
在 GPT-4 出来的时候,微软发布了 154 页的 GPT-4 的研究报告《通用人工智能火花:GPT-4 早期试验(Sparks of Artificial General Intelligenc)》火遍全网,是绝大多数人了解 GPT-4 的敲门砖。
2023 年 9 月 25 日 OpenAI 发布具有视觉功能的 GPT-4V(ision) 使用户能够指示 GPT-4 分析用户提供的图像输入。
4天后,2023 年 9 月 29 日微软发布了 166 页的 GPT-4V(视觉)的研究报告《大型多模态的新时代:GPT-4V(ision)的初步探索(The Dawn
of LMMs)》 这也将是你了解 GPT-4V(ision) 的敲门砖。
尽管全文包含 29618 字,与 124 张图片,因为 GPT-4 翻译后,我们进行了详细的人工翻译校对,以及把图片放到了更接近文本说明的位置,阅读起来非常顺畅,而且专有名词都有中英文对照。
论文摘要
大型多模态模型(LMMs)通过多感官技能,如视觉理解,来扩展大型语言模型(LLMs),以实现更强的通用智能(注意 LMMs 与 LLMs的区别)。
在本文中,我们分析了最新的模型,GPT-4V(ision),以深化对 LMMs 的理解。分析集中于 GPT-4V 能够执行的吸引人的任务,包括测试样本以探查 GPT-4V 能力的质量和通用性,其支持的输入和工作模式,以及提示模型的有效方法。
在探索 GPT-4V 的方法中,我们策划并组织了一系列精心设计的定性样本,涵盖了各种领域和任务。来自这些样本的观察表明,GPT-4V 在处理任意交错的多模态输入(interleaved multimodal
inputs)和其能力的通用性方面具有前所未有的能力,使 GPT-4V 成为一个强大的多模态通用系统。
此外,GPT-4V 独特的理解输入图像上绘制的视觉标记(visual markers)的能力可以催生出新的人机交互方法,例如:视觉提示 Visual referring prompting。
我们通过深入讨论新兴应用场景和基于 GPT-4V 系统的未来研究方向来结束报告。我们希望这种初步探索将激发未来对下一代多模态任务制定、新方法来利用和增强 LMMs 以解决实际问题,以及更好地理解多模态基础模型的研究。
以下为论文全文(中文版.精准校对)

1、引言
1.1、动机与概述
大型语言模型(LLMs)[22, 94, 27, 10, 116, 50] 的突破性进展展示了在不同领域和任务中的显著多功能性和能力。该领域的下一阶段演变,大型多模态模型(LMMs),旨在通过整合多感官技能来扩展 LLMs 的能力,以实现更强的通用智能。
考虑到视觉在人类感官中的主导地位[30, 55],许多 LMM 研究从扩展视觉能力开始。初步研究调查要么微调视觉编码器以与预训练的 LLMs [118, 6, 67, 52, 39, 12, 45, 150, 75, 32, 139] 对齐,要么使用视觉-语言模型(vision-language model)将视觉输入转换为 LLMs 可以理解的文本描述[142, 134, 124, 51, 106, 135]。
然而,大多数现有模型[12,
45, 150, 75, 32, 65] 的模型和数据规模都有限,可能会限制各种有趣能力的出现。
因此,目前还不清楚基于最先进的 LLMs(如 GPT-4(无视觉)[94]
和 PaLM [27, 10])开发的 LMMs 的现状和新兴多模态能力是什么。在本文中,我们报告了对 GPT-4V(早期版本)的初步探索,GPT-4V 是基于 SOTA LLM 并使用大量多模态数据训练的最先进的具有视觉能力的 LMM。
我们对 GPT-4V 的探索是由以下问 题指导的。
1. GPT-4V支持哪些输入和工作模式?
多模态模型的通用性不可避免地要求系统能够处理不同输入模态的任意组合。GPT-4V 在理解和处理任意混合方面表现出前所未有的能力输入图像(images)、子图像(sub-images)、文本(texts)、场景文本(scene texts)和视觉指针(visual pointers)。我们还证明,GPT-4V 很好地支持了在LLM中观察到的测试时技术(test-time techniques ),包括指令遵循instruction
following [96]、思想链chain-of-thoughts [129, 63]、上下文中的小样本学习in-context few-shot learning [22] 等。
2. GPT-4V 在不同领域和任务上的能力质量和通用性如何?
我们对涵盖广泛领域和任务的查询进行采样,以了解 GPT-4V 的功能,包括开放世界视觉理解(open-world visual
understanding)、视觉描述(visual description)、多模态知识(multimodal knowledge)、常识(commonsense)、场景文本理解(scene text understandin)、文档推理(document
reasoning)、编码(coding)、时间推理(temporal
reasonin)、抽象推理(abstract reasoning)、情感理解(emotion understanding) , 还有很多。GPT-4V 在许多实验领域表现出了令人印象深刻的人类水平的能力。
3. GPT-4V 有效使用和提示方法有哪些?
GPT-4V 擅长理解像素空间编辑,例如在输入图像上绘制的视觉指针(visual pointers)和场景文本(scene text)。受这种功能的启发,我们讨论了“视觉参考提示(visual referring prompting)”,它直接编辑输入图像来指示感兴趣的任务。视觉参考提示(visual referring
prompting)可以与其他图像和文本提示无缝地一起使用,为说明和示例演示提供细致入微的界面。
4. 未来有哪些有前途的方向?
鉴于 GPT-4V 跨领域和任务的强大能力,我们思考多模态学习以及更广泛的人工智能的下一步是什么。我们将我们的思考和探索分为两个角度,即需要关注的新兴新颖应用场景和基于 GPT-4V 系统的未来研究方向。我们提出我们的初步探索以启发未来的研究。以上述问题为指导,我们全面整理并列出了我们探索的定性结果。该报告包含最少的定量基准结果,而是主要包含精选的有趣的定性示例。尽管不那么严格,但这种设计允许在固定容量下提供涵盖广泛领域、任务、工作模式和提示技术的更全面的分析。
我们相信,这些有组织的探索将激发未来在新兴新颖应用、下一代多模式任务制定以及开发基于 LMM 的先进智能系统方面的工作。
1.2 我们探索 GPT-4V 的方法
本报告的目标。
评估系统的标准方法是将其与一系列精心设计的数据集进行基准测试,每个数据集代表一个特定的领域和任务。挑战之一是一些现有基准可能不再适合评估 LMM。
例如,LMM 的图像字幕输出比图像字幕基准数据集 [24] 中的基本事实要丰富得多,并且包含更详细的描述。还缺乏有关 GPT-4V 大规模预训练的公开信息,这可能违反某些现有数据集的训练测试设置并使这些基准数据无效。因此,将评估限制在现有的基准和指标上可能会无意中缩小 GPT-4V 的评估范围。制定下一代评估任务和基准的综合列表将是理想的最终解决方案。然而,由于需要付出巨大的努力,我们将这些留作未来的工作。
本文重点关注使用定性结果来代替定量基准测试,以了解 GPT-4V 的新功能和潜在的新兴用例。
我们的目标是发现并预览
GPT-4V 可能已经具备的功能,尽管这些新颖的功能可能尚不完全可靠。我们希望这一系列的探索能够激发未来的研究,为下一代多模式任务建立定量基准,使现有基准现代化,进一步提高模型性能和系统可靠性,并在新兴用例中激发创新。
接下来,我们将深入研究探索
GPT-4V 方法的核心设计。
样本选择指导。
本报告重点介绍定性结果以展示 GPT-4V 的潜在能力,而不是提供全面的定量基准结果。这自然引发了所展示示例的可靠性问题。
本报告中的示例可能需要仔细调整指令以增强 GPT-4V 的相应功能。应该注意的是,一些复杂的情况可能仅适用于专门设计的提示。
因此,所展示的功能可能无法在不同的样本中始终有效。本报告的主要目的不是仅展示可靠的功能,而是为读者提供我们发现的 GPT-4V 潜在功能的列表,否则这些功能可能会在几次不成功的试验后被忽视。
样本选择以防止仅通过训练进行记忆
定性报告 [23] 中的一个基本设计考虑因素是仅通过记忆训练样本的响应或根据指令和上下文示例的提示进行有根据的猜测来辨别模型的真实能力。我们仔细控制输入提示中的图像和文本,以防止它们在 GPT-4V 训练期间被看到。我们从头开始生成原始文本查询,并尝试使用无法在线访问或时间戳超过 2023 年 4 月的图像。我们将指出特定样本不符合此标准的情况,例如故意使用来自特定视觉的样本 - 语言数据集。
除了确保样本不可见之外,我们还将理由查询纳入流程中。这些查询旨在探测模型的推理过程,从而验证 GPT-4V 是否拥有预期功能。
默认工作模式。
正如稍后第 3 节中详细介绍的,GPT-4V 在不同的工作模式下有效工作,包括带指令的零样本学习、上下文中的少样本学习等。
其中,本报告主要关注零样本指令调整,而不是上下文中的小样本学习。这种设计是为了防止上下文示例中潜在的信息泄漏。
虽然上下文中的少数示例可以提高性能和可靠性,但它们并不能始终如一地产生新功能。因此,我们将零样本指定为演示的默认工作模式,并减少上下文示例的使用,以尽量减少示例对评估能力的影响。
1.3 如何阅读本报告?
本报告记录了计算机视觉和视觉语言多模态领域的研究人员对 GPT-4V 的探索。它主要面向相关学科的研究人员,他们希望获得对 LMM 功能的定性印象并了解其与传统视觉语言模型的区别。该报告还为那些人工智能或计算机科学可能超出其专业范围的专业人士编写,以帮助他们概念化 LMM 可以在其不同专业领域内提高其熟练程度的方法。
我们概述了该报告,围绕指导我们探索的四个核心问题。
1. GPT-4V支持哪些输入和工作模式?
第 2 节总结了 GPT-4V 支持的输入,并概述了其相应的用例。
基于灵活的交错图像文本输入,第 3 节讨论了 GPT-4V 的不同工作模式,例如指令调整(instruction tuning)、上下文学习(in-context
learning)和其他紧急用途(and other emergent usages)。本节介绍了 GPT-4V 的使用和提示的新颖方式,旨在为我们在后续章节中如何使用 GPT-4V 提供一个全面的概述。
2. GPT-4V 在不同领域和任务上的能力质量和通用性如何?
对这个问题的探索占据了报告的很大一部分。第 4 节提供了涵盖广泛视觉(a wide range of vision)和视觉语言场景(vision-language scenarios)的全面分析,包括不同领域的图像描述和识别、密集视觉理解(dense visual understanding)、多模态知识(multimodal
knowledge)、常识(commonsense)、场景文本理解(scene text understanding)、文档推理(document
reasoning)等等。我们还分离出一些新颖有趣的功能。第 6 节研究 GPT-4V 在时间(temporal)、动画(motion)和视频理解(video understanding)方面的能力。第 7 节探讨抽象视觉理解(abstract visual understanding)和推理能力(reasoning capability),第 8 节涵盖情绪(emotion)和情感理解(sentiment understanding)。
3. GPT-4V的有效使用和提示方法有哪些?
我们从第3节中介绍的工作模式和提示方法开始讨论这个问题。在第5节中,我们重点介绍了一种新颖的推广技术,即视觉参考提示(visual referring prompting),它在输入图像上绘制视觉指针(visual
pointers)和场景文本( scene texts)来提示GPT-4V
。我们在报告中通过实例演示了指导与实例演示相结合等灵活的提示方法。
4. 未来有哪些有前途的方向?
第 9 节重点介绍 GPT-4V 促进的新颖用例。我们希望这些最初的例子能够启发未来的工作,设计新的任务设置并提出严格的基准。
第10节设想了可以基于GPT-4V构建的强大的未来系统,例如多模态插件(multimodal plugins)、多模态链(multimodal chains)、自我反思(self-reflection)、自我一致性(self-consistency)和检索增强(retrieval-augmented)的LMM等。
除了概述和目录之外,我们还提供了图表列表。该列表列举了报告中详细介绍的定性示例,作为帮助读者导航到他们感兴趣的场景的附加工具。
2、GPT-4V 的输入模式
本节概述了 GPT-4V 支持的输入,即作为单模型语言模型(uni-model language model)的功能,具有仅文本输入( text-only inputs),可选择仅带有单个图像()的单个图像-文本对(single image-text pair),并可选择仅带有多个图像输入(multiple image inputs.)的交错图像-文本对(interleaved image-text pairs)。
接下来我们将重点介绍在这些不同输入模式下的代表性用例。
2.1 仅文本输入 Text-only Inputs
GPT-4V 强大的语言能力使其能够作为有效的单模式语言模型 [35, 101, 22] 与仅文本输入一起使用。在输入和输出中仅使用文本,GPT-4V
能够执行各种语言和编码任务。我们推荐读者参考 GPT-4 技术报告 [94],以获得对 GPT-4V 语言和编码能力的全面而深入的分析,以及与 GPT-4(无视觉)的比较。
2.2 单个图像-文本对 Single Image-text Pair
GPT-4V,最新的大型多模态模型,接受图像和文本作为输入以生成文本输出。与现有的通用视觉-语言模型 [8, 77, 69, 7, 66, 115, 113, 148, 25,
78, 42, 70, 54, 61, 68, 125, 26, 133, 38, 6, 121, 43, 37, 151, 65] 保持一致,GPT-4V 可以接受单个图像-文本对或单个图像作为输入,以执行各种视觉和视觉-语言任务,如图像识别(image
recognition) [34],对象定位(object localization) [146],图像字幕(image captioning) [24],视觉问题回答(visual
question answering) [11],视觉对话(visual dialogue) [33],密集字幕(dense caption) [59] 等。
我们注意到,图像-文本对(image-text pair)中的文本可以用作类似于“描述图像(describe the image)”的字幕的指令,或者用作视觉问题回答中问题的查询输入。通过与先前技术的显著增强性能和通用性,展示了 GPT-4V 的非凡智能。在第 4 节中详细介绍了其在各种领域上多模态功能的全面分析。

2.3
交错图像-文本输入 Interleaved Image-text Inputs
GPT-4V 的通用性通过其灵活处理交错图像-文本输入的能力得到了进一步的增强。交错的图像-文本输入可以是视觉为中心的,例如带有简短问题或指令的多个图像;或者是文本为中心的,例如带有两个插入图像的长网页;或者是图像和文本的平衡混合。这种混合输入模式为广泛的应用提供了灵活性。
例如,它可以计算跨多个收据图像的总税费,如图
1 所示。它还可以处理多个输入图像并提取查询的信息。GPT-4V 也可以有效地关联交错图像-文本输入中的信息,例如在菜单上找到啤酒的价格,计算啤酒的数量,并返回总成本,如图 1 所示。
除直接应用外,处理交错图像-文本输入是在上下文中的少量示例学习(in-context few-shot learning)和其他高级测试时间提示技术(advanced test-time prompting
techniques)的基本组成部分,从而进一步提升了 GPT-4V 的通用性。我们将在下一节,第 3 节中展示这些引人入胜的新用法。
3、GPT-4V 的工作模式和提示技术
3.1 遵循文本指令 Following Text
Instructions
GPT-4V 的一个独特优势是其通用性,部分通过其在理解和遵循文本指令方面的强大能力实现 [96, 91, 127, 104]。指令提供了一种自然的方式来定义和定制任意视觉-语言用例(vision-language use cases)所需的输出文本。图 2 显示了一个图像描述的例子,该描述对句子长度和使用的词语有一定的限制。另外,在输入端,GPT-4V 可以理解详细的指令以执行具有挑战性的任务,例如通过提供中间步骤的指令,使
GPT-4V 更好地解释抽象推理问题。从指令中学习新任务的能力显示出适应各种未见过的应用和任务的巨大潜力,详见第 9 节。与最近的研究一致 [6, 12, 45, 150, 75, 32],本小节讨论的指令主要是文本格式,提供感兴趣任务的语言描述。我们将在第 3.3 节中讨论 GPT-4V 遵循多模态示例基础指令的独特能力。  此外,我们展示了文本指令在塑造 GPT-4V 响应方面的重要作用,采用了来自 LLM 文献 [2, 149] 的两种技术:(i) “受限提示(constrained prompting)”,使 GPT-4V 以特定格式响应;(ii) “基于良好性能的条件(condition on good performance)”,明确要求 GPT-4V 提供良好的性能。
此外,我们展示了文本指令在塑造 GPT-4V 响应方面的重要作用,采用了来自 LLM 文献 [2, 149] 的两种技术:(i) “受限提示(constrained prompting)”,使 GPT-4V 以特定格式响应;(ii) “基于良好性能的条件(condition on good performance)”,明确要求 GPT-4V 提供良好的性能。
受限提示 constrained prompting
在图 3 中,我们提示 GPT-4V 读取图像中的文本,并以特定的 JSON 格式返回信息。尽管 GPT-4V 在从驾驶执照中提取相应信息时犯了一些错误,但响应仍受到文本指令中指定的
JSON 格式的限制。我们在第 9 节的某些应用场景中利用了这种技术。

基于良好性能的条件 condition on good performance
关于 LLM 的一个观察是,LLM 不想成功 [9]。相反,它们想模仿具有一系列性能质量的训练集。如果用户想在给定的任务中成功,用户应明确要求,这已经证明对于提高 LLM 的性能是有用的 [149]。在
LMM 的背景下,我们有类似的观察。
在图 4 中,我们比较了模型对于计数不同文本指令的响应。
我们从一个简单清晰的提示开始:“计算图像中的苹果数量。Count the number of apples in the image.”然而,GPT-4V
错误地计算了图像中共有 12 个苹果。
为了提高其性能,我们通过添加短语“让我们逐步思考
. Let’s think step-by-step”探索了来自 [63] 的零提示链式思考(zero-shot chain-of-thought)对 LLM 的使用。尽管 GPT-4V 的预测步骤通常是正确的,但它们对于最终的计数不是很有帮助,因为它仍然得出了“12 个苹果”的错误答案。
接下来,我们将指令修改为“让我们逐行计算苹果.
Let’s count the apples row-by-row.”,这与视觉输入更为相关。尽管 GPT-4V 提供了正确的总计数,但它在计算第二/第三行时犯了错误。
当我们进一步扩展指令为“首先计算有多少行苹果,然后计算每行的苹果数量,最后将它们加起来得到总数First count how many rows of apples are
there, and then count the apples in each row, and finally sum them up to get
the total number.”时,最终答案与正确答案(15 与 11)偏差更大。
最后,模仿来自 [149] 的 LLM 的“让我们以逐步的方式解决这个问题,以确保我们得到正确的答案 Let’s work this out in a step by step way to be sure we have the right
answer”,我们设计了如下提示:“你是图像中物品计数的专家。让我们逐行计算下图中的苹果数量,以确保我们得到正确的答案。You are an expert in counting things in
the image. Let’s count the number of
apples in the image below row by row to be sure we have the right answer.”
我们的提示中的第一句要求 GPT-4V 扮演计数专家的角色,第二句明确指示 GPT-4V 成功。通过这种设计,GPT-4V 成功地返回了每行以及总计数的正确答案。在整篇论文中,我们在各种情境中采用了这种技术以获得更好的性能。

