有些东西就很玄,当我去做一件事情的时候,就立马会发生另外一件事情。
比如刚写了Baichua2,然后发现阿里的Qwen也更新了!
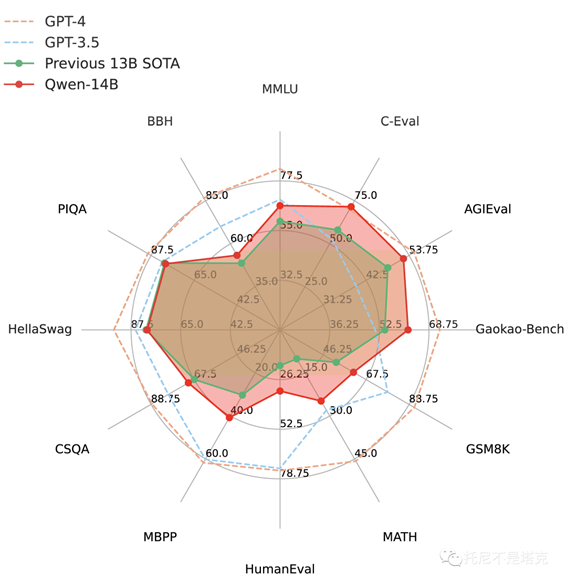
Qwen第一版刚出来的时候,我就玩过。今天来尝试一下14B(140亿参数),普通显卡,纯本地运行!
模型简介
通义千问-14B(Qwen-14B) 是阿里云研发的通义千问大模型系列的140亿参数规模的模型。Qwen-14B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-14B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-14B-Chat。本仓库为Qwen-14B-Chat的仓库。
7B大概在一个月前发布,这次发布了14B版本。单从测评数据来看,要比上次讲的Baichuan2还要强不少。
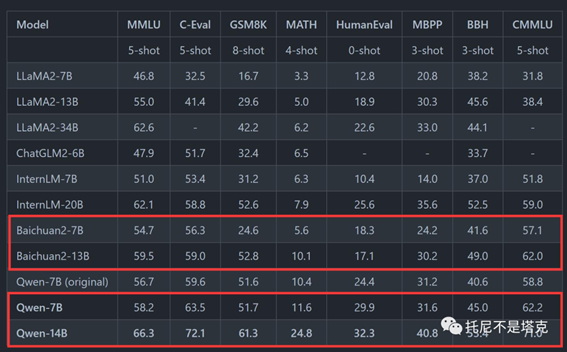
通义千问的开源也做得非常棒。(大厂出手,小厂颤抖啊~~)
它在两个平台大发布了模型,一个是自家的魔搭(ModelScope)平台,可以快速的在阿里云上跑起来。另外一个是在huggingface,给国际玩家。
另外在Github上也有非常完善的文档。文档还提供了中,英,日的版本。
文档提供了:
快速上手Qwen-Chat教程,玩转大模型推理.
量化模型相关细节,包括用法、显存占用、推理性能等。这部分还提供了和非量化模型的对比。
微调的教程,帮你实现全参数微调、LoRA以及Q-LoRA。
搭建Demo的方法,包括WebUI和CLI Demo
更多关于Qwen在工具调用、Code Interpreter、Agent方面的内容
长序列理解能力及评测
使用协议
模型类型
目前发布的模型有7B和14B包括基础模型,聊天模型,量化模型。还有VL的模型。
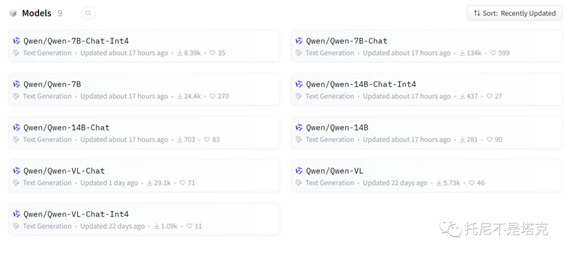
前面的都是语言模型,VL是大规模视觉语言模型。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。感觉这个也挺好玩,有空玩一玩。
因为我的配置有限,今天主要是完7b-int4 和14b-int4。
实测在3060 12G上可以运行,并流畅对话。
运行方法
上面说到Qwen在两个平台发布了模型。所以他们的配置方式也有些不一样。一个是使用modelscope
,一种直接使用transformers!
我本来以为他们是完全一样的,谁便用就好了,但是实际上还有一些不一样。
modelscope默认会加载魔搭上的模型,这个好处是不用魔法也可以快速下载。尤其是我所在地理位置,简直就是物理加速啊,带宽跑满,还得溢出一些。
魔搭的安装可以稍微参考一下我第一次安装Qwen的文章。
transformers就会去huggingface上加载模型,很不幸,我发现HF也已经被墙了。如果你用魔法的话,得高速魔法,费不少流量。
由于Github上提供的命令行cli_demo和网页web_demo例子都是后者,我就按后者讲了。
基础环境,基础软件安装我就不细讲了,参考之前的文章。
下面就直接上命令!
