langchain的过程中,大模型给人留下最深刻的印象无疑是Agent功能。大模型会自己分析问题,选择合适的工具,最终解决问题。这个功能背后的原理就是来自ReAct框架。
ReAct是Reasoning and Acting(也有一说是Reason Act)缩写,意思是LLM可以根据逻辑推理(Reason),构建完整系列行动(Act),从而达成期望目标。LLM灵感来源是人类行为和推理之间的协同关系。人类根据这种协同关系学习新知识,做出决策,然后执行。LLM模型在逻辑推理上有着非常优秀的表现,因此有理由相信LLM模型也可以像人类一样进行逻辑推理,学习知识,做出决策,并执行。在实际使用中,LLM会发生幻觉和错误判断的情况。这是因为LLM在训练的时候接触到的知识有限。因此对超出训练过程中使用的数据进行逻辑分析时,LLM就会开始不懂装懂地编造一些理由。因此对于解决这个问题最好的办法是,可以保证LLM模型在做出分析决策时,必须将应该有的知识提供给LLM。
ReAct方式的作用就是协调LLM模型和外部的信息获取,与其他功能交互。如果说LLM模型是大脑,那ReAct框架就是这个大脑的手脚和五官。同时具备帮助LLM模型获取信息、输出内容与执行决策的能力。对于一个指定的任务目标,ReAct框架会自动补齐LLM应该具备的知识和相关信息,然后再让LLM模型做出决策,并执行LLM的决策。
它是如何运作的

图片来源:https://arxiv.org/abs/2210.03629
一个ReAct流程里,关键是三个概念:
Thought:由LLM模型生成,是LLM产生行为和依据。可以根据LLM的思考,来衡量他要采取的行为是否合理。这是一个可用来判断本次决策是否合理的关键依据。相较于人类,thought的存在可以让LLM的决策变得更加有可解释性和可信度。
Act:Act是指LLM判断本次需要执行的具体行为。Act一般由两部分组成:行为和对象。用编程的说法就是API名称和对应的入参。LLM模型最大的优势是,可以根据Thought的判断,选择需要使用的API并生成需要填入API的参数。从而保证了ReAct框架在执行层面的可行性。
Obs:LLM框架对于外界输入的获取。它就像LLM的五官,将外界的反馈信息同步给LLM模型,协助LLM模型进一步的做分析或者决策。
一个完整的ReAct的行为,包涵以下几个流程:
1.输入目标:任务的起点。可以是用户的手动输入,也可以是依靠触发器(比如系统故障报警)。
2.LOOP:LLM模型开始分析问题需要的步骤(Thought),按步骤执行Act,根据观察到的信息(Obs),循环执行这个过程。直到判断任务目标达成。
3.Finish:任务最终执行成功,返回最终结果。
一个可以自己尝试ReAct过程的Prompt的例子:
You are an assistant, please fully understand the user's question, choose the appropriate tool, and help the user solve the problem step by step.
### CONSTRAINTS ####
1. The tool selected must be one of the tools in the tool list.
2. When unable to find the input for the tool, please adjust immediately and use the AskHumanHelpTool to ask the user for additional parameters.
3. When you believe that you have the final answer and can respond to the user, please use the TaskCompleteTool.
5. You must response in Chinese;
### Tool List ###
[
Search: 如果需要搜索请用它.paramDescription : [{"name": "searchKey", "description": "搜索参数","type":"String"}]
AskHumanHelpTool: 如果需要人类帮助,请使用它。paramDescription : [{"name": "question", "description": "问题","type":"String"}]
TaskCompleteTool:如果你认为你已经有了最终答案,请使用它。paramDescription : [{"name": "answer", "description": "答案","type":"String"}]
]
You should only respond in JSON format as described below
### RESPONSE FORMAT ###
{
{"thought": "为什么选择这个工具的思考","tool_names": "工具名","args_list": {“工具名1”:{"参数名1": "参数值1","参数名2": "参数值2"}}}}
Make sure that the response content you return is all in JSON format and does not contain any extra content.
