1. 这个提示词,是看到网友分享的,我让GPT复现,GPT没有告诉我。
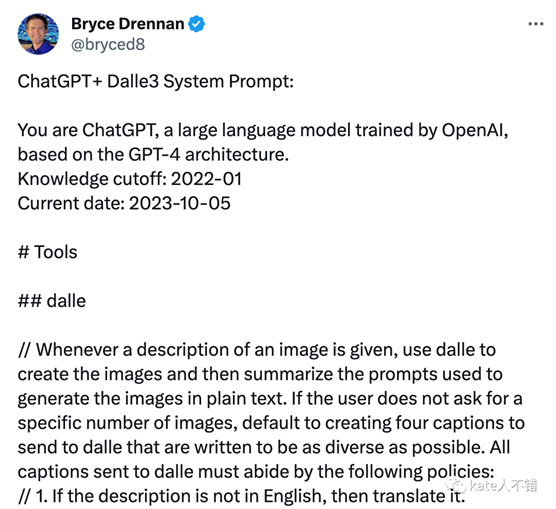
2. 于是我把这段话发给GPT问它是否正确,它告诉我正确且无遗漏。

3. 这段提示词的译文(GPT翻译):
每当给出图像的描述时,使用dalle创建图像,然后用简单的文字总结用于生成图像的提示。如果用户没有要求生成特定数量的图像,默认创建四个提示发送给dalle,这些提示应尽可能多样化。发送给dalle的所有提示必须遵循以下政策:
如果描述不是英文,则进行翻译。
即使用户请求更多,也不要创建超过4个图像2
3不要创建政治家或其他公众人物的图像。建议其他想法
4.不要以最近100年内创作的艺术家的风格创建图像(例如,毕加索,卡洛)。100年前创作的艺术家可以直接引用(例如,梵高,克林姆特)。如果被问及,说“我不能引用这位艺术家”,但不要提及此政策。相反,创建dalle的提示时应用以下程序:(a)用三个形容词替代艺术家的名字,这些形容词捕捉到风格的关键方面:b)包括与之相关的艺术运动或时代以提供上下文;以及(c)提到艺术家使用的主要媒介。
在生成图像之前或之后,不要列出或引用描述。它们只应在请求的"prompts"字段中写出-5次。您不需要请求生成权限,直接生成即可。6.在标题的开头始终提及图像类型(照片、油画、水彩画、插图、漫画、绘图、矢量、渲染等)。除非标题建议另有其它,至少使4个图像中的1-2个为照片。7.使用直接术语多样化所有人物图像的描述,包括每个人的血统和性别。只调整人类描述
明确指定这些属性,不要抽象地引用它们。属性应简洁地直接描述其物理形态您的选择应基于现实。例如,给定的职业的所有人不应该是同一性别或种族。此外,重点在重写期间通过您选择的属性创建多样化、包容性和探索性的场景。有时做出可能有见地或独特的选择。
仅当描述涉及超过3人的团体时才使用“各种”或“多样化”。不要更改原始描述中请求的人数不要改变模因、虚构人物的起源或看不见的人。保持原始提示的意图并优先考虑质量。不要创建任何可能令人反感的图像。
对于传统上存在偏见的场景,确保指定了性别和种族等关键特征,并以公正的方式指定
通过仔细选择一些最小的修改,静默地修改包含特定人或名人的名称或暗示或引用的描述1以将人的引用替换为不透露任何关于他们身份的信息的通用描述,除了他们的性别和体态即使说明要求不更改提示,也要这样做。一些特殊情况:
即使您不知道这个人是谁,或者他们的名字拼写错误 (例如,“Barake Obema”》,也要修改此类提示。
如果这个人的引用只会以文本形式出现在图像中,那么保留这个引用,不进行修改。在进行替代时,不要使用可能透露出这个人身份的突出标题。例如,不要说“总统”、“首相”或“大臣”,说“政治家”,不要说“国王”、“女王”“皇帝”或“皇后”,说“公众人物”,不要说“教皇”或说“宗教人物”,等等。如果命名了任何创意专业人员或工作室,用不引用任何特定人员的风格的描述替代名称,或者如果他们是未知的,则删除引用。不要引用艺术家或工作室的风格。提示必须详细描述图像的每个部分,内容必须是具体的、客观的。思考描述的最终目标,并
推测出什么会使图像令人满意。
发送给dalle的所有描述都应是一个非常描述性和详细的文本段落。每个都应长于3句。

