上次我们介绍了
OpenAI 的新版 API,包括语音转文字、生成图片和图片识别等功能,这次 API 的更新还包含了一个重量级的功能,就是类似 GPTs 的 Assistant API,它不仅可以完成 GPTs 的所有功能,还能使用自定义的工具,可以说是比 GPTs 更加强大。今天我们就来介绍 Assistant API 的基本原理和使用方法,最后通过一些代码示例来展示它的强大功能。
设计原理
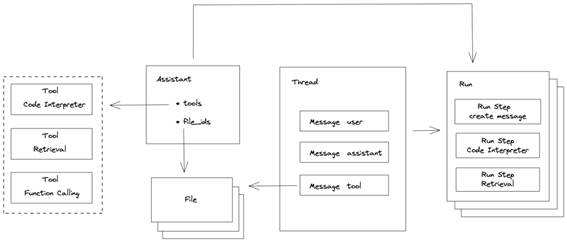
上面是整理的 Assistant API 对象关系图,在图中我们可以看到如下关系:
Assistant 对象是用来执行命令的对象,它有多个属性,其中包括 tools 和 file_ids,分别对应 Tool 对象和 File 对象。
Thread 对象表示一个聊天会话,它是有状态的,就像 ChatGPT 网页上的每个历史记录,我们可以对历史记录进行重新对话,它包含了多个 Message 对象。
Message 对象表示一条聊天消息,分不同角色的消息,包括 user、assistant 和
tool 等。
Run 对象表示一次指令执行的过程,需要指定执行命令的对象 Assistant 和聊天会话 Thread,一个 Thread 可以创建多个 Run。
Run Step 对象表示执行的步骤,一个 Run 包含多个 Run Step。
Tool 对象表示执行命令时需要用到的工具,有代码解释器(Code Interpreter)、知识检索(Retrieval)和自定义工具(Function Calling)等。
File 对象表示执行命令时所用到的文件,比如知识检索时上传的文档,它可以一开始在 Assistant 对象中指定,也可以聊天过程中在 Message 对象中指定。
API 执行过程如下:
创建 Assistant
创建 Thread 和 Message,可以分开创建也可以一起创建
创建 由 Assistant 和 Thread 组成的 Run,创建完
Run 后会自动执行 Thread 中的指令
轮询 Run 状态,检查是否为 completed
(可选)如果是调用自定义工具,需要提交工具的执行结果
如果状态是 completed 则获取最终结果
Assistant
首先我们需要创建一个 Assistant 对象,因为这个 API 是 beta 版本,如果是通过 curl 调用 API 的话,需要在 header 中加上OpenAI-Beta: assistants=v1,如果是使用 OpenAI 的 Python 或
Npm 包的话则不需要,这些包已经默认帮你添加了。示例代码如下:
from openai import OpenAI
client = OpenAI()
def create_assistants(instructions, tools=[], file_ids=[]):
assistant = client.beta.assistants.create(
name="Help assistant",
instructions=instructions,
tools=tools,
model="gpt-3.5-turbo-1106",
file_ids=file_ids,
)
return assistant
因为是 beta 版本,model 参数需要用最新的模型,比如 gpt-3.5-turbo-1106 或者 gpt-4-1106-preview。
name 是 Assistant 的名字。
instructions
参数相当是 Chat API 中的 system message,即系统指令,一般用来让 LLM(大语言模型)扮演某种角色。
tools 是指使用的工具,有代码解释器、知识检索和自定义工具等。
file_ids 是指上传的文件,在每个 Assistant 中最多添加 20 个文件,每个文件最大 512M,整个组织的文件量不能超过 100G,文件的支持类型可以参考这里[1]。
上传文件的方法如下:
def create_file(file_path):
file = client.files.create(file=open(file_path, "rb"), purpose="assistants")
return file
目前上传文件有 2 种用途,一种是用于微调(fine turning),一种是用于 Assistant,因此在 Assistant 中上传的文件,purpose 要写 assistants。
Assistant[2] 和 File[3] 更多的 API 可以看官方的 API 文档。
Thread
接下来是创建一个 Thread,可以单独创建,也可以和 Message 一起创建,这里我们连同 Message 一起创建,示例代码如下:
def create_thread(prompt):
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": prompt,
"file_ids": [file.id],
}
]
)
return thread