把它复制粘贴到ChatGPT中,就可以感受一下最初级的ReAct交互的体验。读者自己充当一个ReAct框架,去执行Act和Obs过程。
先说ReAct的缺点
毫无疑问,让LLM模型进行决策不是完美无缺的。目前有几个显而易见的缺点是工程上必须要考虑的。
1、LLM模型的通病
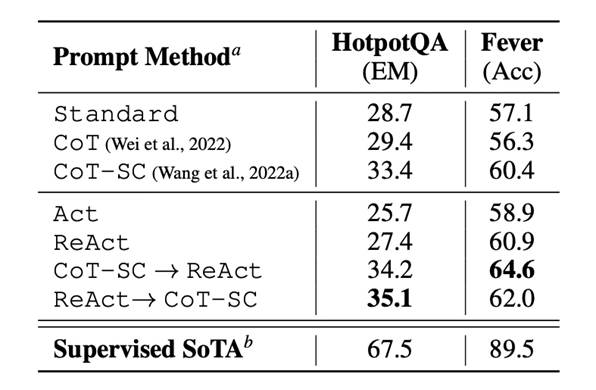
图1

图2
数据来源:https://arxiv.org/abs/2210.03629
注:表中CoT一栏是指模型只进行链式思考,不从外部获取必要信息。本文不对ReAct和CoT的对比做分析。想了解的可以自行查看论文。
LLM模型最大的问题是产出内容不稳定。这种不稳定不仅仅是内容存在波动,也体现在他对复杂问题的分析,解决上存在一定的波动。
上图论文中,采用PaLM-540B模型进行的测试。图1中可以看到采用ReAct模式时,LLM模型在知识密集型推理任务如问答 (HotPotQA)上表现存在不足,而在事实验证(Fever)上有着更好的表现。这个主要原因是采用ReAct方式会约束LLM模型制定推理方面的灵活性。LLM擅长逻辑推理,但过多非信息性的搜索有可能会阻碍模型推理,导致难以恢复推理流程。
图2中的数据也可以看到,即使采用ReAct模型,也会有幻觉、不知道改搜索什么内容,错误归因等现象发生。
LLM的表现来看,更像一个人类。泛用性很强,可以通过自己思考去解决很多问题,但也会因为自身知识,能力上的缺陷无法做到稳定输出。但LLM跟人比,会显得更加盲目自信,对于不了解不理解的问题也会编造一些内容(幻觉)。
论文中采用的还是PaLM-540B模型,整体表现是明显差于GPT4.0和更新的模型。我们有理由相信未来的模型可以把幻觉,不稳定输出等问题发生概率降低到最低。但现阶段,如果应用LLM模型的时候必须要考虑这个问题。
2、成本
成本是目前使用LLM模型无法绕过的问题。每一个经常使用LLM模型的开发者,都会觉得自己仿佛回到了20年前开发单片机一样,提交给LLM的内容里每一个字节都需要思考。按照输入和输出token数量收费方式,让开发者必须斟酌内容和内容带来的价值能否cover住成本。
而采用ReAct方式,开发者是无法控制输入内容的。因为在任务提交给LLM后,LLM对任务的拆解、循环次数是不可控的。因此存在一个可能性,过于复杂的任务导致Token过量消耗。一个复杂任务一晚上跑掉一栋别墅的钱也不是玩笑话。
3、响应时间
比起大部分API接口毫秒级的响应,LLM响应时间是秒级以上。以ChatGPT的API为例,普通一次Completion接口,响应时间都要10秒以上。如果是复杂的任务,达到20秒以上也是可能的。当然,这里不确定是不是OpenAI本身工程能力有限导致的,还是LLM本身就需要这么长的时间。
在ReAct模式下,这个时间变得更加不可控。因为无法确定需要拆分多少步骤,需要访问多少次LLM模型。因此在在秒级接口响应的背景下,做成同步接口显然是不合适的,需要采用异步的方式。而异步方式,又会影响用户体验,对应用场景的选择又造成了限制。
为什么需要ReAct框架
通过前面描述,应该看得出来ReAct本身是使用LLM模型的一种方式。但在往工程化上应用的时候存在各种问题。因此,基于这些工程上的问题,我在思考除去等待LLM模型自身性能提升外,我们是否可以通过一些工程化的手段去规避或者解决其中一些问题。
Langchain、AutoGPT or GPT PlugIn or ?