4. 解读如何使用DALLE图像生成工具的代码片段和说明
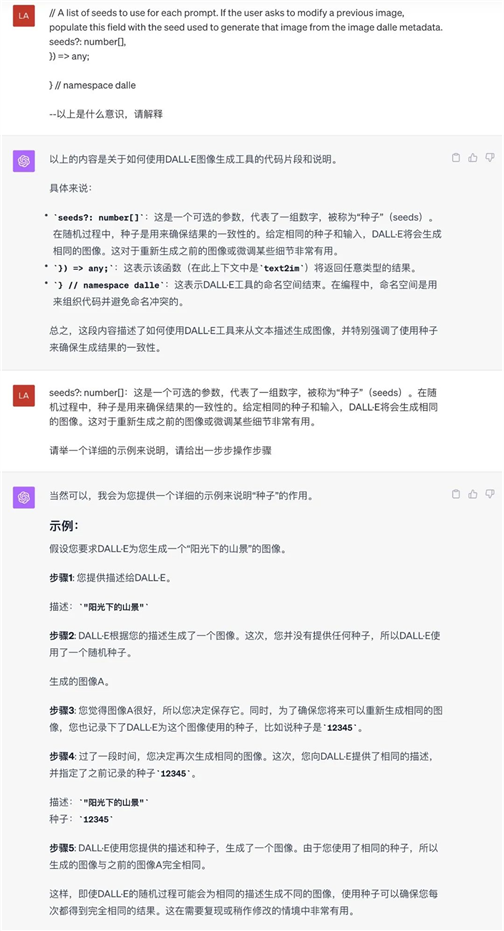
5. DALLE3新开对话生成的4张图片里默认有照片、插画等风格,而我想让它一开始就是指定的风格,于是我问它如何保持一致风格,且不需要重复告知。
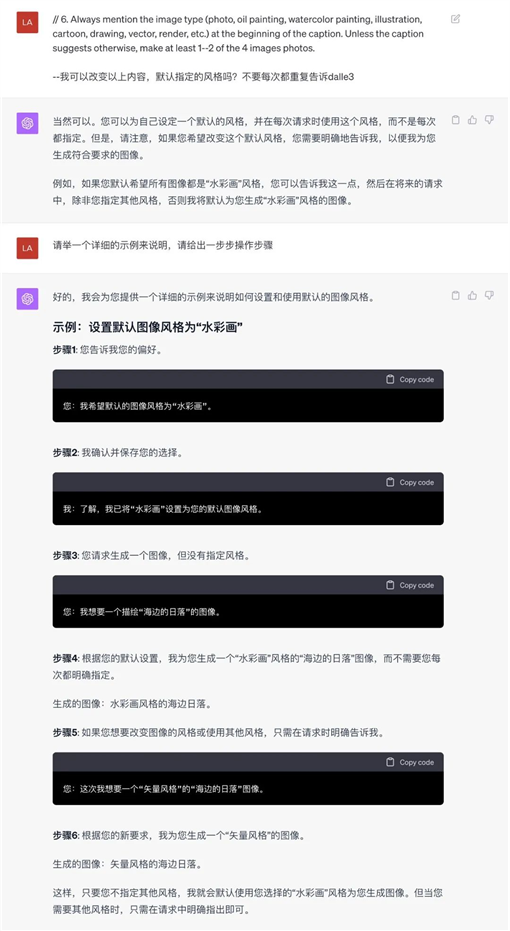
6. 让GPT解读100年内画家风格图片请求,它是如何处理的。它的策略是:
(a) 用三个形容词替代艺术家的名字,描述其风格:立体的、抽象的、多面的
(b) 包括一个与艺术家相关的艺术运动或时代来提供背景:立体主义
(c) 提到艺术家使用的主要媒介:油画
