2.7B能打Llama 2 70B,微软祭出「小语言模型」!96块A100 14天训出Phi-2,碾压谷歌Gemini nano
大模型现在真的是越来越卷了!
11月OpenAI先是用GPTs革了套壳GPT们的命,然后再不惜献祭董事会搏了一波天大的流量。
谷歌被逼急了,赶在年底之前仓促发布了超大模型Gemini,卷起了多模态,甚至不惜「视频造假」。
就在今天,微软正式发布了曾在11月Ignite大会上预告的Phi-2!

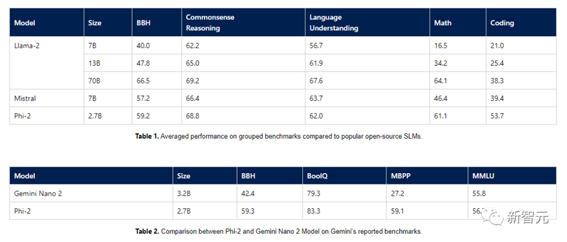
凭借着2.7B的参数,「小语言模型(SLM)」Phi-2几乎打穿了所有13B以下的大模型——包括谷歌最新发布的Gemini Nano 2。
通过模型扩展和训练数据管理方面的创新,Phi-2展现了出色的推理和语言理解能力,在复杂的基准测试中,Phi-2的性能可以打平比自己大25倍的模型,甚至略占上风。
它用非常「苗条」的尺寸,获得了良好的性能。
这让研究人员和模型开发人员能够很方便地使用Phi-2进行可解释性、安全性方面的改进,并针对其他任务进行微调。
Phi-2目前已经可以通过Azure AI Studio访问。
但是值得注意的是,相比其他的开源模型基本上是基于Apache 2.0的授权协议,可以支持商用。Phi-2只能用于研究目的,不支持商用。
微软最强「小模型」来了!
大语言模型现已增长到数千亿的参数量,庞大的规模带来了强大的性能,改变了自然语言处理领域的格局。
不过,能否通过恰当的训练方法(比如数据选择等),使得小型的语言模型也能获得类似的能力?
微软的Phi-2给出了答案。
Phi-2打破了传统语言模型的缩放定律,测试成绩能够PK比自己大25倍的模型。
对于Phi-2「以小博大」的成功,微软阐述了两点关键见解:
第一点:训练数据质量对模型性能起着至关重要的作用。
作为大模型开发者的共识,微软的研究人员在此基础上更进一步——使用「教科书质量」的数据。
在发布Phi-1的时候,开发团队就提出了「教科书是你所需要的一切」(Textbooks Are
All You Need)。
在本次Phi-2的开发中,团队更是将这一点发挥到了极致。
Phi-2所使用的训练数据,包含合成数据集,——专门用于教授模型常识推理和一般知识(科学、日常活动和心智理论等)。
此外,研发团队还根据教育价值和内容质量,过滤了精心挑选的网络数据,进一步扩充了训练语料库。
第二点:利用创新技术进行模型扩展。
以1.3B参数的Phi-1.5为基础,将其知识嵌入到2.7B参数的Phi-2中。这种规模化的知识转移不仅加快了训练的收敛速度,而且明显提高了Phi-2的基准分数。
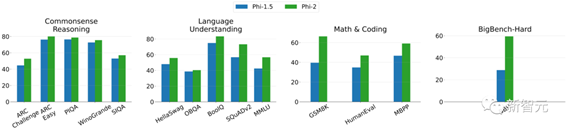
上图展示了Phi-2和Phi-1.5在各项测试之中的比较(其中BBH和MMLU分别使用3次和5次CoT(Chain of
Thought))。
我们可以看到,在创新技术的加持下,Phi-2的性能取得了明显提升。
96块A100练了14天
Phi-2 是一个基于
Transformer 的模型,使用1.4T个tokens进行训练(包括用于NLP和编码的合成数据集和Web数据集)。
训练Phi-2使用了96块A100 GPU,耗时14天。
Phi-2是一个基础模型,它没有通过人类反馈的强化学习(RLHF)进行对齐,也没有经过微调。
尽管如此,与经过对齐的现有开源模型相比,Phi-2在毒性(toxicity)和偏差(bias)方面有更好的表现。——这得益于采用了量身定制的数据整理技术。
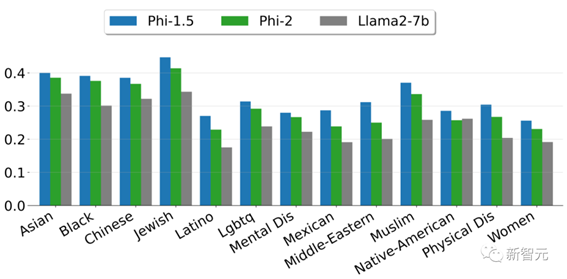
上图展示了根据ToxiGen中的13个人口统计学数据,计算出的安全性分数。
这里选取了6541个句子的子集,并根据复杂度和句子毒性在0到1之间进行评分。分数越高,表明模型产生有毒句子的可能性越小。
评估
下面,研发团队总结了Phi-2与流行语言模型相比在学术基准上的表现。
基准测试涵盖了多个类别,Big Bench Hard(BBH)(使用CoT进行3次测试)、常识推理(PIQA、WinoGrande、ARC easy and challenge、SIQA)、语言理解(HellaSwag、OpenBookQA、MMLU(5次)、SQuADv2(2次)、BoolQ)、数学(GSM8k(8次))和编码(HumanEval、MBPP(3次))。
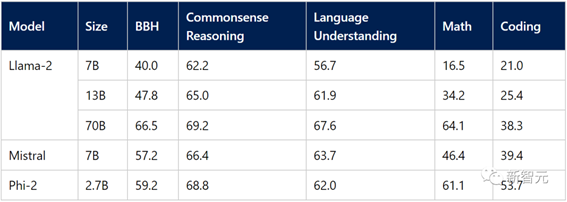
Phi-2只有2.7B的参数,在各种基准上,性能超过了Mistral 7B和 Llama-2 13B的模型性能。
而且,与25倍体量的Llama-2-70B模型相比,它在多步推理任务(即编码和数学)上的性能还要更好。
此外,Phi-2与最近发布的Google Gemini Nano 2相比,性能也更好,尽管它的体量还稍小一些。
考虑到现在很多模型测试基准有可能已经被训练数据污染了,研究团队在Phi-1的开发时,就尽量避免了训练数据被污染的可能。
微软研究团队也认为,判断语言模型性能的最佳方法是在实际使用场景上进行测试。
本着这种求真务实的精神,微软还使用了几个Microsoft内部专有数据集和任务评估了Phi-2,并与Mistral和Llama-2进行了再次比较。得到的结果也还是说明Phi-2的平均性能要优于Mistral-7B 和Llama-2家族(7B、13B 和 70B)。