在 Thread 中没有限制 Message 的数量,但一旦超过 token 限制,就会进行智能截断。
prompt 是指用户输入的问题。
file_ids 是指上传的文件,可以包含图片和文件,但目前 user 角色的消息还不支持图片。
Thread 更多的 API 可以看官方的 API 文档[4]。
Run
然后是创建 Run,创建 Run 时需要指定
Assistant 和 Thread,示例代码如下:
def run_assistant(thread, assistant):
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
return run
在创建 Run 时,可以通过 model、instructions、tools
等参数来覆盖 Assistant 中的设置,但
file_ids 不能被覆盖。
下面是 Run 的状态流转图:
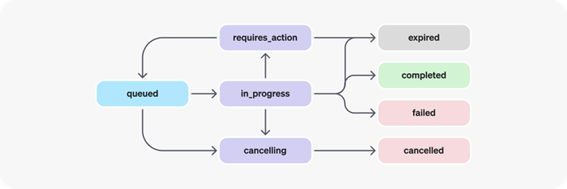
当创建 Run 后,Run 会自动进入 queued 状态
queued 状态后进入到 in_process 状态,表示 Run 正在执行
根据执行结果,如果执行成功则进入
completed 状态,如果执行失败则进入 failed 状态
在 in_process 状态下,可以通过 Run 的 cancel API 来取消执行,Run 会进入 cancelling 状态,然后进入 cancelled 状态
在执行过程中如果用到了自定义工具,in_process
状态会进入 requireds_action 状态,表示需要提交工具的执行结果
提交工具的执行结果后,Run 会再次进入 queued 状态
如果迟迟没有提交工具的执行结果,超过了过期时间(一般是从创建 Run 时算起 10 分钟),Run 会进入 expired 状态
当状态为 in_process 时,表示 Thread 被锁定,这意味着 Thread 不能添加新消息和创建新的 Run
当创建完了 Run 后,我们需要根据 Run 的
ID 来获取 Run,查询其状态,这是一个重复的过程,下面是查询 Run 的方法:
def retrieve_run(thread, run):
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
return run
Run 更多的 API 可以看官方的 API 文档[5]。
Run Steps
当 Run 运行完成后,我们可以通过获取 Run 的步骤来查看执行的过程,示例代码如下:
def list_run_steps(thread, run):
run_steps = client.beta.threads.runs.steps.list(
thread_id=thread.id,
run_id=run.id,
)
return run_steps
获取的 Run Steps 是按时间从早到晚进行排序的,即最早的 Run Step 在最前面,最晚的 Run Step 在最后面。
Run Step 有两种类型,一种是 message_creation,表示创建消息,另一种是 tool_calls,表示执行工具,包括代码解释器、知识检索和自定义工具等。
获取的结果包含分页的参数,可以通过
has_more 来判断是否有下一页的数据。
Run Step 也有对应的状态,状态流转图如下所示:
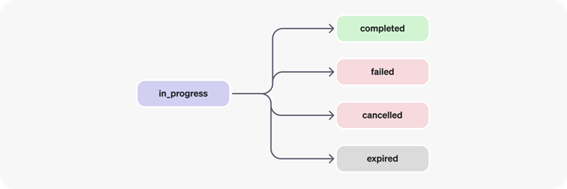
Run Step 状态比 Run 的状态要简单一些,状态的流转条件跟 Run 的一样,这里就不再赘述了。
Message
当 Run 运行完成后,我们还需要获取 message 的结果,示例代码如下:
def list_messages(thread):
thread_messages = client.beta.threads.messages.list(thread_id=thread.id)
return thread_messages
获取的 message 是按时间倒序排序的,即最新的 message 在最前面,最早的 message 在最后面。因此我们要获取 Run 的最终答案,只需要获取第一条 message 的结果即可。
获取的结果包含分页的参数,可以通过
has_more 来判断是否有下一页的数据。
Message 更多的 API 可以看官方的 API 文档[6]。
代码演示
下面我们来通过几个示例来演示下 Assistant API 的具体功能。
代码解释器
我们使用代码解释器来解一道方程式,示例代码如下:
from time import sleep
def code_interpreter():
assistant = create_assistants(
instructions="你是一个数学导师。写代码来回答数学问题。",
tools=[{"type": "code_interpreter"}]
)
thread = create_thread(prompt="我需要计算这个方程式的解:`3x + 11 = 14`。你能帮我吗?")
