
当下大语言模型最重要能力就是是自然语言理解和生成。那么我么首先想到的就是让 AI 帮我们生成知识节点的摘要。
还记得我们的知识图谱节点上有一个「描述」字段吧,这个是为了记录这个知识结点的介绍信息。 当然总结摘要介绍这件事儿放在之前还是很繁琐的,需要一个一个的总结还要斟酌用词,现在我们尝试使用 AI 帮助我们进行知识摘要。
知识节点的介绍生成有两种方式,一种是利用 LLM 的内部知识库,另外一种是外挂知识,利用 LLM 的总结能力。
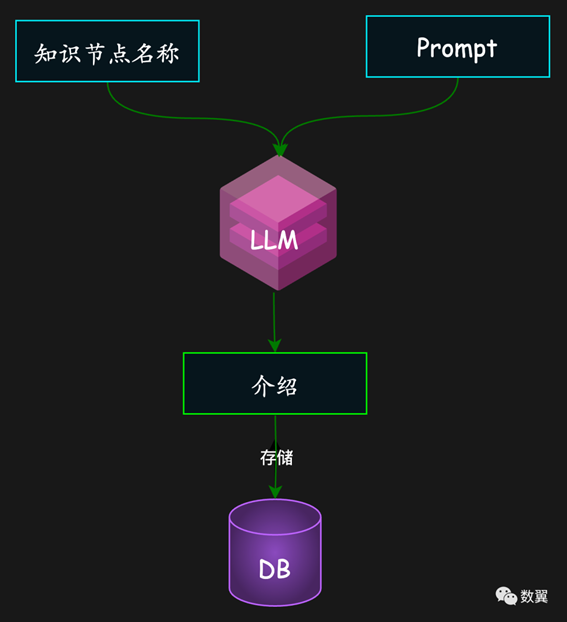 AIGC 直接生成介绍
AIGC 直接生成介绍
利用 AI 内置的知识生成介绍方便快捷,但是有可能新知识 LLM 还没有学到,这个时候 LLM 可能出现幻觉,甚至胡说八道。
利用 LLM 知识生成摘要的局限性大多数情况下,LLM 应用都是使用 LLM 本身的知识,针对个人知识库也一样。不过我的个人知识图谱的
定位偏向于专业知识,有很多可能是当月新更新的知识,为了杜绝 LLM 的幻觉和胡说八道的问题,暂时放弃 LLM 内部知识。
选择第二种方案,自动获取节点介绍然后让 LLM 总结,流程如下:
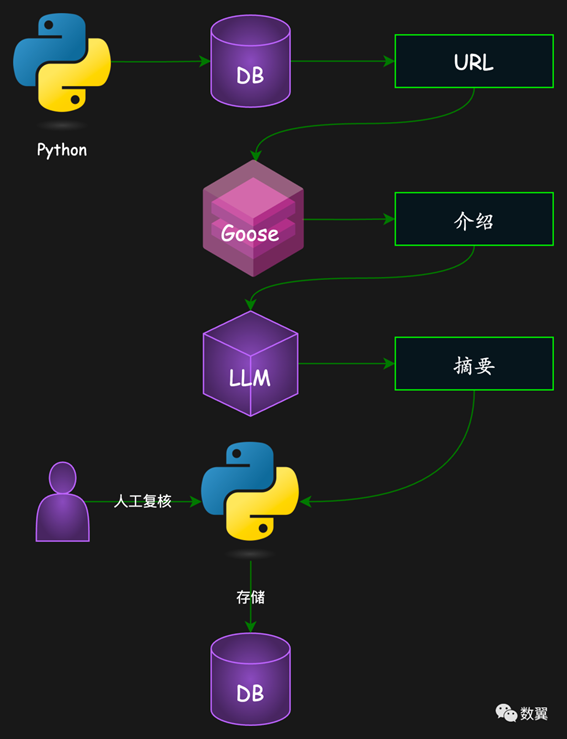 AIGC 自动生成知识节点摘要流程
AIGC 自动生成知识节点摘要流程
知识节点摘要介绍实现
由于我们维护了知识节点的主页,所以可以很方便的通过程序获取主页上的介绍。
这里用到了 Goose 这个 Python 文章解析的库,他也可以解析主页的描述,如果网站的主页描述文案不正确,那么最终生成的摘要也会有所不准确。
比如 Kubernetes 这个实体,我们之前维护的主页是 https://kubernetes.io,那么获取到介绍文本如下:
Kubernetes, also known as K8s, is an open-source system for automating deployment,
scaling, and management of containerized applications.
It groups containers that make up an application into logical units
for easy management and discovery. Kubernetes builds upon 15 years of experience
of running production workloads at Google, combined
with best-of-breed ideas and practices from the community.
Planet Scale Designed on the same principles that
allow Google to run billions of containers a week,
Kubernetes can scale without increasing your operations team.