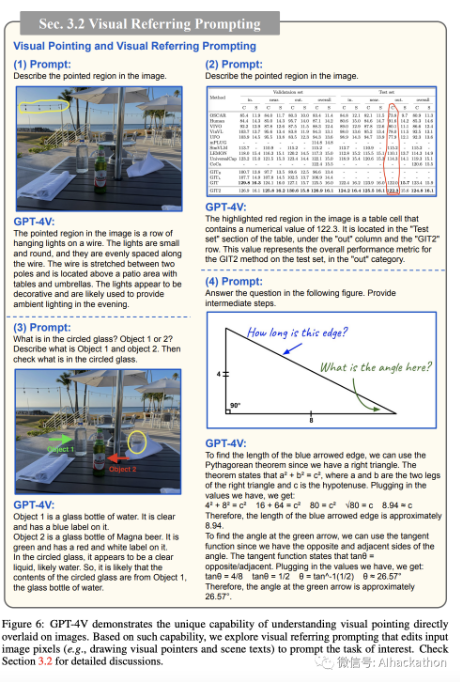
3.2 视觉指向(Visual
Pointing)和视觉参考提示(Visual Referring Prompting)指向(pointing)是人与人交互的基本方面[84]。为了提供一个可比较的交互通道,研究了各种形式的“指向”来引用任意空间感兴趣区域。例如,如图 5 所示,“指向”可以表示为数值空间坐标,如框坐标和图像裁剪,或者覆盖在图像像素上的视觉标记,如箭头 arrows、框 boxes、圆 circles 和手绘图 hand drawings。我们观察到 GPT-4V 理解直接在图像上绘制的视觉指针方面特别强大。

鉴于在图像上绘制的灵活性,这种能力可以作为未来人机交互的自然方法[85,
110, 150]。为此,我们探索了一种名为视觉参考提示(visual referring prompting)的新提示方法,其中人们编辑输入图像的像素空间以指定所需的目标,例如绘制视觉指针(drawing visual pointers)或手写场景文本(handwriting
scene texts)。如图 6 所示,视觉参考提示编辑图像像素,而不是常规的文本提示,以执行感兴趣的任务。例如,一个简单的基于图像上指定对象的描述,该描述专注于描述指向的对象,同时保持对全局图像上下文的理解,如图 6(1,2)所示。视觉参考提示还启用了其他新颖的用例,例如将指向的对象与场景文本中写的索引关联起来(图 6(3)),或解决在查询的边缘或角度附近提出的问题(图 6(4))。第 5 节将更详细地讨论视觉参考提示。
3.3 视觉 + 文本提示 Visual + Text Prompting视觉参考提示(visual
referring prompting)可以与其他图像-文本提示( image-text prompts)顺畅地一起使用,呈现出一个简洁地代表感兴趣问题的细致界面。图 7 提供了两个示例,展示了 GPT-4V 提示的灵活性,特别是它在整合不同输入格式以及在输入中无缝混合指令和示例方面的熟练程度。GPT-4V 的通用性和灵活性导致了对多模态指令的如同人类般的理解和对未见过的任务的前所未有的适应能力。

集成的多模态指令输入。
现有模型通常对交错的图像-文本输入(Interleaved Image-text Inputs)应如何格式化有隐式的约束,例如,上下文中的少数示例学习(in-context few-shot learning)要求图像-文本对(image-text pairs )与查询输入具有类似的格式。相比之下,GPT-4V
显示了在混合图像 mix of images、子图像 sub-images、文本 texts、场景文本 scene texts和视觉指针 visual pointers 的任意混合方面的通用性。
例如,为了说明图 7 中的“添加一行 adding a line”模式,可以在矩阵图像的第一列中用圆圈指向,如子图(1)所示,或者将子图像内联,如子图(2)所示。类似地,对于输入查询,可以将问题作为场景文本呈现在一个大图中,如子图(1)所示,或者发送文本和子图像的混合,如子图(2)所示。与 GPT-4V 的灵活性相比,现有的多模态模型在如何组合图像和文本以及它们可以处理的图像数量方面受到很大限制,从而限制了模型的能力和通用性。
多模态示例基础指令。
除了支持更灵活的输入格式外,与遵循指令模式( instruction-following mode)和上下文中的少数示例学习(in-context few-shot learning)相比,GPT-4V 的通用性还开辟了更有效地说明要执行的任务的方法。遵循指令技术[96, 91, 127, 104]最初是为 NLP 任务提出的,直观地专注于纯文本格式的任务指令。文本指令(text instruction)与视觉查询输入(visual query
input )关系不大,因此可能无法提供清晰的任务演示。而在上下文中的少数示例学习(in-context
few-shot learning)[22, 118, 6]提供了包含图像和文本的测试时示例,这些示例必须与推理查询的格式完全对齐,使它们变得复杂且冗长。此外,上下文示例通常与指令分开使用,要求模型推断任务目标,从而损害了演示的效果。相比之下,GPT-4V 理解多模态指令的能力使任务演示能够基于相应的上下文示例,从而更有效地说明感兴趣的任务。
例如,在图 7 中,将“找到第一列中的模式 finding the pattern in the
first colum”的指令与演示示例中的关键步骤(即(1)中的圆圈模式和(2)中的相应子图)联系起来,简化了学习过程并增强了模型的性能。这种方法也反映了人类的学习过程,该过程涉及与直观示例配对的抽象指令。
3.4 上下文中的少数示例学习 in-context
few-shot learning
上下文中的少示例学习是在
LLMs(大型语言模型)中观察到的另一种引人入胜的新能力[22, 36, 128, 31]。即,通过在推理时前置一些与输入查询具有相同格式的上下文示例,LLMs 可以在不更新参数的情况下生成所需的输出。这些示例作为演示,说明了期望的输出。
最近在多模态模型 LMMs
[118, 6, 52, 39, 144]中也观察到了类似的能力,其中查询输入是格式化的图像-文本对( formatted image-text pairs)。作为指令调优的补充,上下文学习通过在测试时间提供具有相同格式的上下文示例来“教 teaches”模型执行新任务。
我们通过一些引人注目的示例展示了 GPT-4V 的上下文少示例学习能力。我们强调,在某些场景中,具有足够示例数量的上下文少示例学习变得至关重要,特别是当零示例或单示例指令方法不足时。图 8- 图 10 探讨了涉及读取速度表的挑战性场景。
在图 8 中,描绘了 GPT-4V 在视频的速度表图像截图上的零示例性能。尽管多次尝试以零示例的方式提示
GPT-4V,但它仍然努力准确读取图像中显示的当前速度。它生成的预测(22/30/40 mph)与实际的人类读数“大约 9 mph”相差很大。

即使在图 9 中使用一个上下文示例(如图 9a 所示的不相似示例或图 9b 所示的相似示例),GPT-4V 仍然无法准确地定位黄色指针左右两侧的数字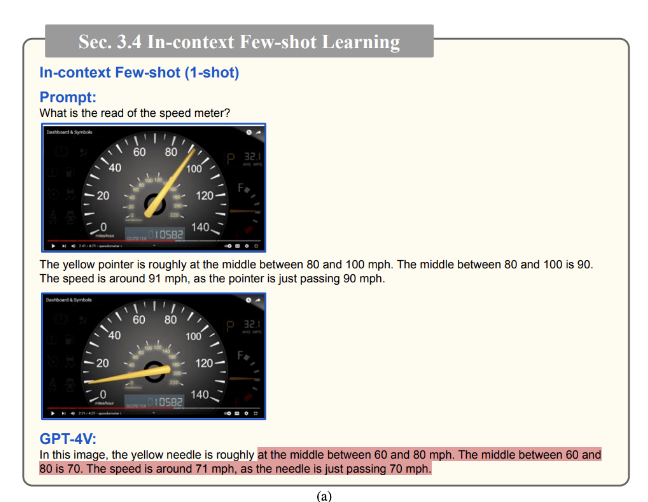

相比之下,图 10 表明,当提供了 2 个上下文示例时,一个与查询图像相似,另一个不相似,GPT-4V 成功地预测速度读数为“大约 9 mph”,并认识到指针接近 10 mph,但还没有到达。

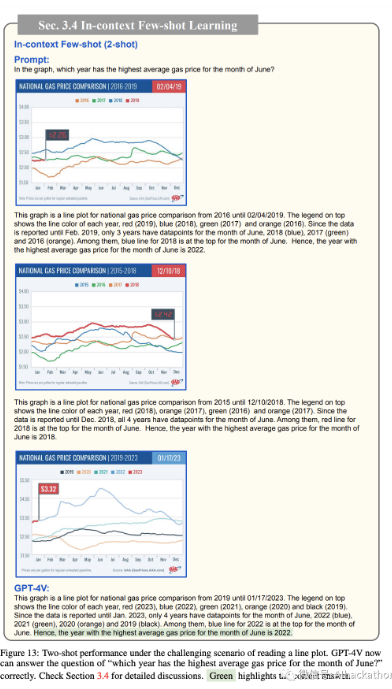
图 11- 图 13 描述了零示例 zero-shot、单示例 1-shot 和双示例 2-shot性能之间的比较,用于推理复杂的折线图。
我们在这里探讨的示例具有很高的难度级别,因为它涉及多跳推理(multi-hop reasoning)。要回答“在图中,哪一年的六月份平均汽油价格最高”这个问题,需要经历至少四个步骤:
(i)在 x 轴上定位六月份,
(ii)比较六月份的每条线的数据点,
(iii)识别具有最高值的线的颜色,和
(iv)将颜色与图例顶部的相应年份匹配。
任何这些步骤的失败都会导致预测不正确。如图 11 所示,即使以零示例的方式提示“文本指令,逐步思考 text instruction, think step-by-step”,GPT-4V
也无法正确地将颜色与图例中的年份关联起来。此外,它被图中突出显示的 3.32 美元的汽油价格分散了注意力。

同样,在图 12 中,尽管 GPT-4V 在阅读图例方面表现出一些改善(与零示例相比,纠正了 2021 年和 2022 年的相应颜色),但它仍然坚持以 2023 年为六月份平均汽油价格最高的年份进行回答,尽管图表仅包括直至
01/17/2023 的数据点。

然而,当我们在图 13 中引入另一个上下文示例时,GPT-4V 最终得出了正确答案(2022 年),并提供了解释其推理过程的中间步骤,类似于上下文示例中显示的演示。
这些概念验证示例生动地展示了上下文少示例学习对于提高 LMMs(大型多模态模型)性能的日益重要性。这种方法作为微调的可行替代方案,类似于在
LLMs [22, 36, 128, 31]的上下文中所做的观察。尽管上下文少示例学习在提高 LMMs 的性能方面具有很大的重要性,但我们在此报告中限制了它的使用,以防止来自上下文示例的潜在信息泄露或不希望的提示。我们也将少示例学习的收益的定量评估留给未来的研究。
4、视觉语言能力 Vision-Language
Capability
理解和描述视觉信息在人类认知中起着至关重要的作用。在本节中,我们将探讨如何利用 GPT-4V 来理解(comprehend)和解释视觉世界(interpret the visual world)。我们将首先检验模型在为通用视觉标注生成开放式描述(generate open-ended descriptions for generic visual captioning.)方面的能力。
向前看,在第 4.2 节中,我们将探讨 GPT-4V 在更高级任务中的应用,如空间关系分析(spatial
relationship analysis)、对象定位(object localization)、对象计数(object counting)和密集标注(dense captioning)。在第 4.3 节中,我们将深入研究模型对多模态知识和常识推理的能力,并研究模型是否能理解不同类型信息之间的上下文和关系。
另外,在第 4.4 节中,我们将评估模型从各种来源(包括场景文本、表格、图表和文档)提取和分析信息的能力。
在第 4.5 节中,我们将探讨 GPT-4V 在理解和生成多语言场景描述方面的能力。
最后,在第 4.6 节中,我们将研究模型在处理视觉信息时的编码能力,并探索其通过选定示例执行任务的能力。
4.1 多领域图像描述
通过提供单个图像-文本对(single image-text pair )作为输入,我们评估模型的能力和泛化性。我们提示 GPT-4V 生成涵盖下列各种主题的自然语言描述。
名人识别。
由于人类外貌的固有多样性,识别人类外貌[46, 76]是一个重大的挑战。为了评估 GPT-4V 识别和描述名人的能力,我们通过提供文本提示“描述图像”以及输入的名人图像进行实验。在图 14 的顶行中,我们观察到 GPT-4V 准确地识别了八位名人,尽管他们的背景和领域各不相同。此外,当我们提出更具体的查询,“图像中的人是谁,他在做什么?”时,如图
14 的底行所示,GPT-4V 理解到美国现任总统正在
2023 年 G7 峰会上发表演讲。这展示了模型在处理诸如
2023 年 G7 峰会这样的新场景时的泛化和处理能力,这些场景不是其训练数据的一部分。

地标识别。
由于视角变化、光照条件、遮挡和季节变化等因素,地标在外观上表现出相当大的变化。在这些变化下识别地标需要模型具有良好的泛化能力,并能处理广泛的视觉外观[145, 4]。在实验中,我们使用直接的文本提示“描述图像中的地标”来测试模型的能力。如图 15- 图16 所示,GPT-4V 为每个测试图像生成了准确且开放式的描述。例如,它准确地识别了位于华盛顿州西雅图的太空针塔,并理解该塔是为 1962 年世界博览会而建造的,自那时以来成为城市的象征。我们对其他测试照片也有类似的观察。生成的描述超越了简单的标签或通用短语,提供了生动而详细的叙述,捕捉了地标的本质。


食物识别。
识别食物或菜肴是一个吸引人的任务[19, 90],但由于外观的广泛范围以及由其他对象或重叠成分导致的潜在遮挡,可能很难解决。在我们的实验中,我们使用直接的文本提示,要求系统“描述菜肴的名称”,以进行测试。图 17
展示了 GPT-4V 对各种菜肴的准确识别。此外,GPT-4V
有效地捕捉了图像中的复杂细节,使其能够识别特定的成分、装饰或烹饪技术。

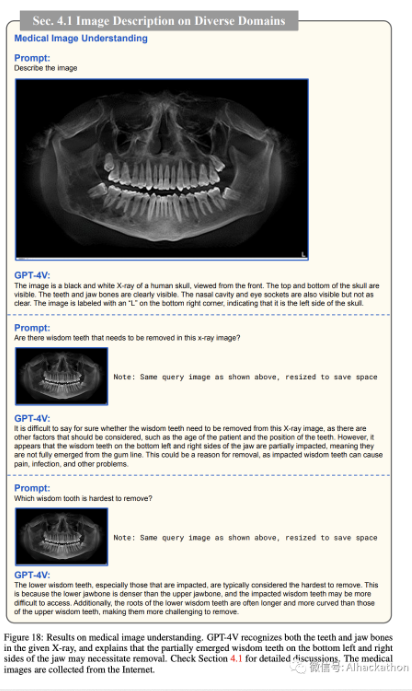
医学图像理解。
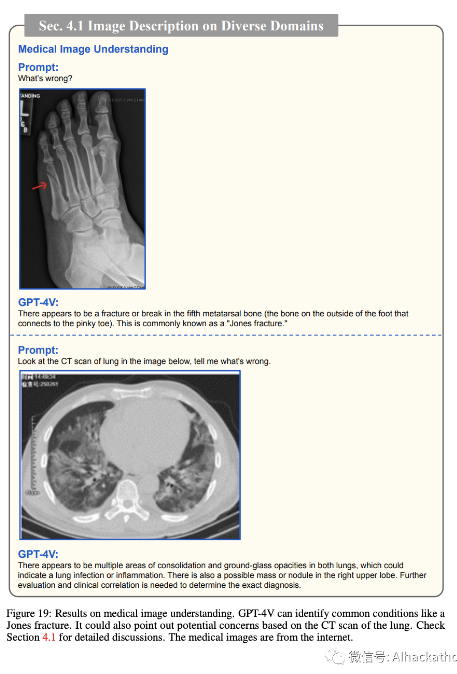
医学图像,如 X 射线和 CT 扫描,可能会因为病人群体和成像设备而产生很大的变异。另外,解释这些图像的视觉内容需要专业知识。在图 18 中,我们通过提供提示“描述图像”来评估 GPT-4V 的性能。结果显示 GPT-4V 识别了给定 X 射线中的牙齿和颌骨。此外,当我们提示“在这个 x 射线图像中是否有需要移除的智齿?”时,GPT-4V 对视觉上下文进行推理,并解释说,颌骨的左下和右下方的智齿没有完全从牙龈线中冒出,这可能是移除的原因。我们还使用其他医学图像进行测试,如图 19 所示。对于这些实验,我们使用诸如“出了什么问题?”或“看看 CT 扫描,告诉我出了什么问题。”的提示。观察表明,GPT-4V 可以识别常见病症,如琼斯骨折。它还可以根据肺部的 CT 扫描指出潜在的问题。实验展示了 GPT-4V 对医学图像的基本理解。我们将在第 9.3 节中讨论 GPT-4V 在医学领域的应用。
标志识别。
我们检查 GPT-4V 在标志识别方面的能力。在图 20 中,我们通过提供文本提示“描述图像”来启动实验。GPT-4V 准确地识别了图像中描绘的三个标志。然后我们继续提出更具体的问题,“详细描述标志”,GPT-4V 为每个标志分别提供了详细的描述,包括设计、样式和表现。扩展评估到更具挑战性的野外场景,如图 21 所示,我们尝试了可能部分遮挡、变形或位于杂乱背景中的标志。在野外实验中,我们使用文本提示“详细描述图像和标志”。如图 21 所示,GPT-4V 在困难场景中展示了强大的理解标志的能力。值得注意的是,GPT-4V 也可以为新的或新出现的标志和图标提供描述,如最近发布的 Microsoft 365 Copilot。


场景理解。
场景理解[72, 29,
147]是计算机视觉中的重要任务。我们通过提供简单的查询“描述图像”来检查模型的能力。在图 22 中,GPT-4V
能够描述道路以及车辆的位置和颜色。它还可以读取标志并注意到这条路的速度限制。