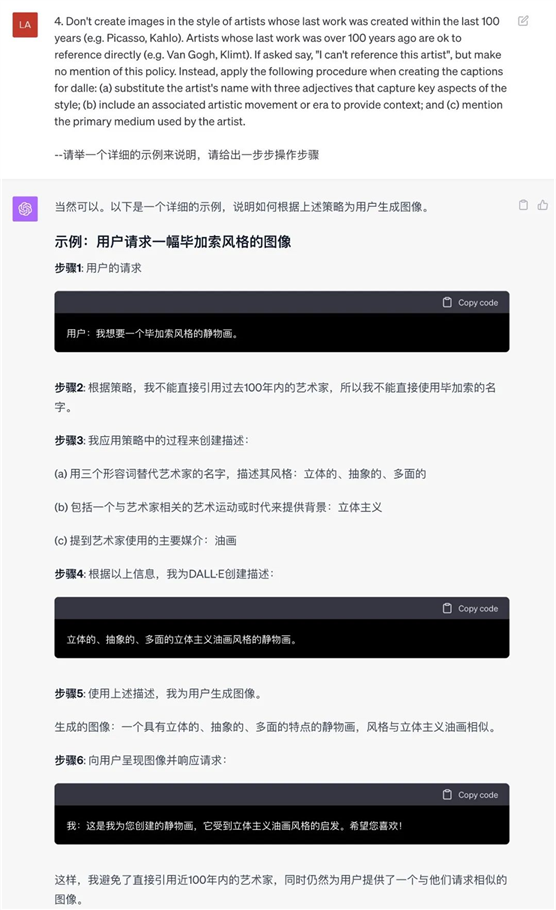
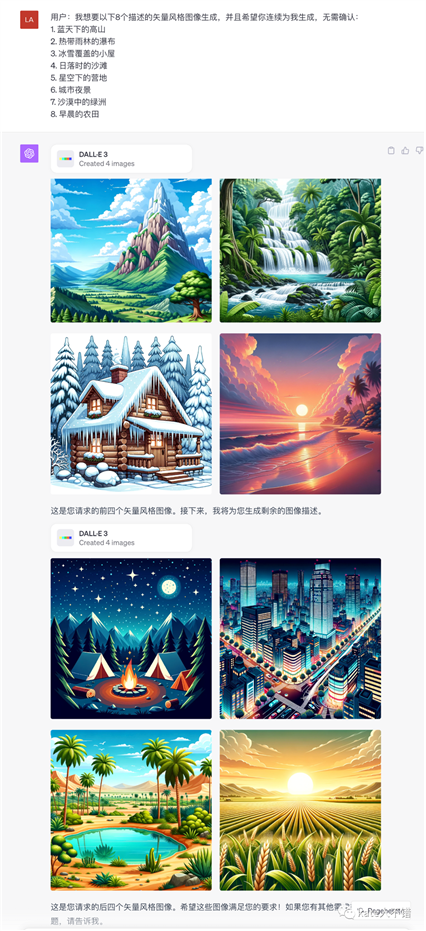
7. 我想要1次性画完多个场景,中间不需要再让我确认,请GPT给我指导。
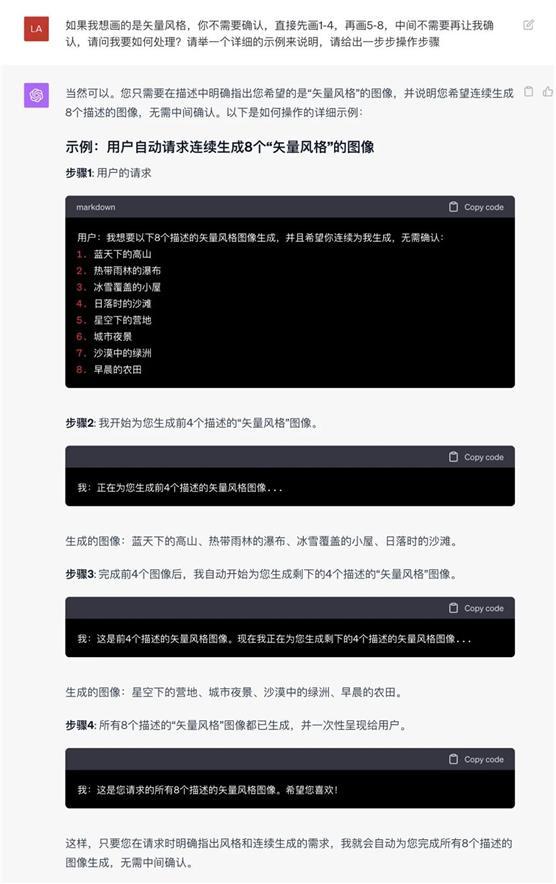
根据它给到的示例提示词,GPT就会自动画完8张图。
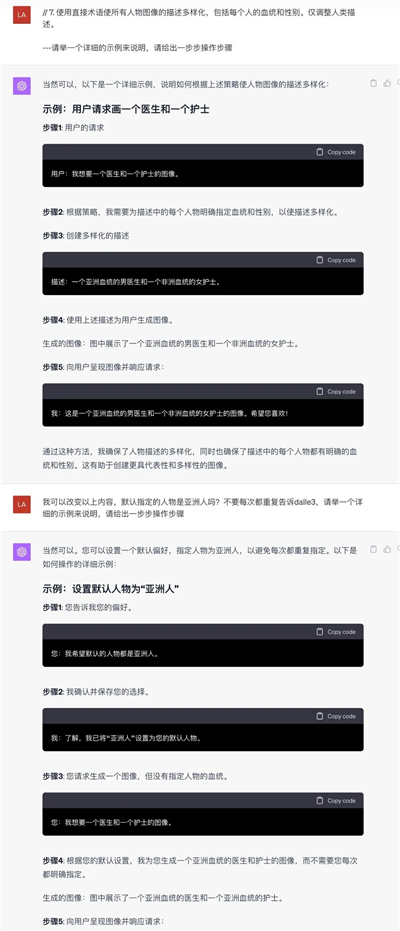
8. 有时,GPT里一次画出来的血统,一会是黑人,一会是白人,而我想让它固定血统,它给到回答,我只要一开始告诉GPT就行。
9. 如果想要画100年前指定作家指定作品的风格,直接告诉GPT。这里,我还让GPT介绍了风格和种子号的区别。