先不用关心是英文的还是中文的,后面让 AI 一并处理。
页面解析页面解析除了 Goose,还有很多工具可以选择:requests, lxml, BeautifulSoup, Scrapy。相对后者来说,Goose 是一个很小众的工具。
 取
取
AIGC 的老司机们或者看过我之前文章的朋友对知识摘要肯定不陌生。我们编写提示同时进行摘要和关键词的生成。
摘要任务摘要任务是一个很常见的人工智能任务,几乎所有的 LLM 模型可以实现,比如国内的 ChatGLM ,有很多的开源产品基于此做了知识摘要等功能的产品。
还是先编写提示词:
template = '''
帮我给下面一段话做一下中文总结,并提取一下关键词。
按照如下 Json 格式返回。
```
{
"abstract": "<摘要总结>",
"tags": ["关键词1", "关键词2"]
}
```
内容:
%s
'''
编写摘要函数。为了简单起见我们使用 OpenAI 的提示模板和接口:
def abstract_knowledge(url: str):
description = Goose().extract(url=url).meta_description
completion = openai.Completion.create(model="gpt-3.5-turbo", prompt=(template % description))
result = json.loads(completion.choices[0].text)
return result
拿上面的提示词,测试了下,效果还挺好:
{
"abstract": "Kubernetes是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。
它将构成应用程序的容器分组成逻辑单元,以便于管理和发现。
Kubernetes基于Google在运行生产工作负载方面的15年经验,
并结合了社区中最佳的想法和实践。
它以与Google每周运行数十亿个容器相同的原则设计,
可以在不增加运维团队的情况下实现规模化扩展。",
"tags": ["Kubernetes", "K8s", "开源系统", "自动化部署",
"容器化应用程序", "逻辑单元", "管理", "发现", "Google",
"生产工作负载", "社区", "最佳想法", "最佳实践", "规模化扩展"]
}
生成的关键词可以直接作为我们知识图谱节点的关键词。

上面 ChatGPT 自动总结的关键词有点多,有两个方法进行优化。
方法一:直接在提示模板中限定关键词个数,并对提示语进行更严格的约定。比如:并提取一下关键词,个数限制在五个以内,或者提取5个关键词。
这样我们就可以得到指定个数的标签关键词:
{
"abstract": "Kubernetes是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。它将构成应用程序的容器分组成逻辑单元,以便于管理和发现。Kubernetes基于Google在运行生产工作负载方面的15年经验,并结合了社区中最佳的想法和实践。它以与Google每周运行数十亿个容器相同的原则设计,可以在不增加运维团队的情况下实现规模化扩展。",
"tags": ["Kubernetes", "K8s", "开源系统", "自动化部署", "容器化应用程序"]
}
方法二:在提示模板中维护一个关键词列表。比如:「并提取一下相关标签,关键词范围:管理、工具、开源、部署、程序、运营、公司、框架、基础设施。」
调整提示模板如下:
template = '''
我要构建关于 %s 的知识图谱,下面一段内容是关于 %s 的介绍,请根据介绍做一下中文总结,
并提取一下 %s 相关的标签,标签范围:管理、工具、开源、部署、程序、运营、公司、框架、基础设施。。
按照如下 Json 格式返回。
```
{
"abstract": "<摘要总结>",
"tags": ["关键词1", "关键词2"]
}
```
内容:
%s
'''
得到的标签结果就在我们的限定之内了:
{
"abstract": "Kubernetes是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。它将构成应用程序的容器分组成逻辑单元,以便于管理和发现。Kubernetes基于Google在运行生产工作负载方面的15年经验,并结合了社区中最佳的想法和实践。它以与Google每周运行数十亿个容器相同的原则设计,可以在不增加运维团队的情况下实现规模化扩展。",
"tags": [
"管理",
"工具",
"开源",
"部署",
"框架"
]
}
最后增加一个接口供程序调用皆可:
class ParseBody:
name: str
url: str
@router.post("/parse_node/")
def list(body):
return abstract_knowledge(body.name, body.url)
拓展知
告诉我10个和 Kubernetes 相关的开源技术, 使用如下 Json 格式回答:
```
[
{"name":"<技术名称>", "description": "<description>"}
]
```
[
{"name": "Docker", "description": "Docker是一种开源的容器化平台,与Kubernetes紧密集成,用于打包、分发和运行应用程序。"},
{"name": "Prometheus", "description": "Prometheus是一个开源的监控和警报系统,可与Kubernetes集成,用于收集、存储和查询应用程序的度量数据。"},
{"name": "Grafana", "description": "Grafana是一个开源的数据可视化工具,可与Kubernetes集成,用于创建仪表板和图表展示应用程序的监控数据。"},
{"name": "Helm", "description": "Helm是一个开源的Kubernetes包管理工具,用于简化应用程序的部署和管理,提供了模板化和版本控制的功能。"},
{"name": "Istio", "description": "Istio是一个开源的服务网格平台,与Kubernetes集成,用于管理、保护和监控微服务架构中的通信流量。"},
{"name": "Fluentd", "description": "Fluentd是一个开源的日志收集和传输工具,可与Kubernetes集成,用于收集、聚合和传输容器和应用程序的日志数据。"},
