AnimateDiff 生成补间动画



测试了下工作流,输入是2张图片,一张作为起点,另一张作为终点。
主要的实现原理:
1 通过controlnet的tile来处理
2 设置timestep_keyframe控制每一帧controlnet的权重
3 controlnet权重弱的部分,animatediff的影响变强
# ControlNet Tile 可以做什么?
借助 Controlnet Tile,你可以:
修正图像细节
纹理变化
图像放大
- 生成图像,再使用Tile修正细节

- 修改皮肤纹理

- 图像翻译

# 什么是 AnimateDiff ?
AnimateDiff 该论文提出了一个实用的框架,用于为现有的文本生成图像模型添加动画效果。该框架通过插入一个新的运动模块(经过训练学习了视频片段的动作知识)到已经冻结的文本生成图像模型中。所有基础模型都能够轻松地生成各种各样的个性化动画图像。
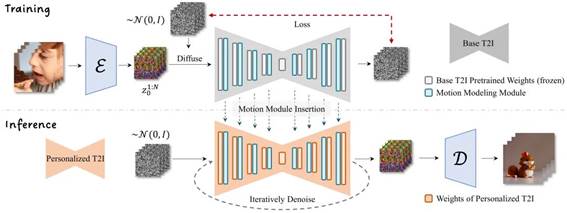
基本的原理是什么呢?官方的解释有点深奥,我们换一种方式理解下此项技术:
Shadow是一位小朋友,他喜欢玩积木。有时候,他用积木搭建了一个静态的建筑,但是觉得有些无聊,想让它动起来。
于是,他想到了一个好方法,就是给他的积木加上一个小机器人,让它们动起来。
这个小机器人可以学习如何动,然后把学到的动作教给积木。
这样,Shadow所有搭建好的建筑都可以动起来了,而且不需要每次都重新学习一遍。
就像小朋友们学会了一个游戏规则,就可以用它来玩很多不同的游戏一样。
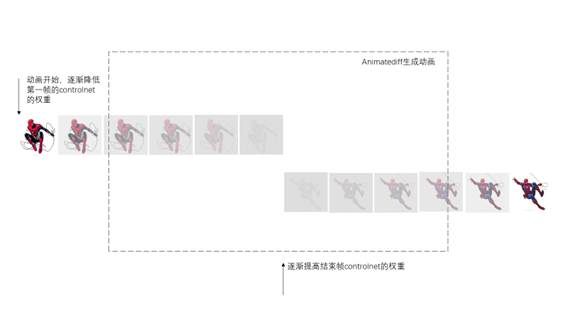
# 动画原理
比如要实现以下视频的效果,我们只需要准备2张图片,调整整个动画每一帧上controlnet的权重即可。
hi我是Mixlab的shadow
,赞12
出自:https://mp.weixin.qq.com/s/aRKVv3lKQGGFANhxDzQU_A