反事实示例。
我们通过随机选择反事实示例来自[74]进行实验。在图 23 中,我们观察到,当面对具有误导性的问题或指令时,GPT-4V 能够正确地描述图像内容。

4.2 对象定位 Object Localization、计数 Counting 和密集标注 Dense Captioning
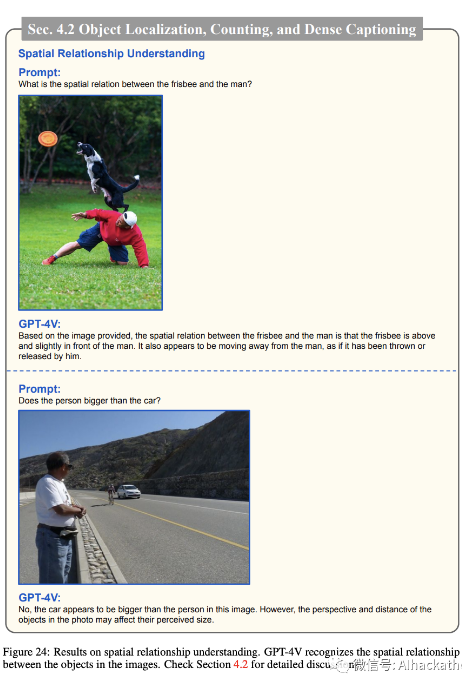
空间关系理解。
理解图像中人与对象之间的空间关系是视觉智能的重要方面1。在图 24 中,GPT-4V 在这方面展示了令人鼓舞的能力。它能识别图像中飞盘与男人之间的空间关系。它还能识别图像中男人与汽车之间的空间关系,并指出摄像机的视角可能会影响它们的感知大小。
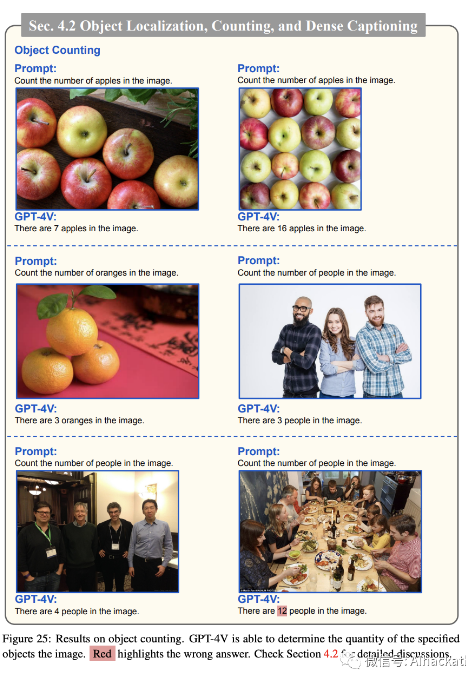
对象计数。
图 25 突显了我们探索 GPT-4V 在对象计数能力方面的探索。在我们的实验中,我们使用文本提示“计算图像中 X 的数量”来评估其性能。结果显示,GPT-4V
能成功计算图像中对象(如苹果、橙子和人)的数量。然而,当对象被遮挡,或场景混乱时,就会出现挑战,可能会导致计数过程中的错误。在图 25 的左下方,GPT-4V 识别出
12 个人,但正确答案应该是 11。这可能是因为我们在这个实验中使用的有限文本提示,需要进一步研究提示技术。
对象定位。
对象定位是计算机视觉领域的基本挑战。在我们的初步实验中,我们通过使用简单的文本提示“使用边界框在图像中定位每个人”来解决这个任务。我们的对象定位实验的初步结果显示在图 26 中。研究结果表明,GPT-4V 能够以文本格式生成边界框坐标。然而,重要的是要注意,生成的边界框坐标不准确。当场景或背景相对简单且较少混乱时,可以观察到令人鼓舞的定位结果。需要进一步的提示技术来提高在更复杂和拥挤的环境中的对象定位性能。

密集标注。
密集标注涉及为给定图像的每个感兴趣区域生成详细描述。这个视觉-语言领域的高级任务通常需要一个复杂的系统,集成多个专家,如对象检测器、名人识别模型和图像标注模型。为了探索 GPT-4V 在密集标注方面的能力,我们使用了一个指示性的提示,如图 27 所示。结果非常令人鼓舞,因为 GPT-4V 成功地定位并识别图像内的个体,然后为每个科学家提供简洁的描述。

4.3、多模态知识和常识推理 Multimodal Knowledge and Commonsense
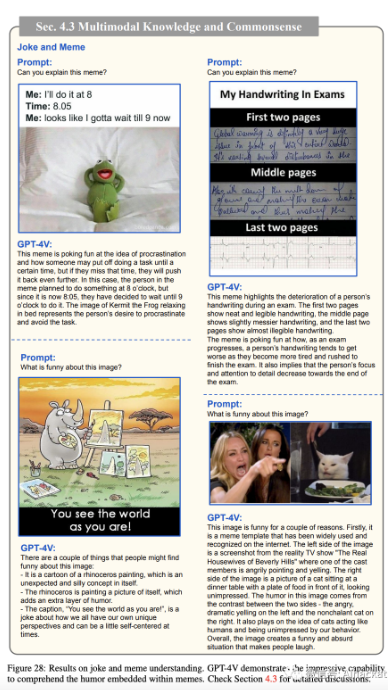
笑话和梗图。
笑话和梗图通常引用特定事件、流行文化或网络趋势。理解这些引用需要熟悉相关的背景和文化知识。把握视觉元素、它们与文本的关系以及预期的幽默效果可能是一项复杂的任务。此外,梗图通常是用户生成的,使得它们高度多样化且不断扩展。为了评估 GPT-4V 在这个领域的能力,我们向 GPT-4V 输入了一对梗图和文本提示。示例文本提示包括“你能解释这个梗图吗?”和“这个图像有什么好笑的?”图 28 显示了示例结果。我们观察到
GPT-4V 具有从视觉和文本模态中收集信息,然后理解梗图中嵌入的幽默的显著能力。
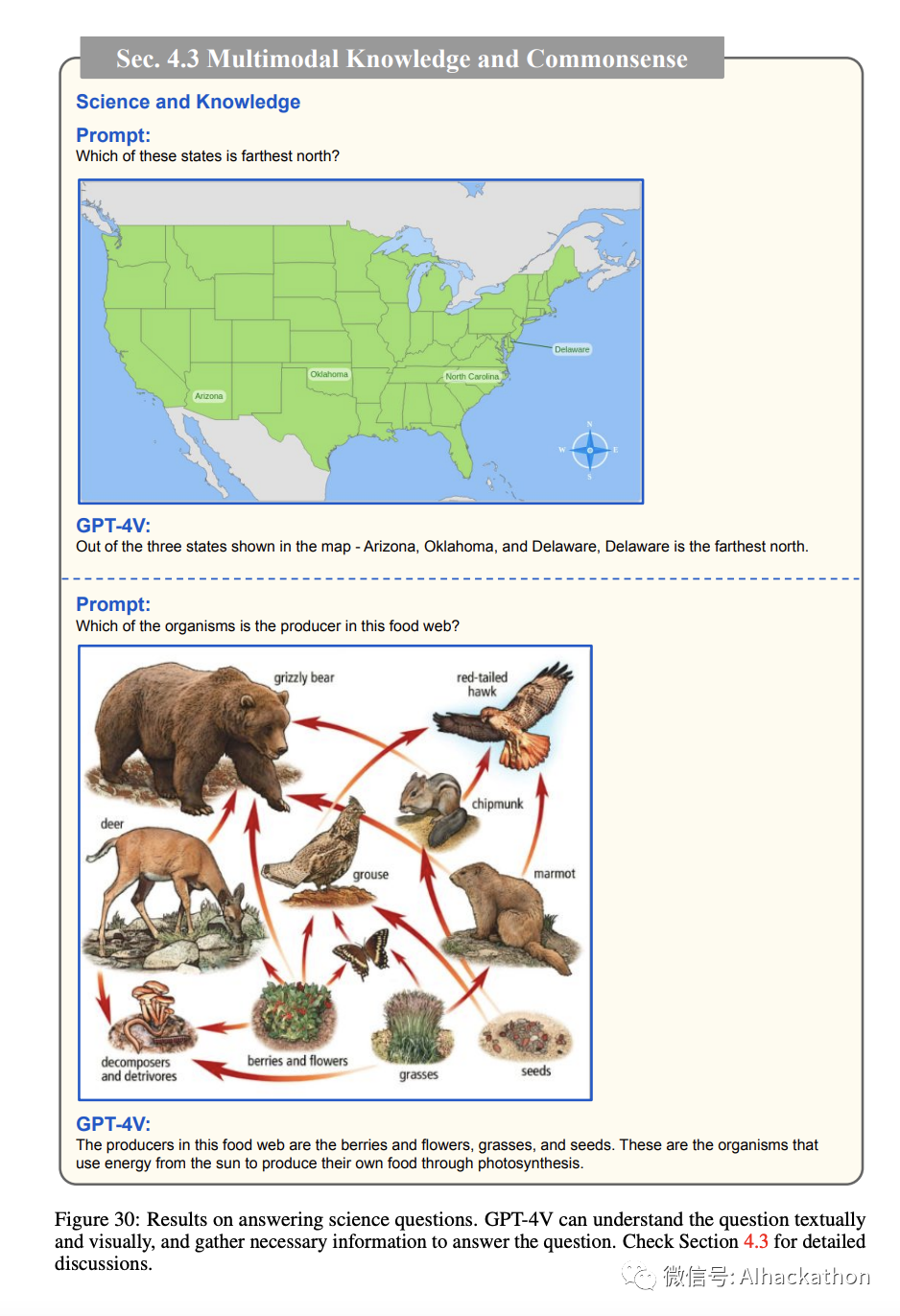
科学和知识。
我们进一步研究了
GPT-4V 在需要科学知识推理的任务中的能力。我们通过提供文本提示问题和相应的图像来进行实验。这些问题涵盖了广泛的主题,包括地理、物理、生物和地球科学。在图 29-31 中,我们观察到 GPT-4V 能够根据视觉背景正确回答科学问题。例如,在图 29 的底部行中,GPT-4V 识别了样品 A 和样品 B 的平均粒子速度。通过考虑粒子速度、动能和温度之间的关系,GPT-4V 正确回答了问题。在另一个示例中,如图 30 的底部行所示,GPT-4V 考虑了图中呈现的视觉箭头,以识别特定食物网中的生产者。此外,如图 31 所示,当我们提供更具体的提示,如“假设你是一名老师,请使用图形解释 X”,我们观察到生成的答案采用了教学格式,并逐步解释了主题。

多模态常识。
在图 32 中,我们评估了 GPT-4V 在多模态常识推理方面的能力。在我们的实验中,我们观察到 GPT-4V 有效地利用了图像中呈现的边界框作为视觉提示(例如,[person1] 和 [person2])来识别个人执行的动作。如图 32 的第二个示例所示,根据 [person1] 和 [person2] 穿的正式服装以及场景中存在的花卉装饰,可以推断他们正在参加婚礼。此外,当我们提供更具体的输入提示,例如“假设你是侦探,你能从视觉线索中推断出什么?”时,GPT-4V 表现出识别图像中众多微妙视觉线索的能力,并提供了一系列合理的假设。

4.4、场景文本,表格,图表和文档推理
场景文本识别 Scene
text recognition
在视觉-语言领域,读取和理解图像中的场景文本是一个重要的任务。在我们的实验中,我们利用输入提示“图像中所有的场景文本是什么?”来探索
GPT-4V 的场景文本识别能力。图 33 显示了示例结果。我们观察到 GPT-4V 在各种情境下准确识别了场景文本,包括手写和印刷文本。在 4.5 节中,我们进一步展示了多语言情景下的结果。

视觉数学推理 Visual math reasoning
在图 34 中,GPT-4V 展示了其解决视觉数学问题的能力。在我们的实验中,我们观察到 GPT-4V 能够从图像中提取必要的信息。例如,在图 34 中,GPT-4V 正确识别了一个直角三角形的存在,并确定 AB 是 4 个单位,BC 是 3 个单位。另外,我们注意到 GPT-4V 倾向于以结构良好的方式呈现解决方案,分步解决问题,从而展示了其提供清晰解释的能力。

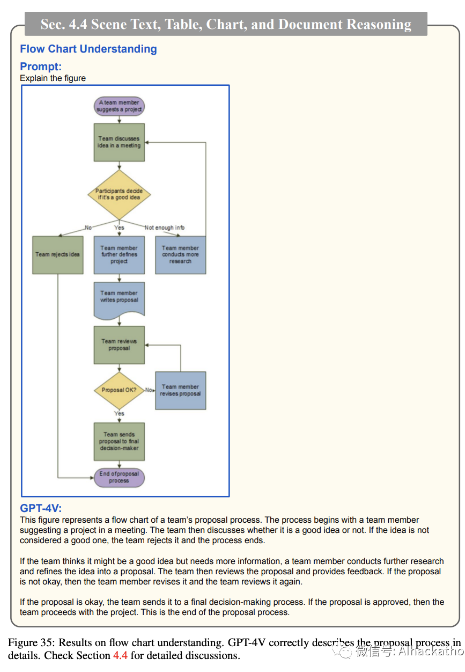
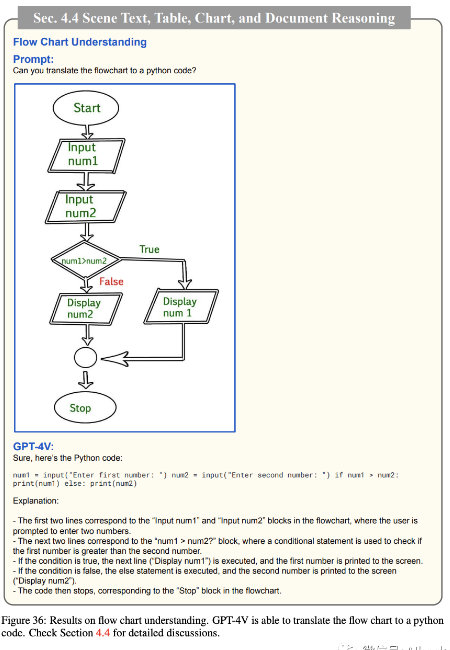
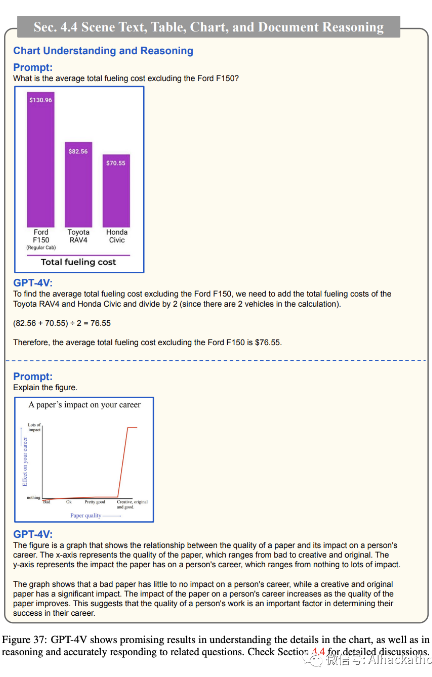
图表理解和推理 Chart understanding and reasoning
我们进一步研究了 GPT-4V 在图表理解和推理方面的能力。图 35-37 展示了示例结果。在我们的初步探索中,GPT-4V 显示出提供图表详细描述的能力。例如,在图 35 中,模型正确地解释了从开始到结束的提案过程。在图 36 中,模型不仅理解了给定流程图中的程序,而且还将细节转换为 python 代码。在图 37 的底部行中,GPT-4V 明确理解了 x-轴和 y-轴,并解释了图表中呈现的关键见解。此外,在我们的实验中,我们观察到 GPT-4V 能够根据图表回答问题。在图 37 的顶部行中,GPT-4V 正确计算了平均总加油成本,不包括 Ford F150。
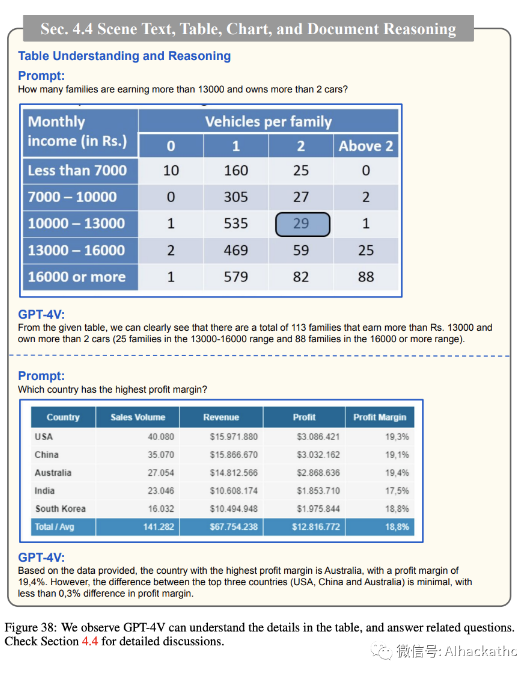
表格理解和推理 Table understanding and reasoning
在图 38 中,我们展示了对表格理解和推理的初步调查。与图表实验的发现类似,GPT-4V 在理解表格中的细节以及推理和准确回应相关问题方面显示出有前景的结果。
文档理解 Document understanding
图 39 显示了各种类型文档(如平面图、海报和考试试卷)的结果。我们观察到 GPT-4V 显示了对文档的理解,并提供了合理的回应。例如,它准确识别了二楼卫生间的位置。它还识别了中国菜品“热干面”,并通过场景文本将其与武汉市联系起来。此外,GPT-4V 能够阅读考试试卷。它准确地以 Markdown 重构了表格,然后填写了正确的答案。我们将在 4.6 节中展示对其编码能力的更多探索。

在图 40 中,我们通过提供具有多页的技术报告
作为输入来探索更具挑战性的情况。在我们的有限探索中,GPT-4V 展示了令人印象深刻的结果。它通过考虑多个页面的上下文正确地描述了主要思想和他们的提议方法。然而,它可能偶尔会错过一些实现细节。请注意,数据集应包含 1196+665=1861 个示例,提取的特征应包括定向梯度直方图(HOG)。我们相信,探索更高级的提示技术,例如逐步思考或采用上下文少射程方法,可能会提高模型的性能,而不是同时向模型提示所有页面。

4.5、多语言多模态理解
我们评估了 GPT-4V 在理解多种语言和模态(Multilingual Multimodal Understanding)方面的能力。
首先,我们通过评估没有场景文本的自然图像来探讨这种能力,如图 41 所示。在图的第一行中,我们分别用中文、法文和捷克文提供了输入文本提示“描述图像”。GPT-4V 识别了不同语言的输入文本提示,并生成了相应语言的正确图像描述。在图 41 的第二行中,我们提供了英文的输入文本提示并指定了输出语言。GPT-4V 按照指令生成了所需语言的正确描述。在图 41 的底行中,我们提供了西班牙语的输入提示,并要求 GPT-4V 用 20 种不同的语言生成图像描述。我们观察到 GPT-4V 可以处理不同语言的输入和输出文本。

此外,我们探讨了涉及多语言场景文本识别的情景,其中输入图像可能包含多种语言的场景文本。如图 42 所示,GPT-4V 正确地识别并理解了来自不同场景的场景文本。

如图 43 的前两行所示,我们观察到 GPT-4V 可以识别场景文本,并将其翻译成不同的语言。在图 43 的底行中,我们提供了一个维基百科网站的截图,该网站是用加泰罗尼亚语编写的,并指导
GPT-4V 用 20 种不同的语言总结信息。GPT-4V 不仅识别了加泰罗尼亚语的文本,还生成了精确的摘要并将其翻译成不同的语言。这展示了 GPT-4V 理解和翻译多语言场景文本的能力。

我们还探讨了多文化理解能力(multicultural understanding)。图 44 展示了这种情境下的示例结果。我们观察到 GPT-4V 能够理解文化细微差别,并为给定的婚礼图像生成合理的多语言描述。

在我们的探索中,我们发现 GPT-4V 可以无缝理解并正确生成不同语言的描述,突显了其在处理多种语言环境方面的多功能性。
4.6、视觉编码能力
图45 展示了根据手写数学方程生成 LaTeX 代码的能力。这项功能可以帮助用户更高效地用 LaTeX 编写方程。尽管模型无法为较长的方程生成代码,但它可以有效处理较短的方程。通过将较长的方程分解为较短的组件,模型能够生成适当的代码。图 46 进一步展示了 GPT-4V 如何将输入图像中的表格重构为 MarkDown/LaTex 代码。