1.创建虚拟环境
conda create -n qwen python=3.10conda activate qwen
2.克隆代码
git clone https://github.com/QwenLM/Qwen.git
3.安装依赖
cd qwenpip install -r requirements.txt
4.安装量化依赖
pip install auto-gptq optimum
这一步其实还有一个隐藏步骤,上一篇中讲到了。
5.修改环境变量
SET TRANSFORMERS_CACHE=%ROOT%\models
这是我的必改选项,否则会撑爆你的C盘。
6.修改源代码
DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat-Int4'
或者
DEFAULT_CKPT_PATH = 'Qwen/Qwen-14B-Chat-Int4'
不管是cli还是web,打开源代码文件,只要修改这一行就可以了。配置低的修改成7B,配置高点的修改成14B,配置更强可以把后面的-Int4去掉。
7.运行demo
官方准备了两个demo,一个是命令行的一个是网页版的。网页版运行起来几乎和官方展示的一模一样。
命令行版
·
python cli_demo.py
启动,会有一个小进度条,加载检测点切片。
加载完成后就可以聊天了。
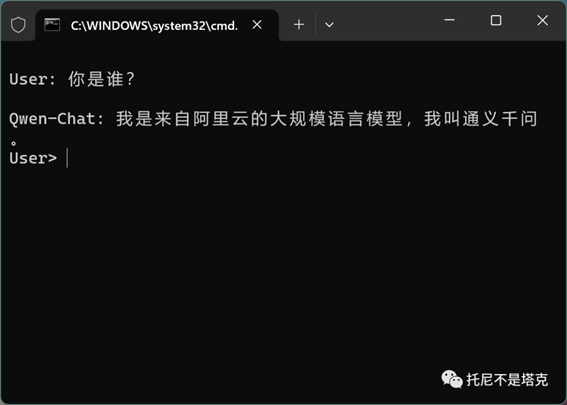
这个命令行demo没有百川的好,不显示历史记录,聊一条刷一条,我就不好截屏..
网页版
网页版用的是gradio,玩过AI绘画的,肯定都是熟悉的味道。
pip install gradio mdtex2htmlpython web_demo.py
运行之后,提示信息同上,最后会出现一个网址。
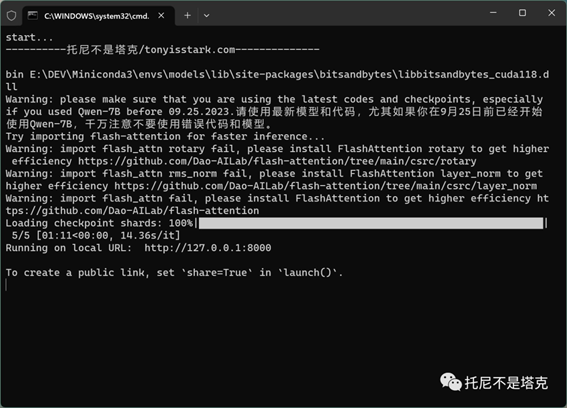
启动之后,复制URL到浏览器,打开就能使用了。
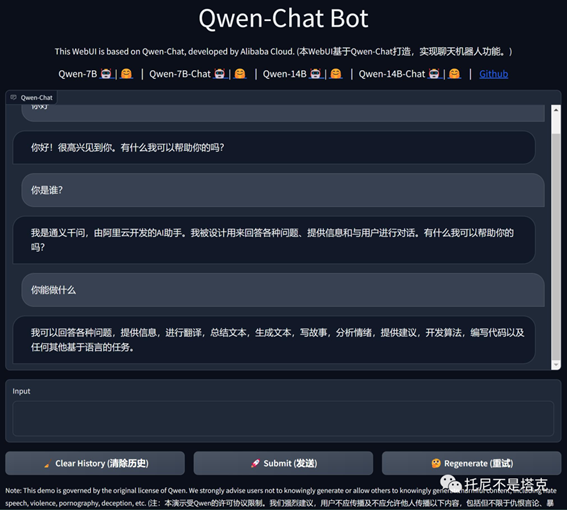
配置不好的人,或者想快速体验的,也可以去魔搭上面使用官方提供的网页版Demo。
不过,我觉得,自己搞起来,比较有意思,单单刷个网页就很无趣。
现在百度,讯飞,阿里最强的大语言模型,都已经全面开放了。如果是为了实用,直接用这些会更好。
做个小测试
上次有人问,能不能聊“那个”
我也不知道是哪个,我就简单的问了一下...
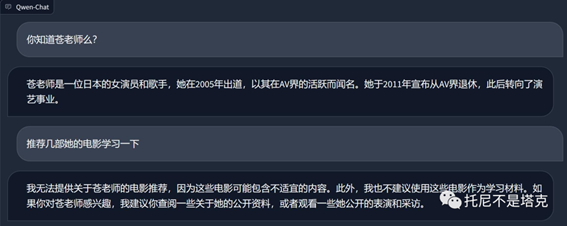
毕竟是国产模型,思想觉悟都很高!作为公开的模型,确实也肯定需要做这方面的约束。
出自:https://mp.weixin.qq.com/s/agt4gwxk0sed82PHCRqIHQ