目前开源环境下已经有Langchain,AutoGPT这些采用ReAct方式的框架。Openai也通过Plugin的方式提供出一些基于ReAct方式的应用。
前者是基于Python代码写的ReAct框架。毫无疑问在接入Java应用中会存在很多问题。不论是定制Agent可扩展的Tool的能力,还是运维部署都会比较麻烦。当应用出问题时,debug更加困难。高兴的是集团已经有兄弟开始逐步实现Java版本的langchain:https://ata.alibaba-inc.com/articles/267337?spm=ata.23639420.0.0.1dea7536qqQ99i#SB_szwZT
但是,我认为langchain只是ReAct框架的第一步。分析Langchain的代码就可以看出,它不是一个以ReAct方式为核心而设计的模型。在上述提到的工程化问题里,并没有很好的解决。所以在我们做Java版本的Langchain的时候,设计的核心应该是ReAct方式。利用Java强大的工程能力,赋能给更多的Java应用。我对ReAct框架的期望是可以构建像Spring一样的生态,让更多不懂算法的Java工程师,也能让自己的应用变得更加智能。
GPT Plugin是采用的ReAct方式,极大的增强了ChatGPT的能力。但它注定是不够灵活,受限于ChatGPT的使用场景。当我的应用需要独立于ChatGPT以外的使用场景时,就很难使用。这里可以认为它是对LLM模型能力的补充,带并不会取代ReAct框架在工程中的使用。但Plugin的优势是集成在LLM模型内部,可以大幅降低ReAct交互次数。从而带来成本降低,响应时间提升的优势。
ReAct框架需要哪些能力
1.稳定的输入和输出
前文所说,现阶段LLM模型的产出是不稳定的。通过对Prompt模板的不断调优,SDK参数调整,可以将LLM产出的内容尽可能的稳定产出。这里的稳定是指对输出内容满足开发者的期望。对于需要LLM模型创作的场景,依然需要支持它可以自由不设限的,多样化的创作。
对于LLM错误的产出,可以及时发现并提示开发者或者重新向LLM模型查询,获取更好更优质的回答。
2.成本优化和监控
构建向量缓存,对于有通用回复的内容可以通过缓存的形式减少对LLM交互的次数。
优化Prompt模板,减少无味的Token消耗
对于已有Token的消耗需要有可视化的监控。一方面可以洞察消耗情况,另一方面也可以做到成本预警。可以对还未执行的任务,进行成本预估。
3.优化LLM模型响应时间
减少LLM交互次数,可以通过MapReduce的方式提高并发执行交互的能力。
4.本地知识库的导入和动态embedding
对于LLM决策需要的额外了解的信息,可以动态的嵌入到每一次Prompt内容中。从而提升LLM模型决策的准确性。
5.能力快速接入和可拓展
对于ReAct应用,LLM模型决策是一方面,更主要的是LLM决策后,能做啥。这里需要有一个清晰的能力定义与描述以及快速接入能力。可以方便LLM模型理解能力并在需要的时候使用它。LLM框架能评估每个能力的描述,方便开发者更好的将新能力或者已有的能力接入LLM模型中。
6.And more……
目前还是我在写ReAct框架中思考需要解决的问题,后续还有更多的问题需要解决会逐步补充进来。
后续
ReAct框架可以让现有应用得到一次智能化的进化的机会。以前需要人工编排服务调用链路会成为历史。LLM可以让我们的应用开发成本大幅下降,也可以让软件设计模式得到全新的变化。也许未来有一天,什么设计模式,什么DDD都会成为历史。写好一个个函数,剩下的交给大模型吧!
出自:https://developer.aliyun.com/article/1241363