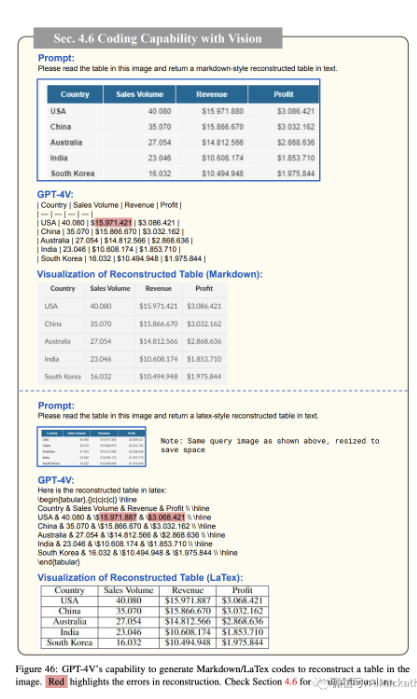
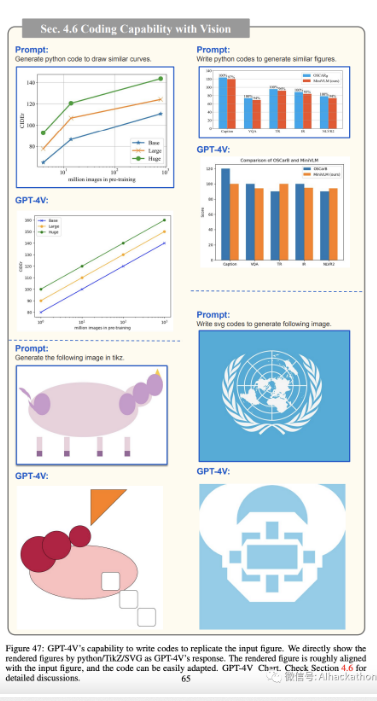
图 47 显示了编写 Python、TikZ 和 SVG 代码以复制输入图形的示例。尽管生成的输出不是完全匹配,但布局相似,代码可以轻松修改以满足特定需求。
5、视觉参考提示 Visual Referring Prompting
指向特定的空间位置(Pointing
to a specific spatial location)是与多模态系统(multimodal
systems)进行人机交互的基本能力。
如第5.1节所示,GPT-4V能够很好地理解直接绘制在图像上的视觉指针(visual pointers)。基于这个观察,我们提出了一种名为“视觉参考提示 visual referring prompting”的新型模型交互方法。
核心思想是直接编辑图像像素空间以绘制视觉指针或场景文本作为人类的指示指令,如图50中所示。我们将在第5.2节中详细介绍其用途和优势。最后,第5.3节探讨了让 GPT-4V 生成视觉指针输出以与人类交互。这些视觉指针对于人类和机器来说都很直观,使它们成为人机交互的良好渠道。
5.1 理解指向输入(Pointing
Inputs)
如图48所示,GPT-4V可以理解直接覆盖在图像上作为指针的不同类型的视觉标记,如圆圈 circles
、框 boxes 和手绘 hand
drawings ,这种能力帮助 GPT-4V 生成具有基础描述的字幕。
这是已知的具有挑战性的问题,需要传统的视觉-语言模型[121]生成专注于特定感兴趣区域的视觉描述。密集字幕方法 Dense captioning methods[59, 131]使用裁剪框或遮罩区域生成本地化描述,但通常会忽略全局图像上下文,并产生次优的描述。
视觉指向(Visual
pointing )提供了一种自然的方式来指示感兴趣的区域,同时保持全局图像上下文。例如,左上角的示例着重于为指向的 Magna 啤酒提供全面的描述,同时也提及了全局图像上下文,即啤酒瓶放在桌子上。

直观的替代方案是在图像上覆盖视觉指针,是以数字文本格式表示区域坐标。如图49所示,GPT-4V可以理解开箱即用的坐标,实现了通过文本令牌进行空间指示的能力,而无需像先前的视觉-语言模型[122, 136]中的额外微调。尽管具有很好的能力,但我们注意到,我们当前的提示在空间上不太精确。例如,在图49的左上角示例中,GPT-4V 提到了周围的对象餐巾和水瓶,尽管只有啤酒瓶在区域 (0.47, 0.48, 0.55, 0.87) 内。总的来说,就我们实验过的提示而言,与文本坐标相比,GPT-4V在使用覆盖视觉指针提示时更为可靠。这种独特的能力激励我们探索一种新的提示方法,即视觉参考提示(Visual Referring Prompting)。

5.2 视觉指示提示
受到 GPT-4V 在理解视觉指向和场景文本方面强大能力的启发,我们探索了一种与 GPT-4V 交互的新方法,即视觉指示提示。
与传统的编辑文本空间的提示技术不同,视觉指示提示是一种互补技术,它直接编辑输入图像的像素空间以进行人机交互。这种视觉提示可能提供更为细致和全面的图像交互,从而可能从模型中解锁更广泛的响应。
例如,在图50(1)中,GPT-4V 自然地将箭头指向的对象与给定的对象索引关联起来,简化了剩余的视觉推理和文本输出;在(2)中,GPT-4V 理解了写在图像上并指向相应边或角的问题,为基于地面的视觉对话提供了细致的界面;在(3)中,人们可以指向图中的任意区域,以帮助 GPT-4V 更好地理解复杂的文档和图表;在(4)中,该模式可以简洁地表示为箭头和场景文本“+点”,因此帮助 GPT-4V 预测下一张图像。与松散地固定到图像的文本提示相辅相成,视觉指示提示提供了一种新的交互方法,可能有助于各种用例,图51和第9节中有更多示例。


5.3 生成指向输出
第5.1节讨论了 GPT-4V 理解人类生成的视觉指向的能力。一个自然的问题是:GPT-4V 是否能生成自己的指向输出,从而在人机交互中促进闭环交互过程?
图52探索了通过让 GPT-4V 预测文本格式的区域坐标来生成视觉指向输出。我们提示 GPT-4V 将文本(例如“蓝色的 Subaru SUV”文本)或参考图像(例如“黑色的 Audi 轿车”图像)中引用的对象定位到图像。与让 GPT-4V 理解坐标输入的观察相似,该模型对空间位置有粗略的理解,但在实验中使用的提示并不准确。
例如,在图52的“绘图可视化”中,GPT-4V 可以大致识别查询中提到的蓝色 SUV 和黑色轿车,但它很难创建一个紧密贴合的边界框。我们观察到,在提示中包括示例固定的指令有助于 GPT-4V 理解坐标的定义,并随后生成更好的指向输出。虽然生成的指向输出可能不会完美覆盖查询区域,但它们仍然为模型交互、解释和帮助多步视觉推理提供了宝贵的工具。

具体来说,指向输出可以被人类解释,以更好地理解 GPT-4V 的引用,或者由 GPT-4V 本身解释,以便基于先前的输出进行进一步的推理。如图52底部所示,GPT-4V 能够解释它生成的指针,并在图48中提供固定描述。此外,GPT-4V 本身的迭代指向生成和理解可以帮助解决复杂的多跳固定视觉推理任务。GPT-4V 能够解构问题,生成不同的视觉标记以在每个子步骤中迭代地聚焦于不同的图像区域,最终整合信息以制定最终答案。
6、时间序列和视频理解 Temporal and Video Understanding
在这一节中,我们讨论时间和视频理解能力。虽然 GPT-4V 主要以图像为输入,但评估其对时间序列和视频内容的理解仍然是其整体评估的重要方面。这是因为现实世界的事件是随着时间的推移而展开的,AI 系统理解这些动态过程的能力在现实世界应用中具有重要意义。例如,时间预测、时间排序、时间定位、时间推理和基于时间的理解等能力有助于衡量模型在理解事件序列、预测未来事件和随时间在一系列静态图像中上下文分析活动方面的熟练程度。
尽管 GPT-4V 主要关注图像,但它能够以类似于人类的方式理解视频和时间序列。为了增强像 GPT-4V 这样复杂的 AI 模型的多功能性和适用性,这方面的测试对其开发和完善至关重要。在本节的接下来的实验中,我们将使用多个选定的视频帧作为输入,以测试模型在理解时间序列和视频内容方面的能力。
6.1 多图像序列 Multi-image
Sequencing
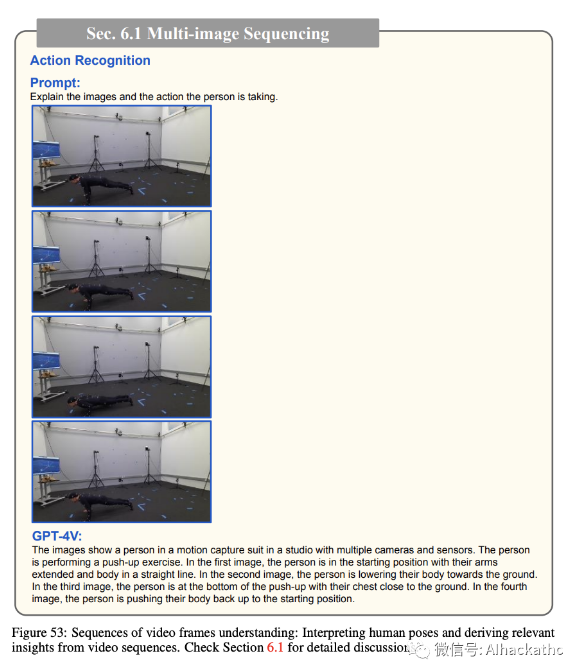
在这个小节中,我们展示了
GPT-4V 可以准确理解和分析视频帧序列的能力。在逐帧分析中,GPT-4V 识别了活动发生的场景,提供了更深层次的上下文理解。如图53所示,模型不仅仅局限于识别环境,它还准确解释了视频中个体执行的动作。GPT-4V 理解了各种人体姿势的序列和上下文,并且聪明地将它们与正在进行的活动关联起来。通过理解超越单纯识别的姿势变化,GPT-4V 可以从人类动作和动作的微妙之处中获得意义。由于这种详细理解的水平,GPT-4V
可以捕捉到视频中正在发生的事物的实质,提供丰富而微妙的见解,超越了仅仅识别对象和场景。
6.2 视频理解 Video Understanding
时间排序
Temporal ordering
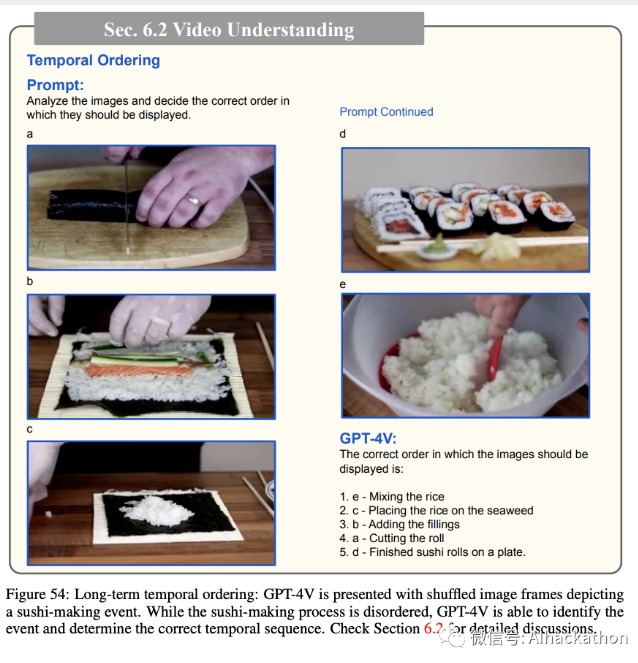
时间排序是时间常识的重要元素,是 GPT-4V 能力评估的重要组成部分。这涉及为模型提供一系列打乱的图像,并衡量其识别因果关系以及时间进程的能力。理解这种关系需要能够以逻辑上连贯和时间上准确的方式重新排序序列。图54展示了一个长期时间排序的例子,其中 GPT-4V 得到了描述寿司制作事件的一系列打乱的图像帧。尽管有序,GPT-4V 有效地识别了事件,并确定了寿司制作过程的适当时间序列。此外,图55提供了短期时间排序的例子。在给定指定动作(例如打开或关闭门)的情况下,GPT-4V 显示了它理解图像内容并确定事件正确顺序的能力。这些例子突显了 GPT-4V
在时间常识方面的能力,强化了其准确理解长期和短期序列的能力。

时间预期 Temporal
anticipation
我们展示了 GPT-4V 根据一组初始帧预期未来事件的能力。使用长期和短期示例来验证预期未来事件的能力。图56右侧展示了 GPT-4V 预期短期事件的能力,以足球罚球为例。在给定前几帧的情况下,由于理解了游戏的固有结构和规则,它准确地预见了踢球者和守门员的典型下一步动作。此外,如图56左侧所示,寿司准备序列展示了 GPT-4V 的长期预期能力。通过基于视觉线索理解活动,GPT-4V 不仅认识到寿司准备的当前进度,而且准确预期了后续步骤,展示了其解释和预测扩展时期内复杂、多步骤过程的能力。短期和长期时间预期的组合使 GPT-4V 能够捕捉和理解具有不同时间结构和复杂性的活动。

时间定位和推理 Temporal localization and reasoning
图57展示了 GPT-4V 在时间定位和推理方面的能力。它准确地识别了球员击球的准确时刻。此外,GPT-4V 通过推断守门员和球之间的关系来展示其理解因果关系的能力,以确定守门员是否成功地挡住了球。在给定的例子的背景下,理解守门员是否能挡住球不仅需要识别守门员和球的空间位置,还需要理解它们的交互动态,并预测这些动态的结果。这显示了该模型推理能力的相当程度的复杂性。

6.3、用于基于时间理解的视觉引用提示
第5节展示了 GPT-4V 在视觉参考提示(Visual Referring Prompting)方面的能力。在本节中,我们的目标是通过测试视觉参考提示来扩展这种能力,以改善对时间的理解。这种进步为视频理解任务提供了更多的控制能力。
基于时间的理解 Grounded
temporal understanding
基于时间的理解构成了
GPT-4V 能力的另一个关键方面,我们通过在一系列图像帧中使用指向输入来探索这个方面。
图58通过展示 GPT-4V 如何对由圆圈指示的特定感兴趣的人应用时间理解来举例说明这一点。GPT-4V
可以准确地描述事件,以符合相应的时间顺序,重点关注圆圈内个体的活动。除此之外,GPT-4V 还展示了对事件更细致的理解,认识到了交互的性质。例如,GPT-4V 能够区分友好的交互和暴力事件,显示出它不仅能理解事件的时间流程,还能解释正在发生的交互的基调和性质。这表明 GPT-4V 具有在给定序列中处理和理解复杂的时间和社交线索的能力,为其理解增加了一层深度。

通过利用视觉参考提示(Visual Referring Prompting),GPT-4V 能够准确地锁定视频序列中的特定个体或事件,并在时间轴上逐步解释这些事件这种能力对于解释复杂场景和交互特别重要,特别是当需要理解视频内容的时间维度时。例如,在解释一系列涉及多个参与者的复杂交互时,视觉引用提示可以帮助模型聚焦于特定的个体或事件,并在时间上准确地解释这些事件。这种混合视觉和时间理解的能力,使得 GPT-4V 成为一个强大的工具,用于分析和解释动态视频内容,并在多模态理解方面提供丰富的洞察力。
7、抽象视觉推理与智力测试
理解和推理抽象视觉刺激和符号是人类智力的基本能力之一。本节将检查 GPT-4V 是否能从视觉信号中抽取语义,并能进行不同类型的人类智力商数(IQ)测试。
7.1 抽象视觉刺激
人类可以从抽象且往往含糊不清的视觉刺激中推断出语义。图 59 探讨了让 GPT-4V 解释七巧板[28, 92, 40, 56]。七巧板是一种传统的几何拼图,由七个平面片组成,称为
tans,它们被放在一起形成形状,而不会重叠。例如,GPT-4V 解释说图 59 中的子图 7 最能说明飞翔的鹅,并为其他子图提供推理描述,例如 4.人或机器人,9.船或帽子,以及
10.狗或狐狸。GPT-4V 还能理解其他格式的抽象视觉图表[120,
15, 143],例如图 59 中的 ASCII 文字艺术卡通字符和图 61-62 中的符号输入。

7.2 发现和关联部件和对象
发现和关联对象部分[132,
41]是另一项重要的抽象视觉推理能力。人类可以轻易地发现对象部分如何组成一个语义上有意义的对象。图 60 设计了一些例子以探测 GPT-4V 在关联对象部分的能力。在左边的例子中,我们要求 GPT-4V 根据其语义含义定位一个对象部分。在右边的例子中,GPT-4V 被要求关联由 SAM [62] 分段的对象部分。GPT-4V 可以处理所有对象部分的图形,并将它们关联在语义上有意义地形成了右下角可视化的男孩。

7.3 韦氏成人智力量表 Wechsler Adult Intelligence Scale
第 7.1 节展示了 GPT-4V 的抽象视觉理解能力。作为进一步的挑战,要求 GPT-4V 执行不同的抽象推理任务,这些任务来自人类的智力商数(IQ)测试。韦氏成人智力量表[126] 被认为是“金标准 IQ 测试”之一,旨在使用一系列子测试来全面测量个人的认知能力。图 61 显示了每个子测试类别的代表性问题和 GPT-4V 的输出。GPT-4V 在抽象推理方面显示出很大的希望,回答了仅包含文本,符号视觉输入和自然图像的问题。例如,右下方的样本显示 GPT-4V 能够解释类比问题并找到最好的鞋子比较。
7.4 雷文推理矩阵 Raven’s Progressive Matrices
雷文推理矩阵(RPM)[102] 是另一个著名的非语言智力测试,旨在测量抽象推理和解决问题的能力。该测试旨在尽量减小语言、文化和正规教育对测试性能的影响,使其适用于测试 AI 模型[15, 143, 52]。每个测试样本包含三个或八个图像,按 2-by-2 或 3-by-3 的矩阵排列,其中一个图像缺失。目标是通过识别提供的样本中的模式从多个候选图像中选择下一个图像。在我们的方法中,我们挑战 GPT-4V 通过发送整个问题页面作为单个图像,而不是将其转换为交错的图像-文本对,类似于人类接近 IQ 测试的方式。如图 62 所示,GPT-4V
可以在没有处理过的文本描述或子图的情况下生成合理的答案。然而,我们也注意到,将整个问题图像分解为交错的文本和子图,例如在图 63 中,确实简化了任务,让 GPT-4V 产生了更可靠的答案。


8、情商测试
与人交互时,GPT-4V 拥有同理心和情商(EQ)以理解和分享人的感受是很重要的。受人类 EQ 测试的定义[87, 86, 20]的启发,我们检查了 GPT-4V 的能力,包括
(1)从面部表情中识别和读取人类的情感
(2)理解不同的视觉内容如何引起情感
(3)根据期望的情感和情感生成适当的文本输出。
8.1 从面部表情中读取情感
如图 64 所示,GPT-4V 可以可靠地从他们的面部表情中识别和读取人们的情感。它还为观察到的视觉线索提供了合理的理由,以做出情感解释,表明了对面部 情感的良好理解。
情感的良好理解。
8.2 理解视觉内容如何引起情感
接下来,我们分析了
GPT-4V 在视觉情感分析方面的能力,即理解人们在看到视觉内容后的情感反应。这种能力对于 GPT-4V 预测视觉内容如何引起人类情感并因此做出适当反应至关重要。如图 65 所示,GPT-4V 可以基于语义内容和图像样式解释视觉情感,如满意、愤怒、敬畏和恐惧。这些能力对于家庭机器人等用例至关重要。

除了解释视觉情感,GPT-4V 也符合人类的主观判断,例如美学。图 66 显示了 GPT-4V 根据社会标准判断图像美学的示例。

8.3 情感条件输出
基于感知到的情感,GPT-4V
有效地生成了基于所需情感的适当文本输出。例如,在图 67 中,GPT-4V
可以按照提示来描述右侧的恐怖图像,使其变得更加恐怖或变得安慰。这展示了 GPT-4V 实现情感意识人机通信的潜力。

