前不久小圈为大家介绍过 Coqui 文本转语音(Text-to-Speech,TTS) 模型,相比较市面上原有的开源TTS模型,Coqui
有其独特的优势,也受到了广大科技互联网爱好者的青睐。
但是近期,网易有道AI算法团队也开源了一款国产TTS语音合成引擎EmotiVoice,刚上线仅一周时间就暴涨4200颗星,问鼎当周GitHub trending流行榜第一。而如今已冲到了 4.5k Star。
接下面让我们看看这款国产语音库为何如何迅速的火遍大江南北的🔥!
EmotiVoice 项目介绍
EmotiVoice 是一款现代化的开源语音合成引擎,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。
通过官方项目介绍可以了解到,EmotiVoice 最突出的功能是情感合成,允许我们创建多种情感的语音。这个也是其他TTS开源项目没有提到过的。
开源地址:https://github.com/netease-youdao/EmotiVoice
如何搭建这个 TTS 项目?
1、第一种方法,使用Docker搭建,一键运行
体验 EmotiVoice 最简单的方法就是运行 docker 镜像。但是尽量需要一台配备 NVidia GPU 的机器。
然后使用 docker 命令运行 EmotiVoice:
docker run -dp 127.0.0.1:8501:8501 syq163/emoti-voice:latest
这样就会在本地起一个http服务,端口为8501,能成功访问即可体验!

2、第二种方式,自己一步步安装
首先创建虚拟环境,安装相关的依赖包
conda create -n EmotiVoice python=3.8 -y
conda activate EmotiVoice
pip install torch torchaudio
pip install numpy numba scipy transformers==4.26.1 soundfile yacs g2p_en jieba pypinyin
然后下载模型文件,这一步官方也提供了两种方法
模型下载方式1:
安装 git lfs 指令,然后通过lfs命令在开源模型库huggingface,一键下载所有模型文件
git lfs install
git lfs clone https://huggingface.co/WangZeJun/simbert-base-chinese WangZeJun/simbert-base-chinese
模型下载方式2:
通过下载命令或直接去模型库网站,一个个手动下载
mkdir -p WangZeJun/simbert-base-chinese
wget https://huggingface.co/WangZeJun/simbert-base-chinese/resolve/main/config.json -P WangZeJun/simbert-base-chinese
wget https://huggingface.co/WangZeJun/simbert-base-chinese/resolve/main/pytorch_model.bin -P WangZeJun/simbert-base-chinese
wget https://huggingface.co/WangZeJun/simbert-base-chinese/resolve/main/vocab.txt -P WangZeJun/simbert-base-chinese
下载完三个模型文件后,将其放到对应目录下

将 g_*, do_* 文件放到outputs/prompt_tts_open_source_joint/ckpt,将checkpoint_*放到outputs/style_encoder/ckpt中。
输入推理文本格式:
说话人|情感样式内容|音素|说话内容
我们可以运行下面这个代码,自动生成推理文本音素(phonemes)
python frontend.py data/my_text.txt > data/my_text_for_tts.txt
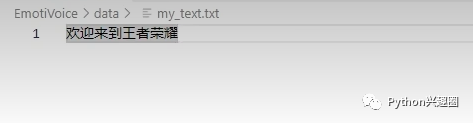
新建一个my_text.txt文件,我们在里面输入一个字符,比如:“欢迎来到王者荣耀”。
生成的音素文件my_text_for_tts.txt输出:

然后我们再把说话文本和说话人整合在一起:

最后再执行推理命令:
TEXT=data/inference/text
python inference_am_vocoder_joint.py \
--logdir prompt_tts_open_source_joint \
--config_folder config/joint \
--checkpoint g_00140000 \
--test_file $TEXT
合成的语音结果在:outputs/prompt_tts_open_source_joint/test_audio

大家是不是感觉很繁琐,很麻烦,其实还有更简单的方式。我们使用pip命令安装一个streamlit包,然后运行一行命令即可完成上述所有操作。
pip install streamlit
streamlit run demo_page.py

运行命令后会在本地启动一个http服务,到了这一步就跟docker一键运行一样了。然后我们点击提示的地址打开网页即可看到:

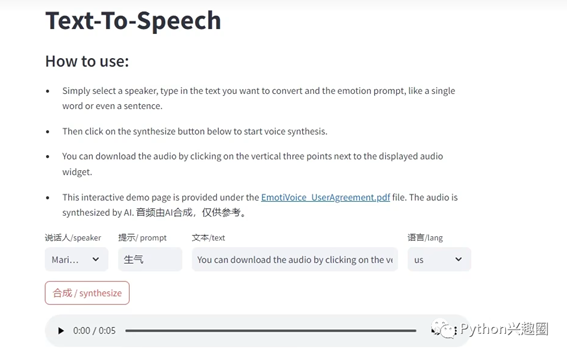
接下来我们就完全可以再页面上愉快的使用TTS功能了,可以自定义选择说话人、情感语气提示词、语音文本及相应的语言(支持中文和英文),然后点击合成即可生成语音文件。
总结
以上就是 EmotiVoice 大概的一个介绍和搭建使用体验。对于我来说还是很新颖的,毕竟之前的TTS产品即不支持中文,也没有一个界面可以操作!EmotiVoice 这点就很友好,很nice辣!
EmotiVoice 以其多声音支持和情感合成能力,在多种应用场景中展现出巨大的潜力。无论是内容创作、个性化服务还是教育培训,EmotiVoice都能提供高质量和高度个性化的语音合成解决方案。
出自:https://mp.weixin.qq.com/s/kcVYp3EF52E3qD5qzpl9Og