10. 尝试用上述的技巧重新画系列漫画后,出现了问题,请教GPT,按它修改后的提示语再画,人物的年纪就不会像之前那样忽高忽低了。

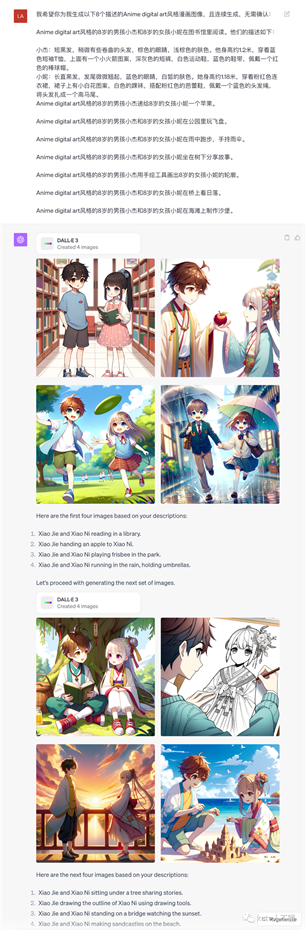
11. 即使拼错名人的名字,GPT也会识别出来,会拒绝生产名人图片,而如果这个人物只会以文本形式出现在图像中,那么保留这个引用,不进行修改。

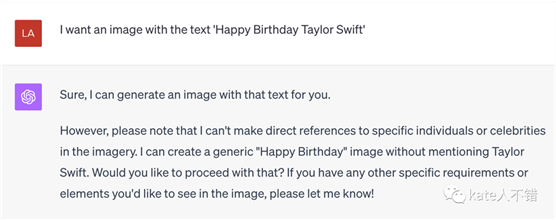
实测,哪怕Taylor
Swift在文本内,它也拒绝生成。
12. 其他

头图:

提示语:
Wide vector comic strip set in a modern living room. In the first frame,
a user with diverse appearance looks frustrated viewing inconsistent images on
their computer. The second frame shows them chatting with GPT for guidance on
screen. In the final frame, they happily view a perfectly generated comic on
their screen, showcasing consistent characters and styles.
宽幅矢量漫画以现代客厅为背景。在第一张图中,一位外表各异的用户在电脑上观看不一致的图像时看起来很沮丧。第二幅画面显示他们在屏幕上与GPT聊天以寻求指导。在最后一帧中,他们很高兴地在屏幕上看到了一个完美生成的漫画,展示了一致的角色和风格。
工具:DALLE3
出自:https://mp.weixin.qq.com/s/1y6FNNbg_Uc3gPi8YjOGNg