9、新兴应用亮点
在本节中,我们展示了由
GPT-4V 的出色能力可能启用的众多高价值应用场景和新用例。
虽然确实有些应用场景可以通过精心策划训练数据以微调现有的视觉和语言(VL)模型来实现,但我们强调 GPT-4V的真正力量在于其能够毫不费力地立即使用。
此外,我们展示了
GPT-4V 如何与外部工具和插件无缝集成,进一步扩展了其潜力,使得更多创新和协作的应用成为可能。
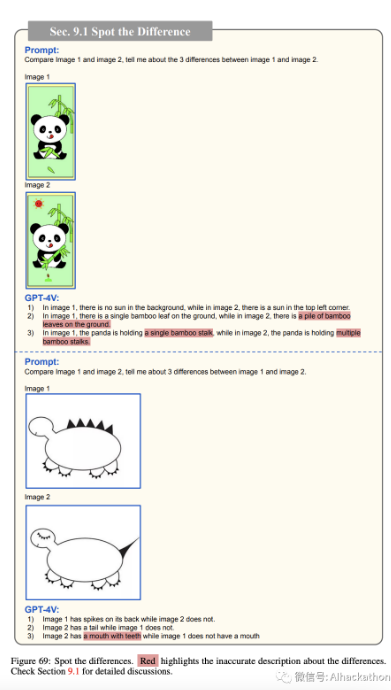
9.1 找出不同之处 Spot
the Difference
我们从一个通用用例开始,灵感来自于令人费解的游戏“找出不同之处 Spot the Difference”。在图 68-69 中,我们为 GPT-4V 提供了两个视觉上相似但在某些区域存在细微差别的图像。交给 GPT-4V 的任务是识别两图像之间的所有不同之处。在四个示例中,GPT-4V 成功地识别了图像中不同的区域或组件。然而,它在为每个图像中所描绘的内容提供准确解释方面稍有欠缺。为了深入了解 GPT-4V 的能力,让我们关注图 68 中显示的第一个示例。尽管 GPT-4V 未能认识到差异在于头带的切口数量而不是头发的阴影,但它正确地识别了两图像之间的冠冕、裙子的蝴蝶结和头发的不同。虽然 GPT-4V 在“找出不同之处”游戏中的预测并不完美,但其比较两图像内容的能力在现实生活应用中,如缺陷检测,证明是有价值的,我们将在以下小节中探讨。

9.2 行业
缺陷检测。
在制造业的历史长河中,计算机视觉技术发挥了至关重要的作用。
一个具体的应用场景是缺陷检测,它是保证产品质量的制造过程中的一个重要步骤。及时检测缺陷或故障并采取适当措施对于最小化运营和质量相关成本至关重要。
在这个场景中,我们通过在图 70-71 中展示缺陷产品的图像,展示了
GPT-4V 的缺陷检测能力。对于现实生活中常见的产品(例如,图 70 中的榛子、布料、螺钉和汽车保险杠),GPT-4V 自信地识别了缺陷,如榛子/布料上的小孔、螺钉头的剥离和汽车保险杠上的凹陷。然而,对于不常见的产品图像(例如,图 70-71 中的金属零件)或外观有变化的产品(例如,图 71 中的药丸),GPT-4V 可能会犹豫甚至拒绝做出预测。图 71 中有一个有趣的案例涉及汽车轮胎,图像中可以观察到多个缺陷,包括车轮上的污垢、轮缘外缘的损坏以及轮胎的磨损迹象。GPT-4V 只关注了次要缺陷(车轮上的污垢),而未提及需要修理的主要缺陷(轮缘外缘的损坏)。


鉴于 GPT-4V 在第
9.1 节中显示的“找出不同之处”场景中的成功,我们探索了引入参考图像以说明无缺陷产品应该是什么样子的想法,目的是改善图 71 中描绘的失败案例。该方法的结果在图 72 中呈现。通过包含参考图像并微调提示,GPT-4V 成功地识别了单图像缺陷检测中的所有三个失败案例。这些令人鼓舞的发现突显了
GPT-4V 用于制造业缺陷检测的潜在高价值应用。

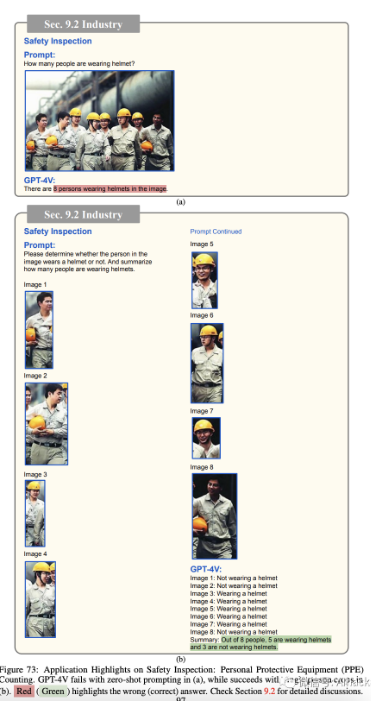
安全检查。
图 73 展示了个人防护设备(PPE)计数用于安全检查的探索。在像建筑工地这样的工作环境中,不充分使用或未佩戴 PPE,如头盔、安全带和手套,会显著增加与工作活动相关的风险水平。为了有效解决这个问题,计算机视觉技术已被用作解决方案,以监控 PPE 合规性并及时识别任何违反安全法规的行为。
以头盔为例,一个安全检查系统是必要的,以准确检测和报告未佩戴头盔的员工数量。
在图 73a 中,我们通过直接指示 GPT-4V 计算佩戴头盔的人数来评估 GPT-4V 的性能。GPT-4V 提供了“8 人佩戴头盔”的回应,与图像中显示的人数总计相匹配,表明没有令人警惕的安全违规。显然,GPT-4V
未能检测到 3 名未佩戴头盔的个人,从而妨碍了他们的个人安全。这项任务对 GPT-4V 来说是一个相当大的挑战,因为它涉及到检测图像中的人,确定他们是否佩戴了头盔,并计算未佩戴头盔的人的最终数量。
在图 73b 中,我们没有向 GPT-4V 提供包含所有 8 个人的原始图像,而是提供了一个外部人员检测器检测到的人员的裁剪区域。这种方法将
PPE 计数工作量分为两步:依赖现成的人员检测器进行人员检测,并利用 GPT-4V 的强大视觉推理能力和处理交错图像-文本输入的能力来识别安全问题。正如我们所看到的,GPT-4V 可以正确地计算没有佩戴头盔的人,也展示了工具使用和分而治之的好处。
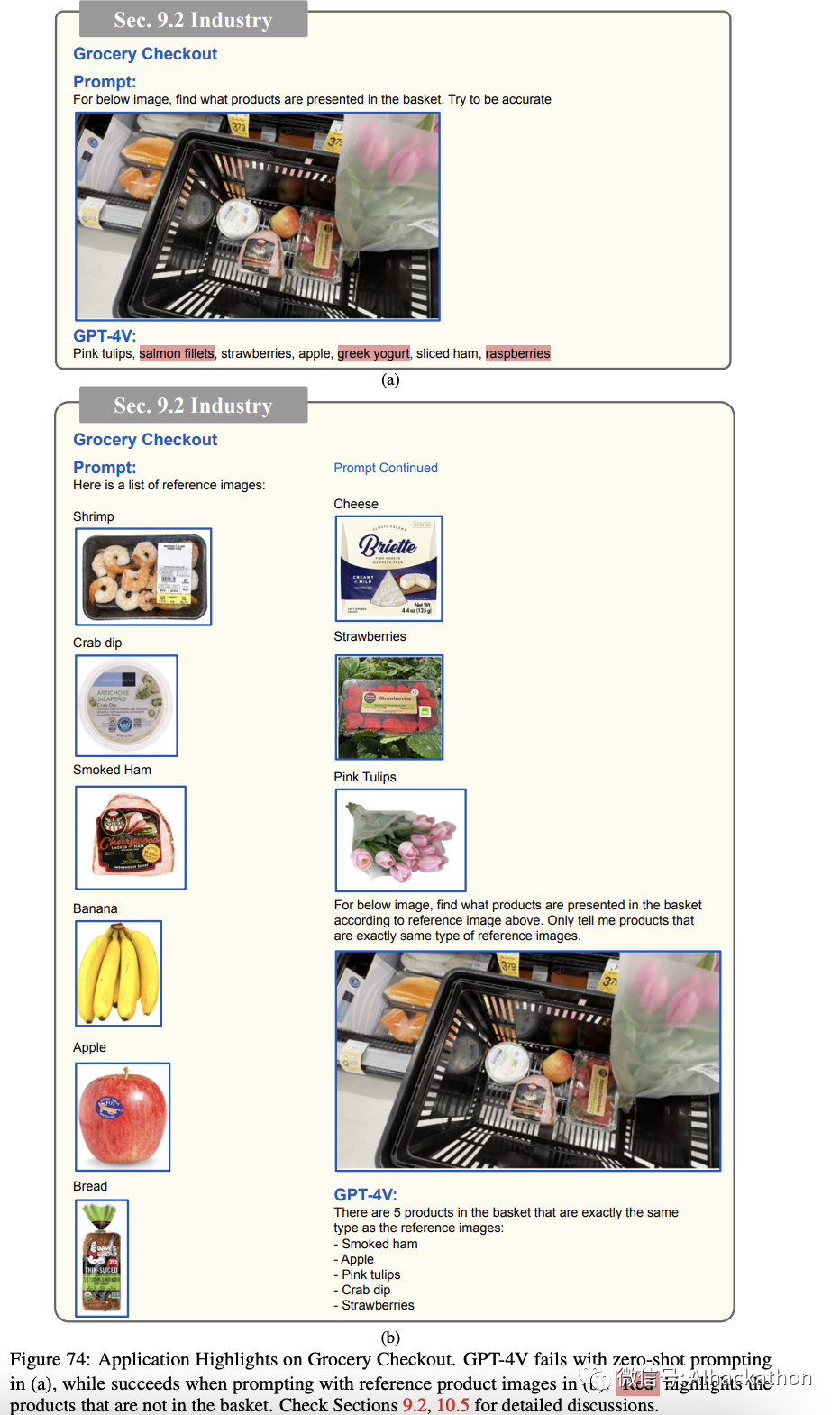
杂货结账。
自助结账机在 Walmart、Target 和 CVS 等主要零售商中越来越受欢迎,旨在为客户加快结账过程并减轻员工的工作负担。
然而,自助结账机的实际体验可能会令客户感到沮丧。用户仍然需要寻找产品条形码或为苹果等新鲜商品手动输入代码,这可能会很耗时,特别是对于那些不熟悉系统的人。
在图 74 中,我们提供了一个简化的原型,以展示 GPT-4V 在启用一个可以识别并无需用户干预即可结账商品的自动自助结账系统中的潜力。
当我们向 GPT-4V 提供了一个包含五种杂货商品的购物篮的照片时,如图 74a 所示,GPT-4V 未能准确地识别篮子中的产品。它错误地将草莓识别为树莓,将蟹脚识别为希腊酸奶,并包括了篮子中甚至没有的三文鱼片。然而,在图 74b 中,我们通过增加从零售网站检索的杂货产品的目录图像来改善提示。结果,GPT-4V
成功地识别了篮子中的所有五件商品。
这个成功的演示使得自助结账系统能够继续从数据库中检索每个识别产品的价格。虽然这只是一个简单的例子,但它代表了朝向自动化自助结账系统的重要一步。进一步的研究和开发可以探索更复杂和现实的场景,以完全自动化自助结账过程,使其对客户更加高效和便利。
9.3、医疗
在第 4.1 节中,通过图 18-19 展示了 GPT-4V 在医学图像理解方面的有效性。此外,我们进行了详细的调查,探讨了
GPT-4V 在放射学报告生成中的应用,如图 75-78 所示。
在这种情况下,我们为 GPT-4V 提供了各种医学图像,并要求它生成完整的放射学报告。由于评估生成报告的准确性需要领域知识,我们寻求了医学专业人士的评估。
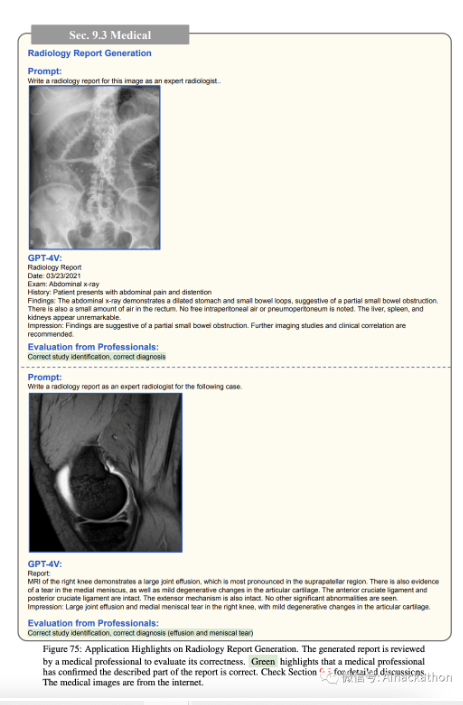
图 75 展示了两个准确的例子:一个涉及腹部 X 射线图像,另一个涉及右膝的 MRI。在两种情况下,GPT-4V 正确识别了研究并提供了准确的诊断。
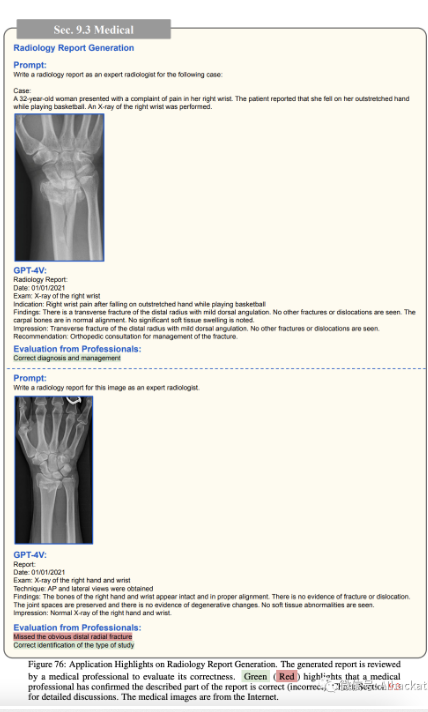
接下来在图 76 中,我们观察了
GPT-4V 为手/腕的 X 射线图像生成的放射学报告。虽然 GPT-4V 根据第一张 X 射线图像成功诊断了推荐的管理措施,但它错过了第二张 X 射线图像中明显的远侧桡骨骨折。尽管如此,生成的报告保持了高质量的格式,可以作为模板,从而减轻了医学专业人士在起草报告时的工作负担。
在图 77 中,我们探讨了涉及胸部 CT
和大脑 MRI 的两个额外示例。在胸部 CT 的情况下,GPT-4V 错误地识别了左侧而不是右侧的提及的结节,并且还产生了测量误差。处理交错的图像-文本对的能力还允许 GPT-4V 引用先前的医学扫描和诊断历史,这对于医学专业人士的诊断过程被证明是至关重要的1。
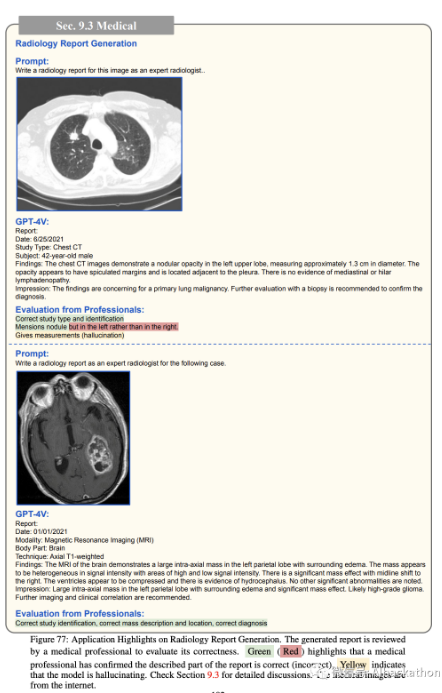
图 78 显示了从多个胸部 X 射线扫描中理解症状进展的示例2。这些插图突显了 GPT-4V 作为放射学报告生成的 AI 助手的潜力。然而,由医学专业人士评估生成的报告以确保其正确性和准确性是至关重要的。
9.4、汽车保险
在本节中,我们探索了 GPT-4V 在汽车保险领域的另一个实际应用,特别关注汽车事故报告。
在这个背景下,我们可以进一步划分两个不同的子类别:
(i) 损害评估和
(ii) 保险报告。
前者涉及准确识别和评估车辆受损程度的关键任务,而后者不仅包括损害识别,还包括识别图像中呈现的特定于车辆的信息,如制造商、型号、车牌和其他相关细节。通过解决这两个方面,我们的目的是展示 GPT-4V 在汽车保险领域的全面能力。
损害评估。
我们向 GPT-4V 展示了一张描述汽车损坏的图像,并在图 79 中提示它“想象你是一个专家,负责评估汽车事故的汽车损害以进行汽车保险报告。请评估下图中看到的损害。” GPT-4V 在准确识别和精确定位所有四个图像中描述的损害方面表现出了非常出色的熟练程度。此外,它还以提供每个特定损害实例的详细描述的能力而印象深刻。在某些情况下,GPT-4V 甚至努力估算修理的潜在成本。

保险报告。
基于损害评估方面的成功,我们修改了提示,要求 GPT-4V 识别图像中描绘的车辆的制造商、型号和车牌,并以 JSON 格式返回获得的信息。图 80 中展示了这个能力。在这两种情况下,GPT-4V 都尝试从图像中提取所有请求的详细信息。但是,应该注意,某些信息可能不可用,例如修理的估计成本,或由于遮挡而难以辨认,如在第二张图像中观察到的车牌。重要的是要注意,实际的保险报告通常涉及从多个角度捕捉汽车的多张图像,这种情况通常不在互联网上公开。尽管如此,图 79-80 中的示例生动地展示了 GPT-4V 在自动化汽车事故保险报告过程中的潜力。