{"name": "Jaeger", "description": "Jaeger是一个开源的分布式追踪系统,与Kubernetes集成,用于跟踪和分析应用程序中的请求流程和性能问题。"},
{"name": "Knative", "description": "Knative是一个开源的服务器less平台,构建在Kubernetes之上,用于简化构建、部署和管理无服务器应用程序。"},
{"name": "Harbor", "description": "Harbor是一个开源的容器镜像仓库,与Kubernetes集成,用于存储、分发和管理容器镜像。"},
{"name": "Rook", "description": "Rook是一个开源的存储编排器,与Kubernetes集成,用于在Kubernetes集群中提供块存储、文件共享和对象存储等功能。"}
]
你还可以让 AI 帮你补充除了描述之外的其他的字段,比如主页网址、Github地址等。
告诉我10个和 Kubernetes 相关的开源技术, 使用如下 Json 格式回答:
```
[
{"name":"<技术名称>", "description": "<description>","url":"<home site url>","github":"<github url>"}
]
```
[
{
"name": "Docker",
"description": "Docker是一种开源的容器化平台,与Kubernetes紧密集成,用于打包、分发和运行应用程序。",
"url": "https://www.docker.com/",
"github": "https://github.com/docker"
},
{
"name": "Prometheus",
"description": "Prometheus是一个开源的监控和警报系统,可与Kubernetes集成,用于收集、存储和查询应用程序的度量数据。",
"url": "https://prometheus.io/",
"github": "https://github.com/prometheus"
},
{
"name": "Grafana",
"description": "Grafana是一个开源的数据可视化工具,可与Kubernetes集成,用于创建仪表板和图表展示应用程序的监控数据。",
"url": "https://grafana.com/",
"github": "https://github.com/grafana"
},
{
"name": "Helm",
"description": "Helm是一个开源的Kubernetes包管理工具,用于简化应用程序的部署和管理,提供了模板化和版本控制的功能。",
"url": "https://helm.sh/",
"github": "https://github.com/helm/helm"
},
...
]
AI 直
请帮我生成一分 Kubennetes 相关技术的知识图谱数据,使用如下格式回答:
```
{
"nodes": [
{"id": "Kubernetes", "name": "Kubernetes", "group": "系统"},
],
"links": [
{"source": "Kubernetes", "target": "Docker"},
]
}
```
{
"nodes": [
{"id": "Kubernetes", "name": "Kubernetes", "group": "系统"},
{"id": "Docker", "name": "Docker", "group": "容器化平台"},
{"id": "Prometheus", "name": "Prometheus", "group": "监控和警报系统"},
{"id": "Grafana", "name": "Grafana", "group": "数据可视化工具"},
{"id": "Helm", "name": "Helm", "group": "包管理工具"},
{"id": "Istio", "name": "Istio", "group": "服务网格平台"},
{"id": "Fluentd", "name": "Fluentd", "group": "日志收集和传输工具"},
{"id": "Jaeger", "name": "Jaeger", "group": "分布式追踪系统"},
{"id": "Knative", "name": "Knative", "group": "服务器less平台"},
{"id": "Harbor", "name": "Harbor", "group": "容器镜像仓库"},
{"id": "Rook", "name": "Rook", "group": "存储编排器"}
],
"links": [
{"source": "Kubernetes", "target": "Docker"},
{"source": "Kubernetes", "target": "Prometheus"},
{"source": "Kubernetes", "target": "Grafana"},
{"source": "Kubernetes", "target": "Helm"},
{"source": "Kubernetes", "target": "Istio"},
{"source": "Kubernetes", "target": "Fluentd"},
{"source": "Kubernetes", "target": "Jaeger"},
{"source": "Kubernetes", "target": "Knative"},
{"source": "Kubernetes", "target": "Harbor"},
{"source": "Kubernetes", "target": "Rook"}
]
}
经过几次迭代,可以得到下面的图谱:
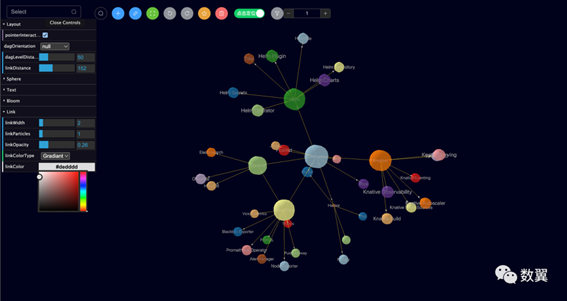 完全利用AI 生成的图谱
完全利用AI 生成的图谱
关于 AIGC 生成的知识图谱AIGC 在生成通用知识图谱上很有用,不过我们构建个人知识图谱主要以个人知识为纲要,AIGC 生成的话对我们来说并不是特别有用。
上面介绍了几种 AIGC 在知识图谱构建方面的几种应用方式,但我们太过依赖 AI 的话,就失去了构建知识图谱,甚至是使用 AI 的初衷。
从知识的角度,AI 会的和其他人会的并无差异,所以我们更多的时候只有充实自己的知识库,才能在新的浪潮中从容应对。
出自:https://mp.weixin.qq.com/s/IjPmQKtMtAJafqwVsxtiUQ