AI绘画普及后,越来越多的创作者开始用各种AI工具,来绘制自己想象中的画面和场景。
无论是免费开源的stable diffsion,还是付费的midjourney,都能高度还原出你的想象力。
然而,有一个很大的问题困扰着很多爱好者:我不知道怎么写提示词怎么办?
有时候,看到一张很棒的照片,想仿照画一张,但苦于才思枯竭,无法高效完整的写出提示词。
怎么办?
推荐一个“反推”插件,叫 Wd14 Tagger
。
所谓反推,就是能够根据图片,倒推出这张图片的提示词。基本原理是AI来识别图片里的关键词,比如长头发、微笑、海边等等。
AI如何识别的呢?
靠的是模型,Wd14 Tagger依赖的deepdanbooru模型。
deepdanbooru的模型部署在本地,可以识别图像中的物体,用文字特征描述,一个一个的单词。能把图片中的每一个物体“读”出来。
本质上是把人工打标的过程逆操作,AI经过训练,逐渐“学”会了人类的打标过程,就可以利用大模型给图片打标。
1、安装方式:
在扩展--从网址安装,输入
https://gitcode.net/ranting8323/stable-diffusion-webui-wd14-tagger
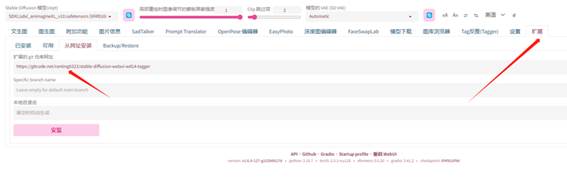
安装完成后,重启启动器。
重启过程中会下载模型,第一次使用比较慢,请耐心等待。
2、使用方法
点击WD14(反推),上传要获取提示词的图片。
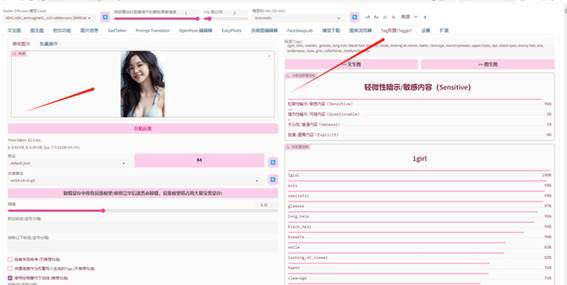
插件会开始反推,并将反推结果显示在tags,反推结果可以直接传送回文生图、图生图。

以本图为例,反推插件“读”出来的结果是:
1girl, solo, realistic, glasses, long
hair, black hair, breasts, smile, looking at viewer, teeth, cleavage, round
eyewear, upper body, lips, black eyes, messy hair, bra, underwear, nose, grin,
collarbone, medium breasts
用这组提示词跑了一下文生图,发现已经很接近了。

这说明使用AI读取提示词还是很靠谱的。
如果结合图生图,效果会更加接近(重绘幅度0.7)。

WebUI升级支持SDXL后,很长一段时间,WD14插件启动就报错,直到WebUI更新到1.6版本,才能正常使用。
3、其他用途
除了作为反推插件,Wd14 Tagger还被作为训练模型的必备工具,替代人工打标,减轻工作量,实现全面自动化“炼丹”。
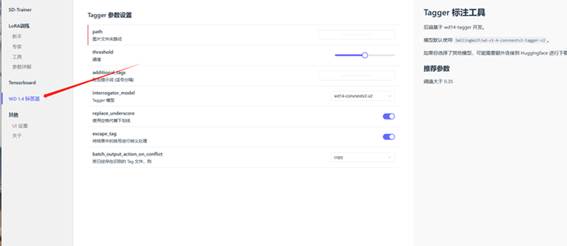
比如秋叶开发的模型训练器,就使用该插件自动打标。
出自:https://mp.weixin.qq.com/s/GW26DJzPCsMVXiHSwIUuaw