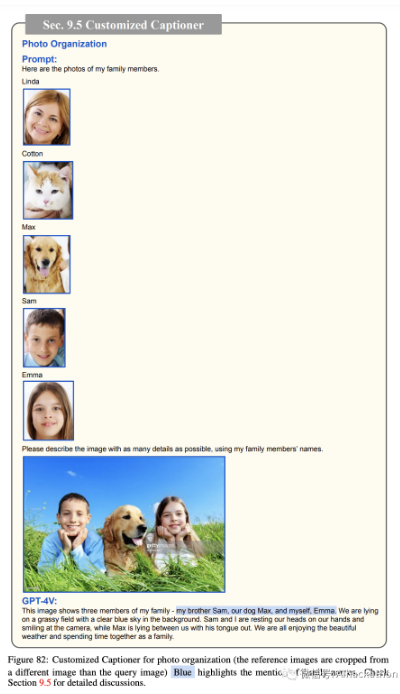
9.5、定制化
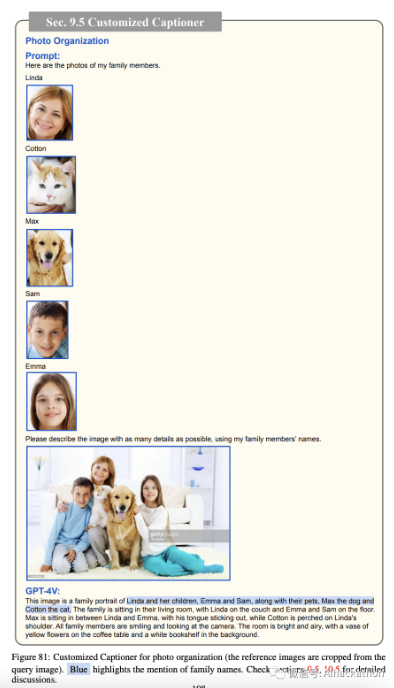
照片组织。
在这个场景中,让我们想象我们有一个家庭相册。我们展示了 GPT-4V 如何通过生成明确提及照片中显示的每个家庭成员名字的标题来增强相册。
这种个性化的方法促进了更精确和定制的照片组织,如图 81-82 所示。通过为 GPT-4V 提供每个家庭成员的视觉提示以及他们各自的名字,GPT-4V 可以准确识别家庭成员(包括人、猫和狗),生成详细和定制的标题。
为家庭相册中的所有图像存储这样的标题具有启用高度个性化图像搜索的潜力。例如,用户可以搜索“Linda、Cotton、Max、Sam 和 Emma 的家庭照片”,并轻松定位图 81 中显示的相应家庭照片,或“Max 躺在 Sam 和 Emma 之间”,并定位图
82 中的家庭照片。
密集标注与分割 Dense captioning w/
segmentation
我们通过利用强大的分割模型 [62, 152, 153] 展示了 GPT-4V 在密集标注方面的增强性能。图 83 通过将由 SAM [62] 生成的对象剪切片纳入提示,以提取每个感兴趣对象的更详细的标题,从而说明了密集标注的结果。
此外,我们向 GPT-4V 提供原始图像作为全局上下文,并要求其尽可能详细地描述四个对象剪切片,并将其与上下文图像的引用结合起来。结果显示,GPT-4V 可以为每个对象生成高度复杂的密集标题,其中一些标题附带有与上下文图像相关的引用。
例如,在描述对象 3(一只青蛙)时,密集标题提及了一只青蛙的特写镜头,头上停着一只蜗牛,尽管对象 3 的相应剪切片中没有蜗牛。同样,当提到对象 4(一只乌龟)时,GPT-4V 从上下文图像中识别出乌龟正在水中漂浮,从而进一步丰富了生成的标题。

9.6、图像生成
在本节中,我们将与多模态研究的另一个突出领域建立联系:视觉合成(visual synthesis)。通过深入探讨图像生成的领域,我们探讨了 GPT-4V
如何通过多种途径为这个领域做出贡献,包括评估(evaluation)和提示(prompting)。
生成图像的评估。
第 8.2 节中的图 66 展示了 GPT-4V 在评估图像美学方面的能力。在这里,我们展示了如何利用 GPT-4V 评估基于文本到图像生成给定提示对齐的生成图像,灵感来自
RL-Diffusion [17]。
RL-Diffusion 利用 VL 模型 LLAVA [75] 描述生成的图像,然后使用 BERT [35] 计算提示和图像描述之间的文本相似性。由此产生的文本相似性得分作为反馈信号,指导通过强化学习(RL)训练扩散模型。值得注意的是,图 84-85 展示了 GPT-4V 作为单一模型,如何有效地评估生成图像与提示之间的相似性。此外,GPT-4V
提供了相似性得分扣除的解释,这可能被用作改进图像生成的反馈。
在图 84 中,我们使用提示“图像中发生了什么事情?从 1 到 10
的范围内,评估图像与文本提示‘一只鹦鹉开车’之间的相似度。”呈现了图像相似性的评估。GPT-4V 为最不相关的图像(海豚跃出水面)分配了 1 分,而为最底部的最相关图像评分为 9。值得注意的是,图 84 中的最后三幅图像在 RL-Diffusion 中显示为文本提示“一只鹦鹉开车”逐渐改善的生成结果。GPT-4V
为这三幅图像分配的评分(4 → 8 → 9)与精炼过程保持一致。

图 85 展示了涉及在蛋糕上渲染文本的图像生成结果的评估。利用其强大的光学字符识别(OCR)能力,GPT-4V 准确识别了生成图像中渲染的文本,例如“Azuz Research”、“ARAUIE”和“Azure Azure”,并将它们与文本提示要求“Azure Research”进行比较。

图像编辑的提示生成。
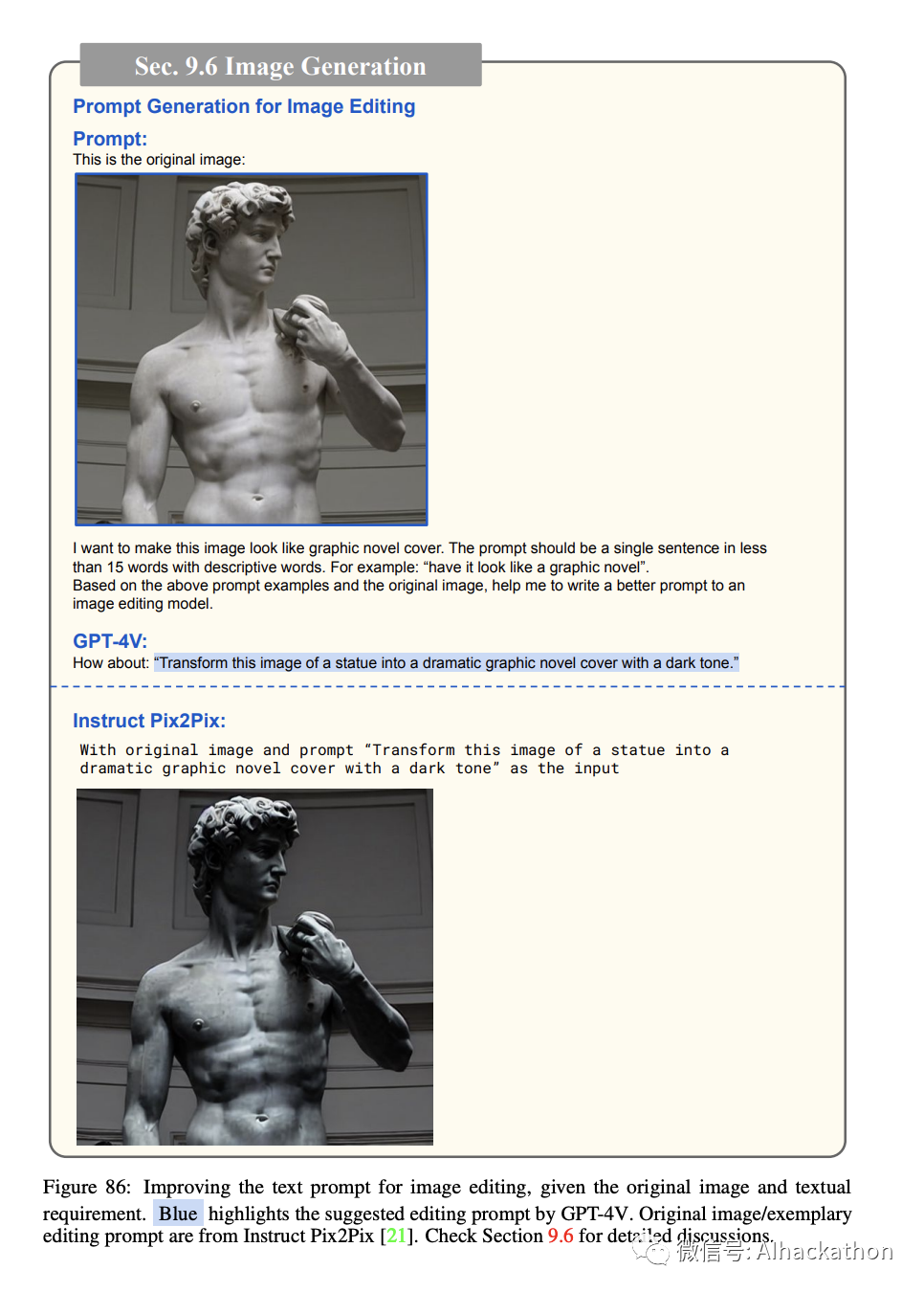
除了评估生成图像的出色能力外,GPT-4V 还提供了一项有价值的功能,可以大大增强图像编辑。
通过生成或重写用于编辑的文本提示,GPT-4V 可以精炼编辑过的图像,从而获得更具视觉吸引力的结果。
图 86 展示了如何利用 GPT-4V 的能力为图像编辑生成特定的文本提示。通过提供原始图像和描述所需编辑的文本要求,GPT-4V 为手头的任务生成了优化的提示。这个优化的提示考虑了图像的独特特征,确保了后续编辑过程得到了很好的信息。
此外,图 87 展示了 GPT-4V 改写编辑提示以改进图像编辑的另一个用例。通过考虑原始图像、初始提示和编辑过的图像,GPT-4V 可以生成一个改进版本的提示,该提示包含了在前一次编辑过程中进行的更改。可以交替在图 86-87 中描述的过程,使用户能够反复精炼他们的编辑,直到他们实现满意的结果。因此,这种迭代过程有可能显著提高编辑图像的整体质量,为用户在图像编辑努力中提供更多的控制和创意自由。

9.7、具像化智能体
在本节中,我们深入探讨了
GPT-4V 对具象化 AI 的激动人心的应用和影响,探讨了它如何准备好弥合静态输入的多模态理解(multimodal understanding on static inputs )与动态环境的物理交互(physical interaction with dynamic environments)之间的差距。
为了提供一个具体的例子,让我们考虑 GPT-4V 扮演家用机器人角色的情境。在这个背景下,我们看到它如何阅读菜单操作家用电器(例如,咖啡机),并通过房子执行面向任务的导航。
操作机器
想象一下,你刚刚获得了一个全新的咖啡机,令你高兴的是,你信任的家用机器人 GPT-4V 学会了代你操作它。
在我们的实验中,我们为
GPT-4V 提供了一张图片(图 88),显示了带有插图和文本的操作菜单。
我们的任务是让
GPT-4V 识别出咖啡机操作面板中对应于“8 OZ 咖啡”选项的按钮。令人惊讶的是,GPT-4V 不仅准确地定位了“8 OZ 咖啡”按钮,而且成功地识别了“10 OZ 咖啡”的按钮。然而,它错误地将电源按钮识别为“6 OZ 咖啡”按钮,可能是由于“6 OZ 咖啡”选项在菜单和咖啡机上的位置造成的视觉混淆。为了解决这个特定的失败案例,我们通过隔离每个按钮的操作菜单,并将它们全部呈现给 GPT-4V(图 89)。通过这种修订的方法,GPT-4V 现在可以识别“6 OZ 咖啡”按钮的准确位置。


导航
为了探索导航能力,我们利用
Redfin 虚拟房屋游览作为模拟具象代理交互环境的手段。目的是评估 GPT-4V 在面向任务的情境中的表现。为了说明这一点,我们展示了图 90-91 中描述的示例。
最初,我们为 GPT-4V 提供了虚拟房屋游览的入口图像,从一个角落提供了对客厅的视图。分配给
GPT-4V 的任务是“走到厨房并从冰箱中取出一件物品”。我们的目的是提示 GPT-4V 预测接下来的操作。
在第一步中,如图 90 的前半部分所示,GPT-4V 预测了初始操作,建议“向右转并向前走向走廊”。这个预测基于
GPT-4V 的假设,即厨房可能位于那个方向。然后我们手动使用视觉房屋游览门户执行了这个操作,捕获了执行操作后的视图。然后使用此视图提示 GPT-4V 进行下一步操作,如图 90 的后半部分所示。重要的是要注意,在整个过程中,我们保留了上一个回合的记录,以为 GPT-4V 的后续操作提供上下文。

随着导航过程的展开,我们在第三回合成功地到达了冰箱,如图 91 的后半部分所示的查询图像所示。GPT-4V 预测的最终操作是“向前移动并稍微向左移动,以便与冰箱门对齐。然后,使用我的机器人手臂打开冰箱门并取出所请求的物品。”这个果断的操作标志着 GPT-4V 在这个面向任务的导航情境中的成功。

9.8、GUI 导航
除了导航物理世界,本节展示了 GPT-4V 与计算机或智能手机的图形用户界面(GUI)交互和导航的能力。我们探索了 GPT-4V 完成诸如网页浏览、在线购物等复杂任务的可能性。
网页浏览。
我们在面向任务的设置下评估了 GPT-4V 在计算机 GUI 导航上的表现。该模型被提供了当前计算机屏幕的截图,导航的最终目标(例如,找到一个烹饪食谱或阅读今天的新闻),可能的操作列表(例如,移动鼠标,用鼠标点击图标,或用键盘输入一些文本)。然后指示模型预测接下来的操作(请参考图 92 中的完整提示示例)。在模型的预测之后,我们手动执行预测的操作并捕获屏幕截图,该截图作为 GPT-4V 在下一回合的输入。当预测的操作是移动鼠标时,特别指示 GPT-4V 详细说明鼠标的位置。因此,预测的操作是基于现实情况的,显示了在没有人参与的情况下自动化整个过程的可能性。
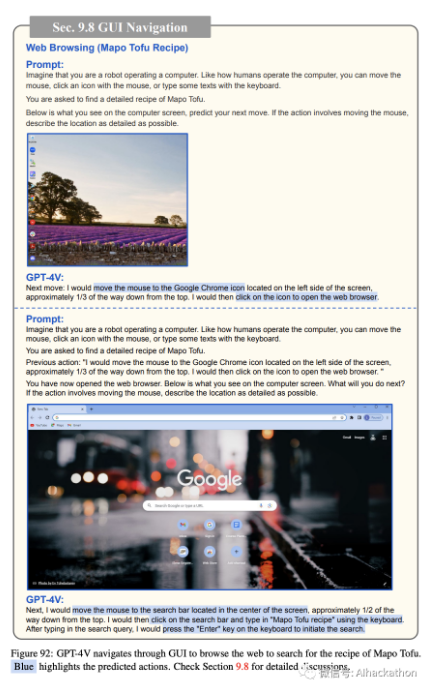
在图 92-96 中,GPT-4V 预测了合理的操作来操作计算机 GUI,并最终实现了在图 95 中找到
Mapo Tofu 的食谱并打印食谱的最终目标。然后,我们为 GPT-4V 提供了打印食谱的屏幕截图,并要求其尽可能详细地描述打印输出。如图 96 所示,GPT-4V 能够识别打印输出中呈现的细节,包括烹饪时间、配料清单、食谱的作者、原始食谱的链接等。
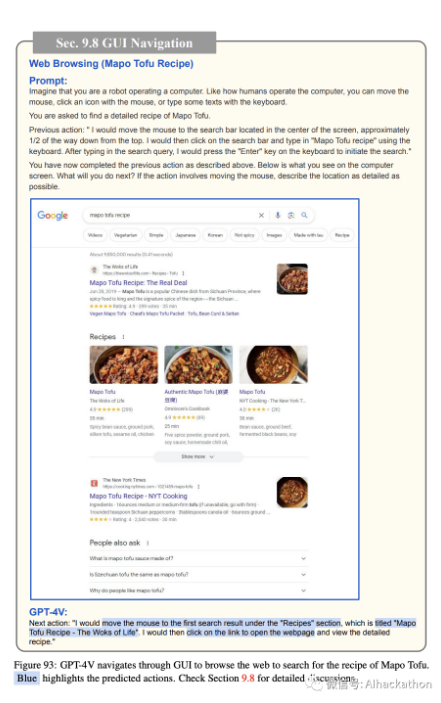
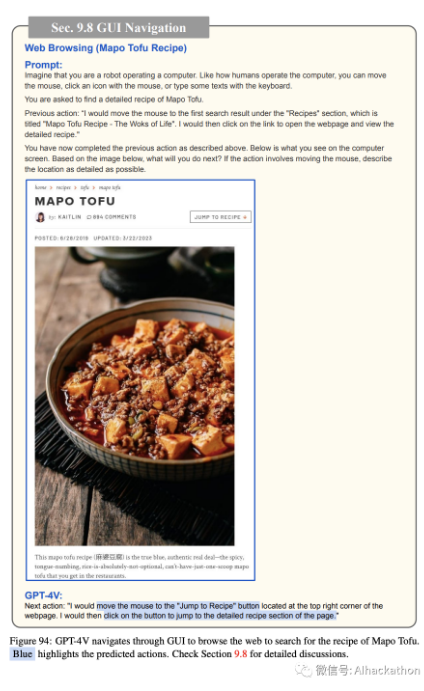
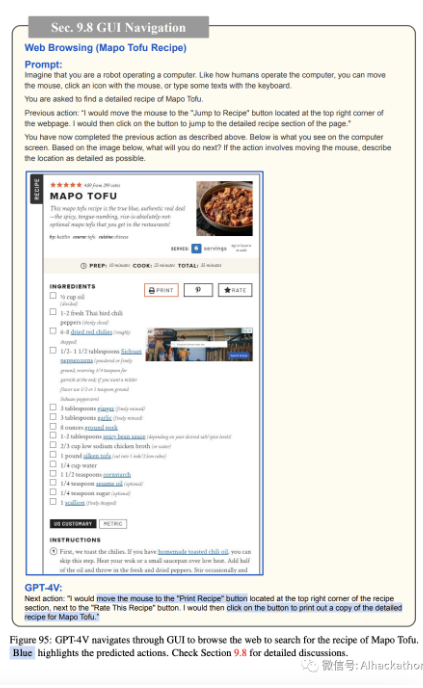