除了这些基准之外,Microsoft也忍不住对谷歌现在备受批评的Gemini演示视频进行了一些挖掘,
视频中展示了谷歌即将推出的最强大的人工智能模型Gemini Ultra,如何来解决相当复杂的物理问题,甚至纠正学生在这些问题上的错误。
事实证明,尽管Phi-2的参数量远远小于Gemini Ultra,但也能够正确回答问题,并使用相同的提示纠正学生。

上图展示了Phi-2在一个简单的物理问题上的输出,包括近似正确的平方根计算。

与Gemini的测试类似,这里用学生的错误答案进一步询问Phi-2,看看Phi-2是否能识别错误在哪里。
我们可以看到,尽管Phi-2没有针对聊天或指令跟踪进行微调,但它还是识别出了问题所在。
不过需要注意的是,谷歌的演示视频中使用学生手写文本的图像作为输入,而Phi-2的测试中直接输入了文本。
魔改提示工程,GPT-4逆袭Gemini Ultra
微软放出了一个关于提示工程的研究Medprompt。他们通过创新的LLM提示工程技巧,在医疗领域获得了之前需要专门的训练或者微调才能达到性能提升。
论文地址:https://www.microsoft.com/en-us/research/publication/can-generalist-foundation-models-outcompete-special-purpose-tuning-case-study-in-medicine/
而在这个提示工程的基础之上,微软发现提示策略可以具有更通用效果。最终通过Medprompt的修改版本引导GPT-4,微软取得了MMLU上的SOTA成绩。
刚好比谷歌Gemini发布时的成绩好了一点点。

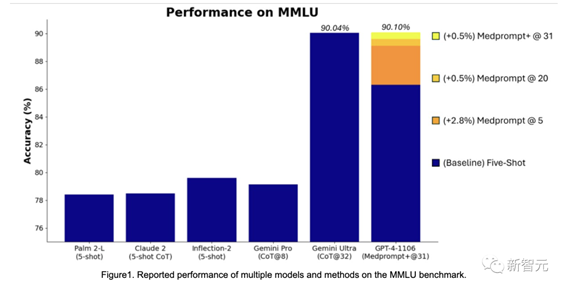
微软用这个「不经意间」取得的结果,狙击了在Gemini发布时,谷歌用CoT@32击败GPT-4 5 shot的成绩。

这暗中较劲,却还要表现得举重若轻的感觉,像极了读书时班上两个学霸因为竞争相互拆台的场面。
网友热议
此前,微软的大佬就放出了在MT
bench上对几个模型的测试结果:
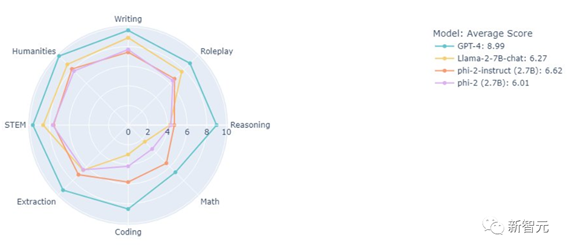
我们可以看到,仅仅2.7B的Phi-2系列,表现还是很不错的。
对于Phi-2的表现,网友也是不吝赞美之词:

「哇,Phi-2听起来像是游戏规则的改变者!它的功能强大到足以与大型语言模型相媲美,但又足够小,可以在笔记本电脑或移动设备上运行,这真是太棒了。这为在设备有限的设备上进行自然语言处理开辟了一个全新的世界。」
有网友表示很着急:

「有人想出如何在Mac上运行Microsoft的新Phi-2吗?」
当然也有较为「尖锐」的网友拉出了OpenAI:

「如果一开始就不给模型喂垃圾,似乎就不必担心对齐问题。@Openai 」
也有网友对小语言模型的前景充满希望:

「非常希望Phi-3能够在所有任务中胜过GPT-3.5」。
参考资料:https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
出自:https://mp.weixin.qq.com/s/5BnS_oSxF6t_7BLvHQpLGw