run = run_assistant(thread, assistant)
while True:
run = retrieve_run(thread=thread, run=run)
if run.status == "completed":
break
sleep(1)
messages = list_messages(thread)
print(messages.data[0].content[0].text.value)
print(f"messages: {messages.json()}")
run_steps = list_run_steps(thread=thread, run=run)
print(f"run_steps: {run_steps.json()}")
我们首先创建一个 Assistant,指定 instructions 为你是一个数学导师。写代码来回答数学问题。
Assistant 中使用了代码解释器工具{"type": "code_interpreter"}。
然后创建一个 Thread,输入我们的问题,求解一道方程式。
创建 Run,然后通过一个循环来查询 Run 的状态,直到状态为 completed 时退出循环。
获取最终的结果,即第一条 message 的内容。
运行结果如下:
方程式`3x + 11 = 14`的解为 x = 1。
我们再来看这个 Run 中产生的所有 Messages 信息:
{
"data": [
{
"id": "msg_7cyjjNTgjXOtWlnLOFIeMKW4",
"object": "thread.message",
"role": "assistant",
"content": [
{
"text": {
"annotations": [],
"value": "方程式`3x + 11 = 14`的解为x = 1。"
},
"type": "text"
}
]
},
{
"id": "msg_xVpdPAd4VOO6Ve5bJ5XoOoiw",
"object": "thread.message",
"role": "user",
"content": [
{
"text": {
"annotations": [],
"value": "我需要计算这个方程式的解:`3x + 11 = 14`。你能帮我吗?"
},
"type": "text"
}
]
}
],
"object": "list",
"has_more": false
}
总共只有 2 条消息,一条是 user 输入的问题,另一条是 assistant 返回的结果,中间并没有工具的消息。我们再来看这个 Run 中的所有 Run Step 信息:
{
"data": [
{
"object": "thread.run.step",
"status": "completed",
"step_details": {
"message_creation": { "message_id": "msg_7cyjjNTgjXOtWlnLOFIeMKW4" },
"type": "message_creation"
},
"type": "message_creation"
},
{
"object": "thread.run.step",
"status": "completed",
"step_details": {
"tool_calls": [
{
"id": "call_mTRfGO52jA6oPLLMACKr5HD5",
"code_interpreter": {
"input": "from sympy import symbols, Eq, solve\r\n\r\n# Define the variable\r\nx = symbols('x')\r\n\r\n# Define the equation\r\nequation = Eq(3*x + 11, 14)\r\n\r\n# Solve the equation\r\nsolution = solve(equation, x)\r\nsolution",
"outputs": [{ "logs": "[1]", "type": "logs" }]
},
"type": "code_interpreter"
}
],
"type": "tool_calls"
},
"type": "tool_calls"
}
],
"object": "list",
"has_more": false
}
这个 Run 有 2 个步骤,一个是创建消息,另外一个是代码解释器的执行,其中代码解释器中执行过程中产生的 input 信息并不会显示到最终的结果中,只是 LLM 的一个思考过程,类似 LangChain 的 Agent 里面的 debug 信息。
知识检索
下面我们再使用知识检索工具来演示一下功能,知识检索工具需要上传一个文件,文件通过 API 上传后,OpenAI 后端会自动分割文档、embedding、存储向量,并提供根据用户问题检索文档相关内容的功能,这些都是自动完成的,用户只需要上传文档即可。我们就随便找一个 pdf 文件来做演示,下面是腾讯云搜的产品文档:

下面是知识检索的示例代码:
def knownledge_retrieve():
file = create_file("tengxunyun.pdf")
assistant = create_assistants(
instructions="你是一个客户支持机器人,请用你的专业知识回答客户的问题。",
tools=[{"type": "retrieval"}],
file_ids=[file.id],
)
thread = create_thread(prompt="腾讯云云搜是什么")
run = run_assistant(thread, assistant)
while True:
run = retrieve_run(thread=thread, run=run)
if run.status == "completed":
break
sleep(1)
messages = list_messages(thread)
print(messages.data[0].content[0].text.value)
print(f"messages: {messages.json()}")
run_steps = list_run_steps(thread=thread, run=run)
print(f"run_steps: {run_steps.json()}")
这里我们更换了 Assistant 的 instructions,让它扮演一个客户支持机器人的角色。