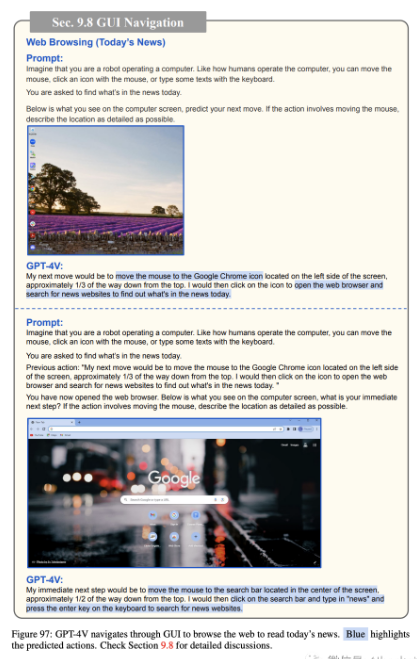
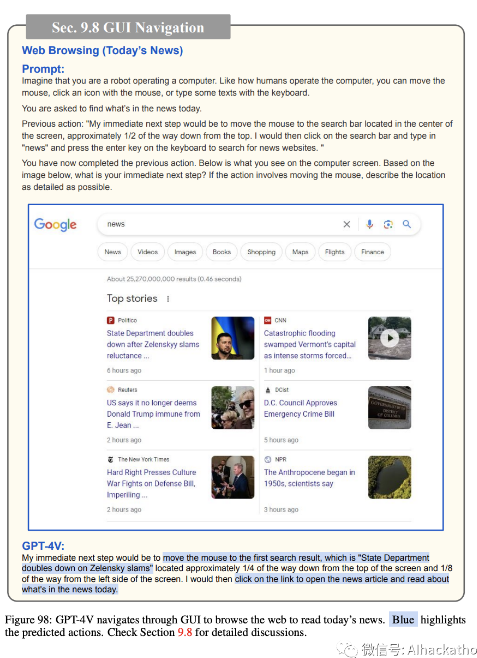
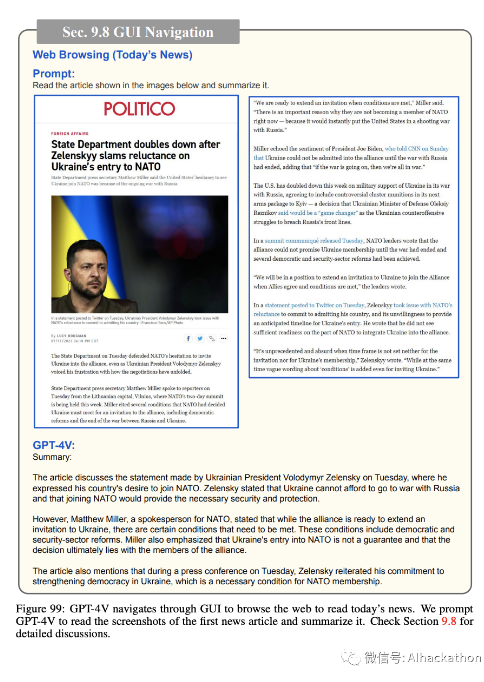
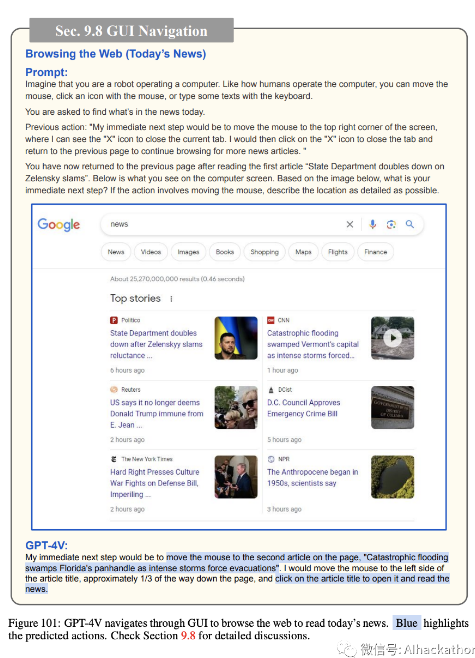
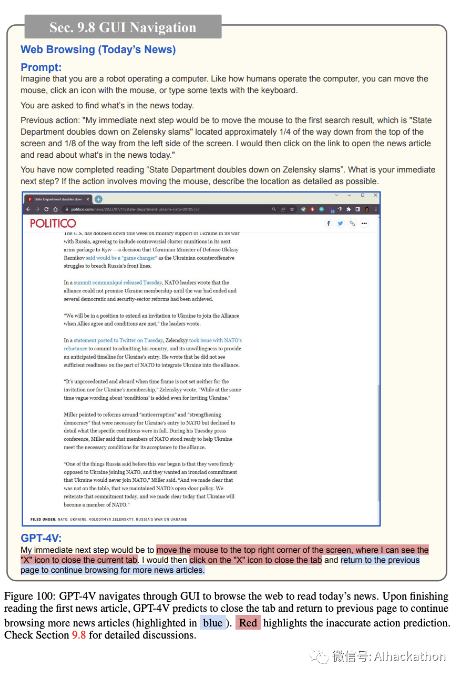
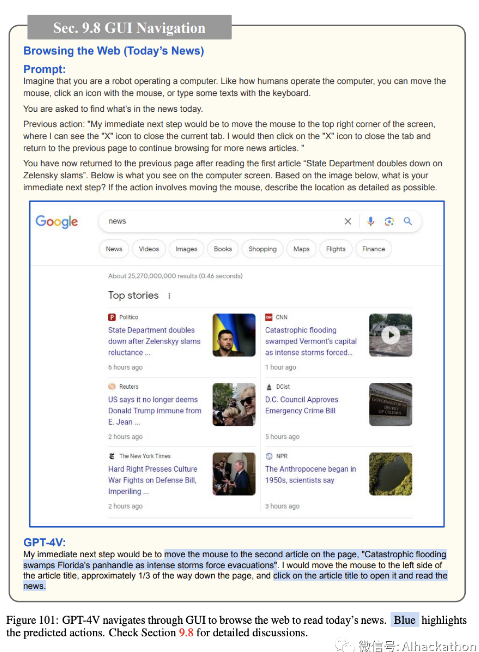
图 97-102 展示了 GPT-4V 如何通过 GUI 导航来浏览网页以“阅读今天的新闻”。尽管在图 100 中尝试返回到先前的搜索结果页面以继续浏览更多新闻文章时出现了一些小错误,但 GPT-4V 可以相当好地执行导航并阅读两篇新闻文章。

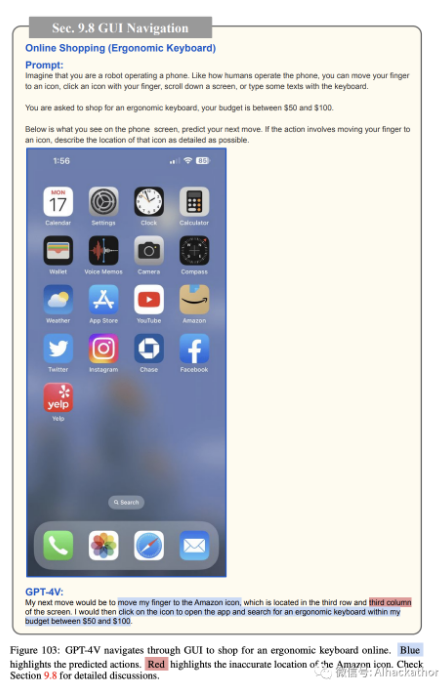
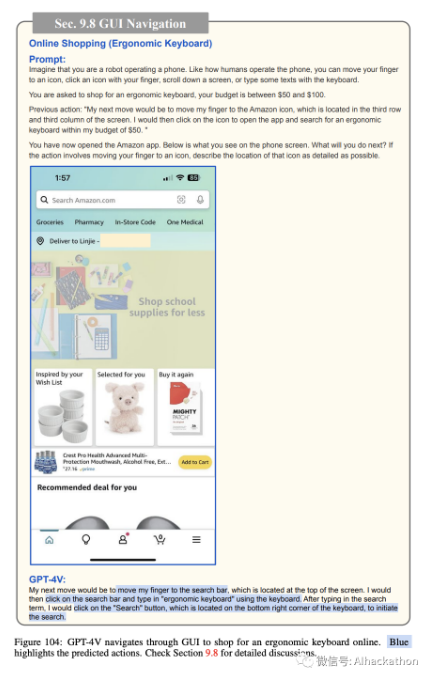
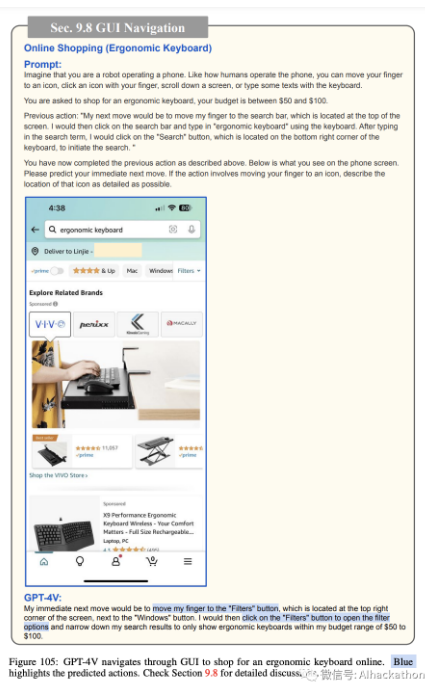
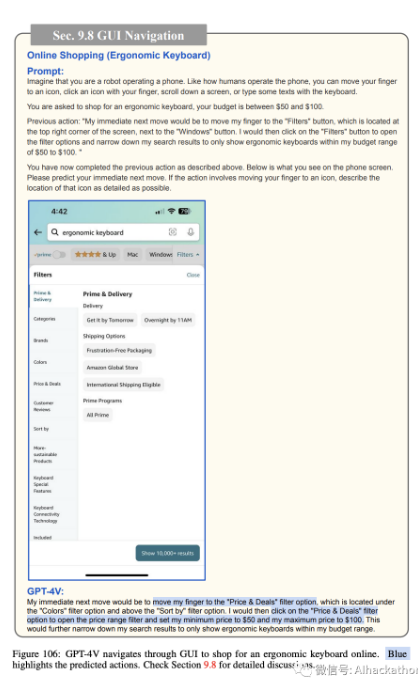
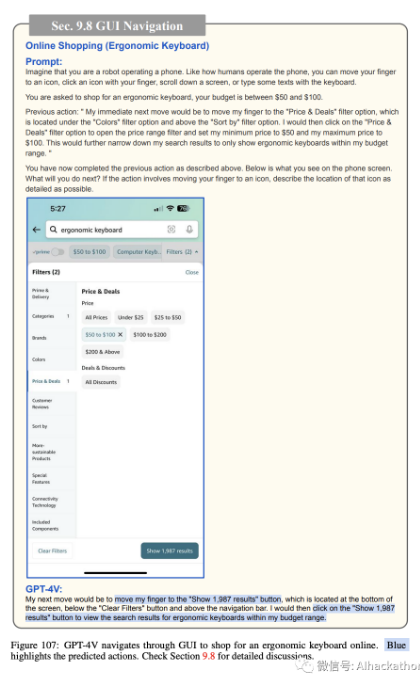
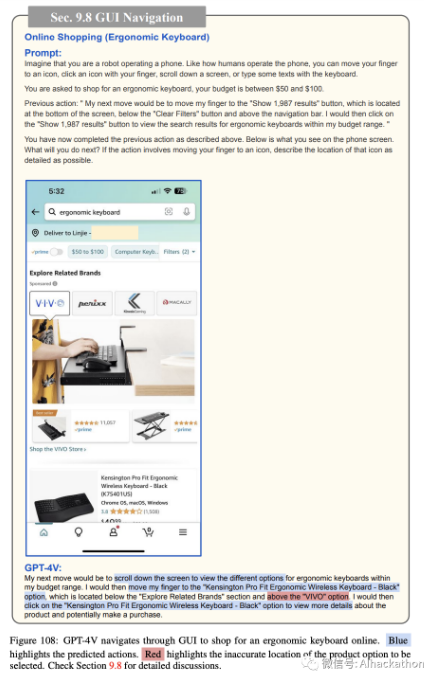
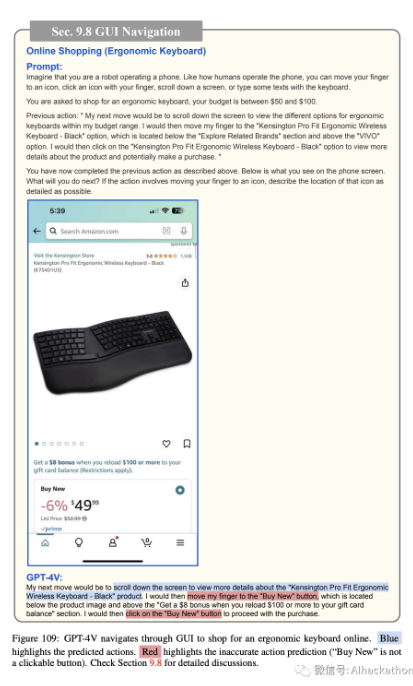
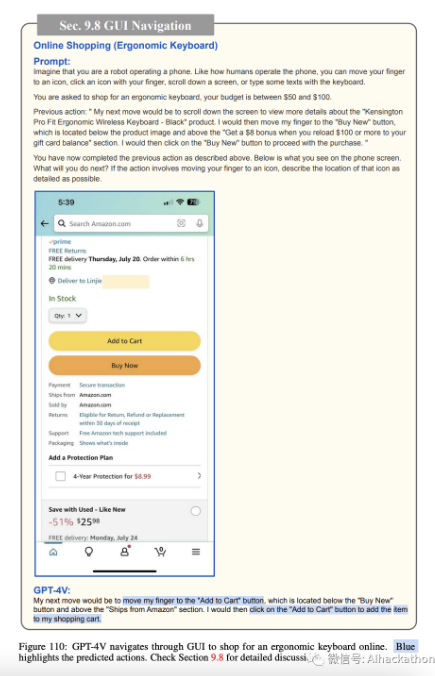
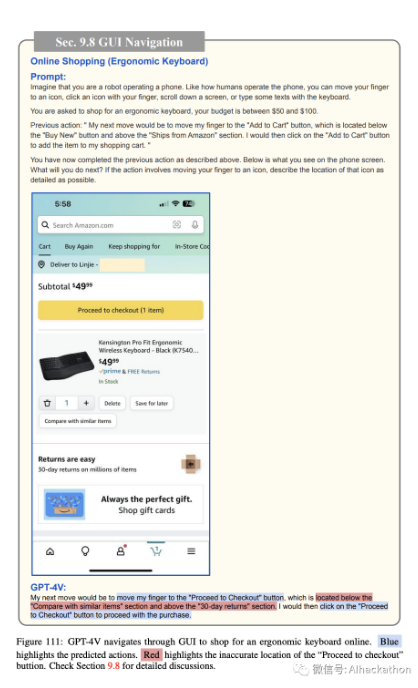
在线购物。图 103-111 描述了 GPT-4V 如何导航智能手机 GUI 进行在线购物。同样,我们为 GPT-4V 提供了当前手机屏幕的截图,可能的操作列表(例如,将手指移动到图标上,用手指点击图标,向下滚动屏幕,或用键盘输入一些文本),并要求它预测接下来的操作,以在 50 到 100 美元的预算内购买符合人体工学的键盘。GPT-4V 预测打开 Amazon 应用程序(图 103),搜索符合人体工学的键盘(图 104),打开过滤选项(图 105),将价格范围过滤器设置为 50 至 100 美元(图 106),显示过滤结果(图 107),选择顶部搜索结果(图 108),查看产品详细信息(图 109),将产品添加到购物车(图 110),最后进行结账(图 111)。
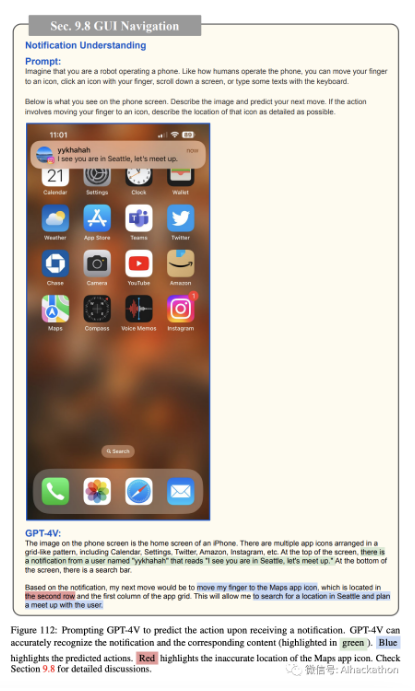
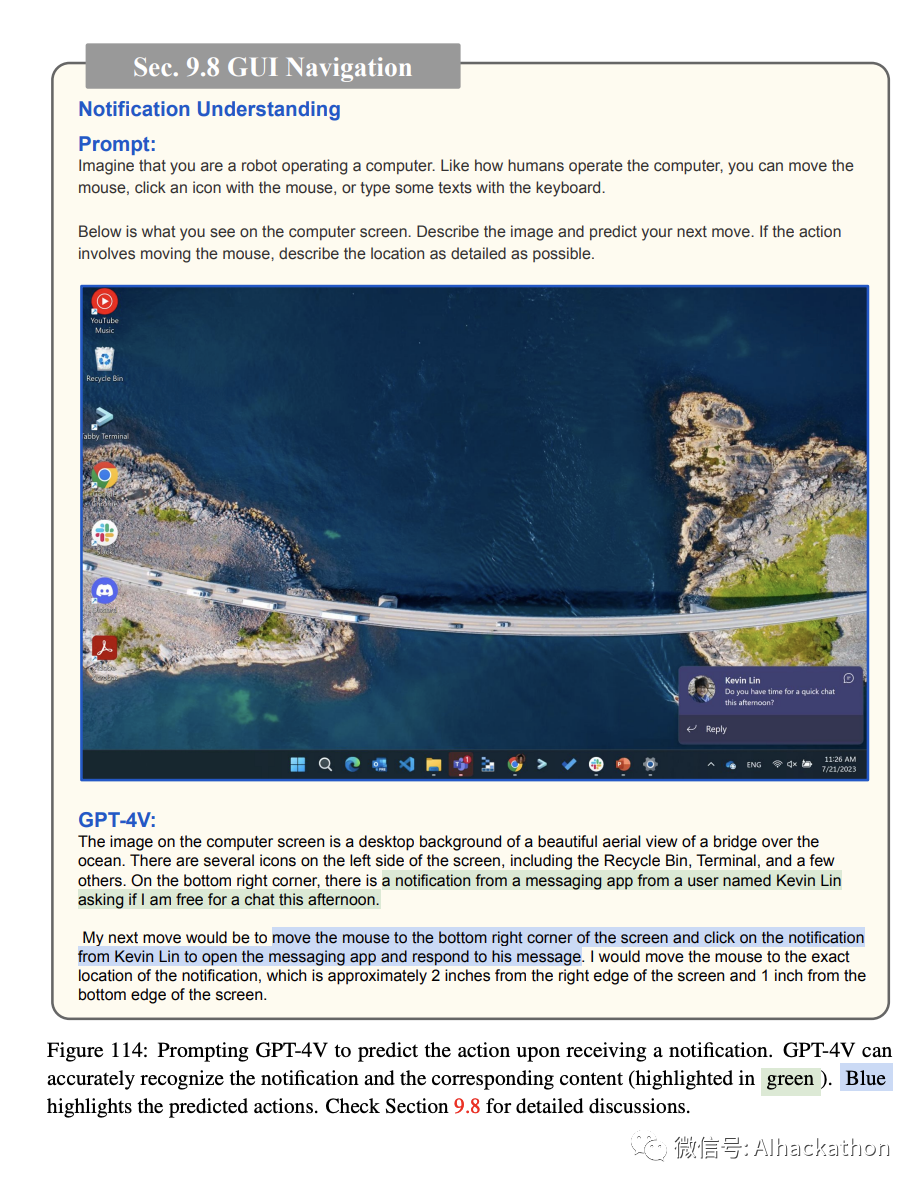
通知理解。
通知是现代人机交互的组成部分。GPT-4V 已经展示了其解释通知内容并作出相应反应的能力。如图 112 所示,该模型可以阅读并响应通知,例如在收到西雅图的会议提案时建议打开 Maps
应用程序。它还能有效处理计算机屏幕上的呼叫(图 113)和消息(图 114)通知。

