最近不少国产大模型声称,他们的表现甚至超越了业界知名的ChatGPT模型。然而,在实际应用中,这些国产大模型的综合表现往往还是逊色于ChatGPT。
这背后,其实隐藏了一个经济学家查尔斯·古德哈特(Charles Goodhart)所提出的 Goodhart's Law 陷阱。
起初他们说超越 GPT-3.5,大家已经见怪不怪,例如:
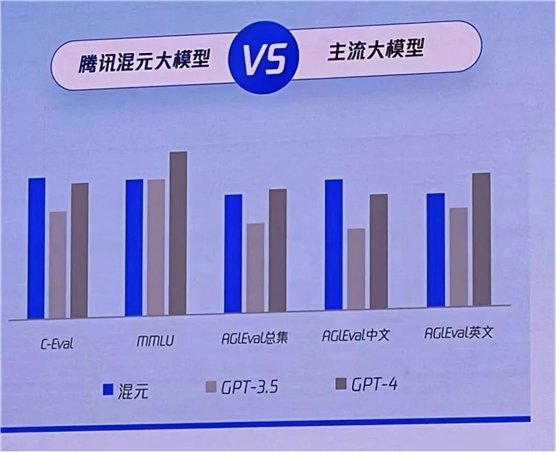
后来,竟然有人说「GPT-4相比毫不逊色」,且也学起来GPT-4进行收费了。

他们凭什么这么说呢?
除了跟 「GPT-4 相比毫不逊色」这个是空口白话之外,其他的国产大模型,都拿出了证据。那就是他们在三大测试集上与ChatGPT的对比:分别是 C-Eval, mmLU, AGIEval。
o
• C-Eval 是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集
o
o
• MMLU 是Hendrycks et al 2020年在论文 "Measuring
Massive Multitask Language Understanding" 中提出的,它旨在评估语言模型在广泛的知识领域和任务类型上的理解能力。
o
o
• AGIEval 是微软的一个华人研究团队发布了一项基准测试
,这项基准测试专门用于对基础模型的类人能力做准确考察(涵盖高考、法学入学考试、数学竞赛和律师资格考试等
o
用这些测试集来评价大模型的表现,就相当于是「开卷考试」,题目都是公开的。这时候,各家大模型就可以针对这些模型,进行专门的训练,就可能会出现在测试集上表现很好,但可能在现实世界的其他应用场景中表现不尽人意。表现出来,就是用户在实际使用中,感觉其跟ChatGPT还差得远。
这其实就是落入了Goodhart's law 的陷阱。
Goodhart's Law 最初由英国经济学家查尔斯·古德哈特(Charles Goodhart)提出。该法则的基本内容是:「当某个指标成为目标时,它就不再是一个好的指标。」 这意味着,当人们开始直接优化某一指标以达成某一目标时,该指标就会失去作为评价实际表现的准确性。
当这三个测试集成为衡量大模型表现的指标时,就会出现专门为了得高分而做的各种技术性调整,但这些调整可能背离了提升大模型能力的初衷。
智能研究院副院长兼总工程师林咏华(对话智源林咏华:有些大模型的评测基准已经失去意义)在一个访谈中就对当前的打榜做了如下评价:

到现在确实仍然没有一个被公认的测评集,但至少C-Eval、MMLU以及CMMLU,这几个类似的测评集已经有点被各个模型过度训练。
所以,时至今日观察大模型能力时,我建议大家不用过度关注这几个测试集的评分。另外,我一直觉得,如果模型为了拉这些榜单的分数而去训练的话,容易损失模型在之后的一些能力的。
Goodhart's Law 在现实生活中有非常多的表现。因为一旦某个指标被用作目标,人们可能会找到实现这一目标的“捷径”,而忽视了最初使用该指标的真正意图。
例如,哥伦比亚大学为了提升学校排名而出现的作弊事件。
2022年,哥伦比亚大学被爆出在提交给《美国新闻与世界报道》(U.S. News & World Report) 的排名数据中作弊,这影响了它在2022年国家大学排名中的位置。
这个问题是一个现实世界中的Goodhart's Law例子,因为它体现了当学校过分关注排名(一个被优化的指标)时,可能会忽视教育质量(实际目标)并导致不诚实的行为。
具体来说,哥伦比亚大学在报告其教师资源、研究活动和学生情况等信息时存在不准确之处。报道称,一些关键指标被高估,包括全职教师比例、教师薪资和学生入学时的成绩等。当这些数据被用于计算大学排名时,它们可能不真实地反映了学校的实际情况。
再以用户体验行业为例。用户体验行业经常使用的一个指标就是 NPS,即净推荐指数(0-10分的推荐意愿打分题)。当公司都在想着优化 NPS 时,各种作弊行为也出现了。
比如汽车4S店的销售员,一般都会跟你说,接到回访电话时要选10分,不然他就要被扣工资。
比如一些场景的数据收集,相关人员会站在那里看着你填,很多人就不好意思打低分。
这两种情景,都使得NPS分数失去了他本来的意义,没有反映出真实情况。
怎样避免陷入Goodhart陷阱呢? 关键在于确保指标的使用不会成为目标本身,保持指标的多元性和平衡,以及持续的检验和调整。以下是一些策略:
• 多元化指标:不要只依赖单一指标来衡量成功。使用一系列相关的指标可以更全面地反映情况。
• 定性与定量相结合:除了定量的数据指标外,还应包括定性分析,比如用户访谈、案例研究,以获取更全面的了解。
• 过程指标与结果指标结合:监控中间过程的指标和最终结果的指标,可以帮助确保目标的实现是通过健康的过程,而非操纵或游戏规则。
• 动态调整指标:定期评估和调整指标体系,确保它们依然有效地衡量想要关注的行为或性能。
这些措施也适用于用户研究经常做的体验度量模型,都是通过选取指标来衡量系统表现、促进系统优化。
通过这些方法的组合使用,可以在一定程度上抑制Goodhart's Law的负面影响,帮助组织更真实、更有效地追求其长期目标。
对于这些大模型而言,关注真正能提升大模型能力的多元指标,而不是为了提升分数而训练,才会真正带来全面能力的提升。
期待看到国产大模型在体感上真正超越 ChatGPT 的一天。
出自:https://mp.weixin.qq.com/s/QeRQX8Z-1RsDO15xL2ydgw