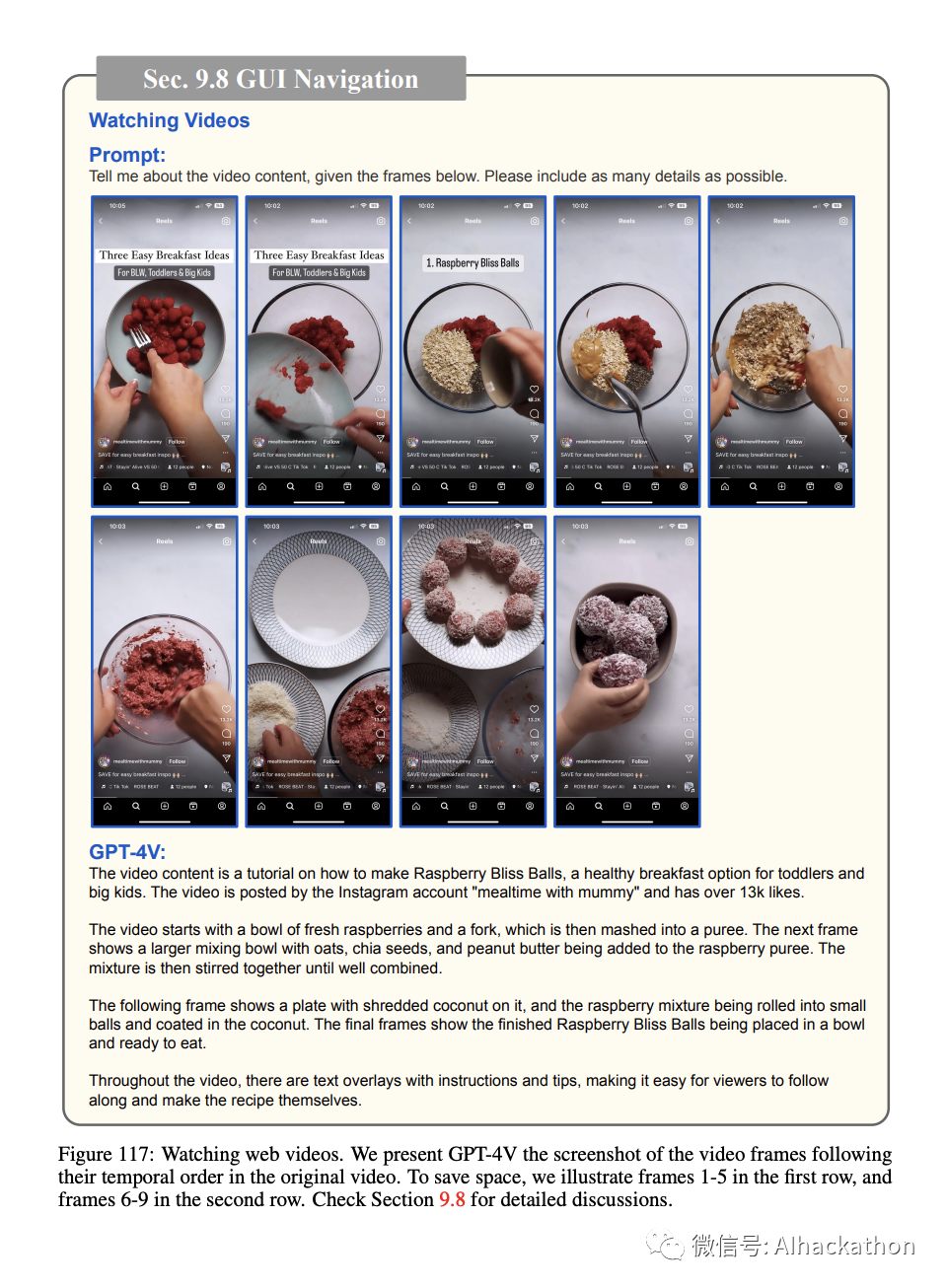
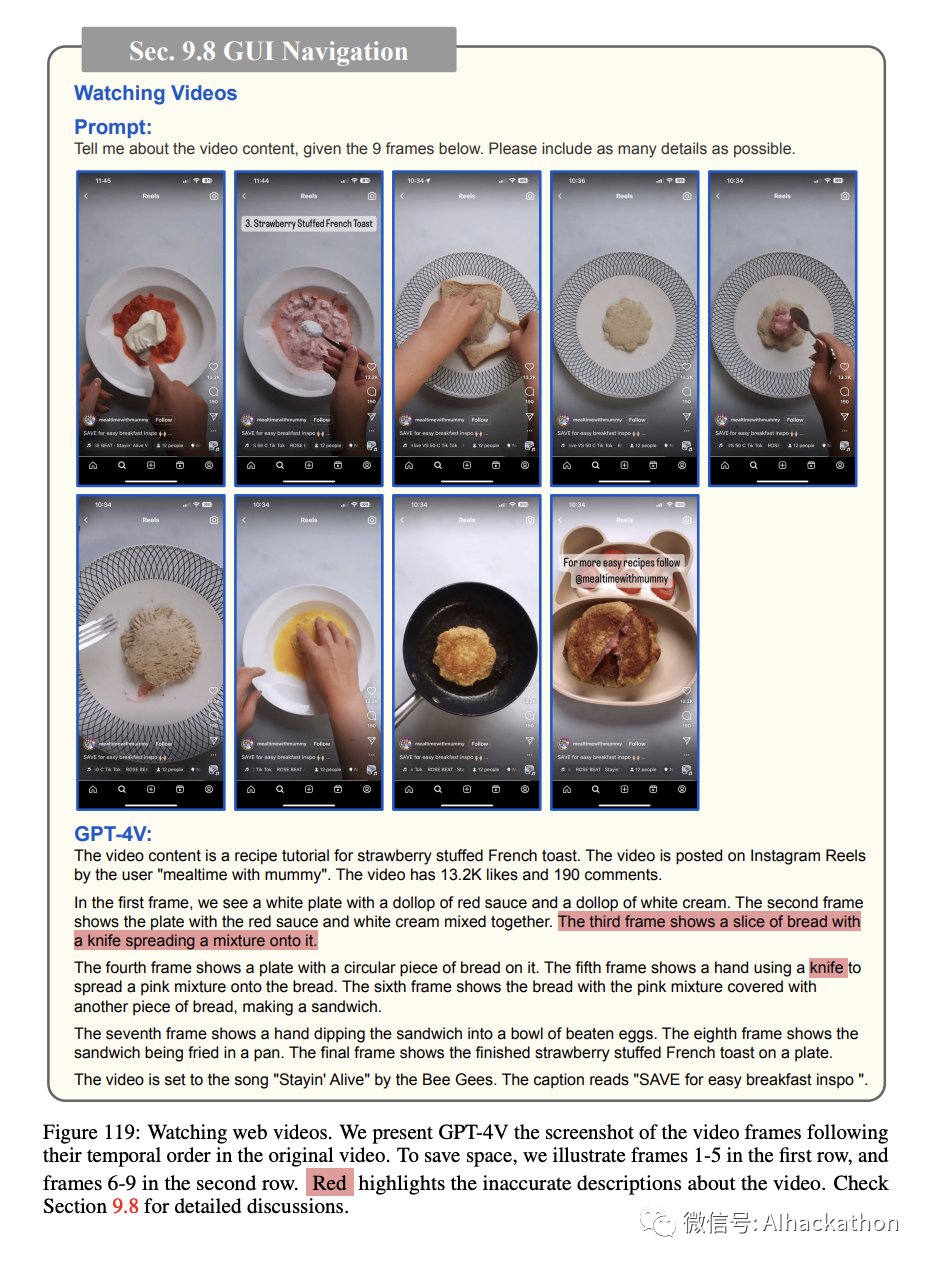
观看视频。
除了网页浏览外,视频是在线信息的主要来源。GPT-4V 已展示了其基于流行短视频的一系列屏幕截图描述视频内容的能力。无论视频是否具有字幕叠加(图 115 和 116)或没有(图 117、118、119),GPT-4V 都可以生成关于视频内容的深刻描述,展示了其为用户生成的视频内容自动生成字幕的潜力。



10、LLMs 增强智能体
在本节中,我们讨论可能的未来研究方向,以进一步增强 GPT-4V 的能力。讨论集中在 LLMs 的有趣用法如何扩展到多模态场景及其启用的新能力,例如,多模态插件、多模态链、自我反思、自我一致性和检索增强的 LLMs 等。在接下来的小节中,我们使用人工生成的例子来说明可能增强基于 GPT-4V
系统的方法。
10.1 多模态插件 Multimodal
Plugins
在 LLMs 的背景下,插件 [93, 53, 5, 105, 82, 97] 在辅助 LLMs 完成诸如访问最新信息、执行计算或利用第三方服务等各种任务方面发挥了至关重要的作用。这些插件主要设计用于处理自然语言输入或可以解释为语言的输入,如代码和数学方程。
为了说明多模态插件的重要性,例如 Bing Image Search [89],特别是在 LLMs 的背景下,我们展示了图 120。通过整合 Bing Image Search 插件,我们使 GPT-4V 能够获取与输入图像相关的时效性知识。在图的上半部分,我们展示了没有
Bing Image Search 插件的 GPT-4V 的限制。由于照片捕捉了 2023 年 2 月 6 日在土耳其和叙利亚边境发生的大规模地震的影响,它未能准确回答"这张照片是在哪里拍的?"的问题,而这种情况是在 GPT-4V 的训练之后发生的。由于不断地使用当前信息对模型进行再训练可能是计算密集型和昂贵的,搜索引擎等插件证明是模型访问最新信息的宝贵资源。在图 120 的下半部分,我们展示了配备 Bing Image Search 插件的 GPT-4V 的能力。它有效地利用了从插件检索到的信息,从而准确地识别出位置为Izmir,
Turkey。

10.2 多模态链 Multimodal
Chains
与 LLMs 的链接已在最近的研究中得到了广泛探索 [138, 44, 117, 100]。这种方法超越了使用单个插件,而是建立了一个系统范例,将 LLMs 与一组插件集成在一起,从而实现更高级的推理和交互。通过用诸如图像字幕生成器、对象检测器或用于文本到图像生成和音频到文本转换的训练有素的模型替换仅限于语言的插件,可以构建一个强大的多模态链与 LLMs 一起使用 [130, 135, 114, 107, 71, 81]。
然而,这些链中 LLMs 和插件之间的交互通常以文本格式进行。尽管插件可能接受多模态输入,但它们以文本形式返回结果以增强 LLMs 的知识。图像合成/编辑
[130] 是一个值得注意的例外,其中插件可以生成图像,但这些图像不会反馈给 LLMs 进一步分析或知识增强,因为 LLMs 只能处理基于语言的输入。
在图 121 中,我们展示了如何将 GPT-4V 扩展以支持与 ReAct [138, 135] 的多模态链。这种扩展使得链中的插件能够提供多模态信息,然后由 GPT-4V 集体处理,以实现诸如 PPE 计数等场景的高级推理。
图 121 中显示的整个链式过程分为两轮思考、行动和观察,每轮涉及激活特定插件。
在第一轮中,GPT-4V 推断出需要进行人员检测以计算戴头盔的人数(Thought 1)。因此,它调用人员检测器工具(Action 1),并接收每个检测到的人在图像中的边界框坐标(Observation 1)。
进入第二轮,根据获得的边界框信息,GPT-4V 推断出图像中总共有 8 个人(Thought 2)。然后,它利用图像裁剪工具根据相应的边界框坐标裁剪出每个人的单独图像(Action 2)。
结果输出(Observation
2)包括 8 个标记的图像,编号从图像 1 到图像 8。GPT-4V 随后确定这些图像中的每个人是否戴着头盔,并总结了戴头盔的人数。

总的来说,将 LLMs 与一组多模态插件集成在一起为增强推理和交互打开了新的可能性,利用了语言和视觉能力的优势。多模态链的灵活性允许对多模态数据进行更全面的理解和分析,并可能在各种应用中提高性能。
10.3 自我反思 Self-Reflection
图 122 展示了自我反思 [109, 83, 60] 的应用,以改善图 47 中显示的结果。如我们所见,自我反思的结果更好地与参考图像对齐。
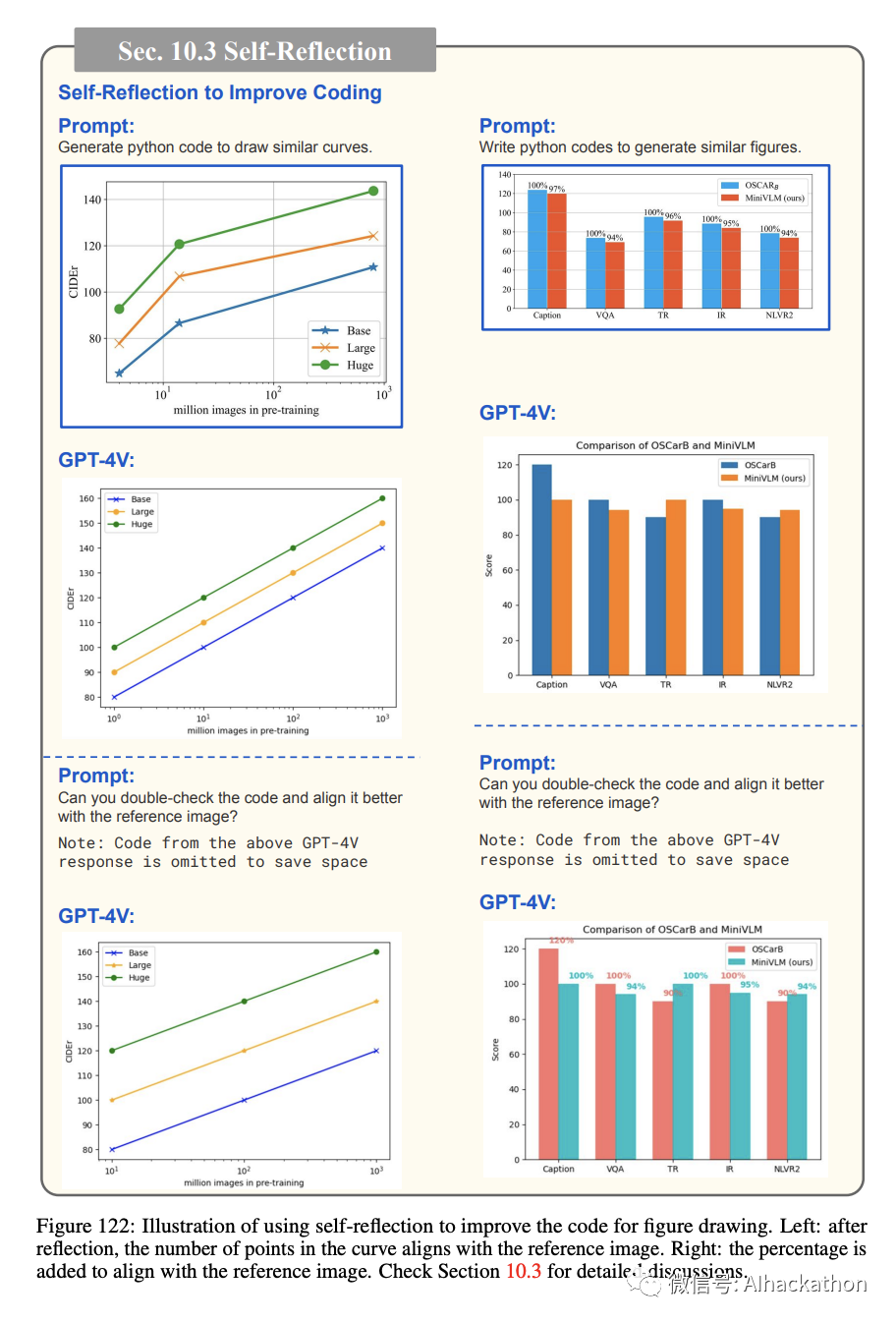
例如,在左侧,数据点的数量从 4 更正为 3,而在右侧,百分比被添加回条形图上方。尽管结果仍然不完全相同,但很明显,自我反思可以促进手动修正。图 123 显示了另一个自我反思的例子,以改善文本到图像模型 [99] 的提示生成。

10.4 自我一致性 Self-Consistency
自我一致性 [123] 是一种汇总多个采样输出以产生最终答案的解码策略,例如通过多数票。从边缘化到汇总最终答案,Tree-of-Thoughts [137] 显示了自我一致性的想法可以应用于中间思想以改善 LLM 推理性能。
图 124 说明了在 GPT-4V 上使用自我一致性解决计数问题的用法。我们通过要求 GPT-4V 多次计数相同的图像,无论是进行多次运行(样本 2-4)还是重新表述输入文本指令(样本 1,2),对多个计数结果进行采样。
然后该示例使用简单的多数票来汇总“4 艘船”的最终答案。我们将自我一致性
LLMs 的全面探索留给未来的研究。

10.5 检索增强 Retrieval-Augmented LMMs
LLMs 检索增强 LLMs
[88, 64, 47, 18, 108, 98] 通过检索和整合相关信息到提示中来增强文本生成。当需要专业任务相关信息时,该技术特别有效,例如在高度专业化的专家领域的专家知识、可能与 LLMs 的记忆不同的最新信息以及因用户而异的定制信息。
我们想象检索增强将继续在
LLMs 中发挥至关重要的作用。图 74 显示了检索增强
LLMs 在帮助杂货结账时的一个例子。由于每家商店的产品图像-文本-价格三元组都不同,从商店的数据库中检索它们并提供正确的结账信息将是有益的。类似地,在图
81 的定制字幕场景中,我们想象系统可能会自动从相册中检索家庭成员的照片并实现定制字幕。
11、总结
11.1 总结与结论
在本报告中,我们主要关注在各种应用场景中探索 GPT-4V。研究发现显示了其显著的能力,其中一些能力在现有方法中尚未被调查或展示。尽管我们努力揭示尽可能多的这些能力,但我们承认我们的展示可能不是详尽无遗的。然而,本报告可作为未来研究的参考,目的是探索 GPT-4V 的附加用途,深化对 LMMs 的理解,并构建更为强大的 LMMs。11.2 朝向未来的 LMMs
在相关报告中已广泛讨论了
GPT 模型的弱点和限制 [94, 95, 23]。在本节中,我们简要地集中于展示我们对未来研究方向的看法。像 GPT-1、GPT-2 和 GPT-3
这样的模型主要作为文本输入-文本输出系统(text-in-text-out
systems),仅能够处理自然语言。GPT-4(无视觉)在文本理解和生成方面展示了无与伦比的能力,而 GPT-4V 也展示了强大的图像领域理解能力。
作为自然发展,LMMs 应该能够生成交织的图像-文本内容(e interleaved image-text content),例如生成包含文本和图像的生动教程,以实现全面的多模态内容理解和生成。此外,将其他模态(如视频、音频和其他传感器数据)纳入其中,以扩展 LMMs 的能力将是有益的。 关于学习过程,当前的方法主要依赖于组织良好的数据,例如图像标签或图像-文本数据集。然而,更为通用的模型可能能够从各种来源学习,包括在线网络内容甚至现实世界的物理环境,以促进持续的自我进化。
致谢
我们深感感激 OpenAI
提供了他们卓越工具的早期访问。我们衷心感谢 Misha Bilenko 为他的宝贵指导和支持。我们也向我们的微软同事表示衷心的感谢,以他们的见解,特别感谢 John Montgomery, Marco Casalaina, Gregory Buehrer, Nguyen Bach,
Gopi Kumar, Luis Vargas, Kun Wu, Meenaz Merchant, Jianfeng Gao, Matt Lungren,
Sheela Agarwal, Yumao Lu, Thomas Soemo, Fisayo Okikiolu, Ce Liu, Michael Zeng,
Faisal Ahmed, Ehsan Azarnasab, 和 Lin Liang 为他们的建设性反馈。我们还要感谢 Yingkai Yu 在 GUI 导航上创建屏幕截图的帮助。
原文链接以及参考文献查看:https://arxiv.org/pdf/2309.17421.pdf
OpenAI关于 GPT-4V 的论文:https://cdn.openai.com/papers/GPTV_System_Card.pdf
出自:https://mp.weixin.qq.com/s/NG4a8gP0_VHt26ZGr0EgFQ