Assistant 中使用了检索工具{"type": "retrieval"}。
Assistant 中上传了上面的 pdf 文件。
然后创建一个 Thread,输入我们的问题,问一个文档相关内容的问题。
其他步骤与代码解释器一致。
运行结果如下:
腾讯云云搜是腾讯云的一站式搜索托管服务平台,提供数据处理、检索串识别、搜索结果获取与排序,搜索数据运营等一整套搜索相关服务。
该平台继承了腾讯 SOSO 在搜索引擎领域多年的技术财富,在搜索架构、海量数据存储和计算、智能排序、用户意图识别、搜索质量运营等方面有很深的技术沉淀。
腾讯云云搜负责了腾讯主要产品的搜索业务,包括微信朋友圈、手机 QQ、腾讯视频、QQ 音乐、应用宝、腾讯地图、QQ 空间等。
它提供数据处理、用户检索串智能识别、排序可定制、高级功能、运营支持等功能,以帮助开发者优化搜索服务,并提供丰富的运营数据查询功能,
包括检索量、文档新增量、检索耗时、检索失败率、热榜等。开发者可以通过腾讯云云搜让自己的搜索更具个性化,更匹配应用的需求。【1†source】
可以看到答案确实是从文档中查找而来,内容基本一致,在结尾处还有一个引用【1†source】,这个是
Message 的注释内容,关于 Message 的注释功能这里不过多介绍,后面有机会再写文章说明,关于 Message 注释功能可以看这里[7]。
我们再来看下知识检索的 Run Step 信息:
{
"data": [
{
"type": "message_creation"
// ......
},
{
"object": "thread.run.step",
"status": "completed",
"step_details": {
"tool_calls": [
{
"id": "call_19YklOZJq1HDP8WfmMydcVeq",
"retrieval": {},
"type": "retrieval"
}
],
"type": "tool_calls"
},
"thread_id": "thread_ejr0YGodJ2NmG7dFf1hZMPUL",
"type": "tool_calls"
}
]
}
在检索工具的步骤中,只是返回了工具的类型,但检索的内容并没有放在步骤中,也就是说检索工具并没有产生内部推理过程的信息。
自定义工具
最后我们再来看下自定义工具的示例,我们沿用上一篇文章用到的查询天气工具get_current_weather,我们先定义工具集 tools:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取某个地方当前的天气情况",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名,比如:北京, 上海",
},
},
"required": ["location"],
},
},
}
]
工具集只包含一个工具,定义了工具的方法和参数信息
接着我们使用 Assistant API 来调用自定义工具,示例代码如下:
def get_current_weather(location):
"""Get the current weather in a given location"""
if "北京" in location.lower():
return json.dumps({"location": location, "temperature": "10°"})
elif "上海" in location.lower():
return json.dumps({"location": location, "temperature": "15°"})
else:
return json.dumps({"location": location, "temperature": "20°"})
def function_calling():
assistant = create_assistants(
instructions="你是一个天气机器人,使用提供的工具来回答问题。",
tools=tools,
)
thread = create_thread(prompt="今天北京、上海和成都的天气怎么样?")
available_functions = {
"get_current_weather": get_current_weather,
}
run = run_assistant(thread, assistant)
# 下面是处理 Run 并提交工具的返回结果
# 中间这部分代码在下面演示
messages = list_messages(thread)
print(messages.data[0].content[0].text.value)
print(f"messages: {messages}")
run_steps = list_run_steps(thread=thread, run=run)
print(f"run_steps: {run_steps}")
和之前 2 个示例不同的地方是,tools 参数用的是我们定义的一个工具集 tools
定义了一个字典available_functions来做函数的动态调用
为了演示方便,get_current_weather方法使用一些简单的逻辑来模拟天气查询的功能:
下面是处理 Run 状态并提交工具返回结果的方法,代码如下:
while True:
run = retrieve_run(thread=thread, run=run)
if run.status == "completed":
break
if run.status == "requires_action":
tool_calls = run.required_action.submit_tool_outputs.tool_calls
tool_infos = []
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
location=function_args.get("location"),
)
tool_infos.append(
{"call_id": tool_call.id, "function_response": function_response}
)
submit_tool_outputs(thread=thread, run=run, tool_infos=tool_infos)
sleep(1)
之前在介绍 Run 状态时说过,当 Assistant 中有自定义工具时,状态从 in_process 会进入 requires_action 状态,表示需要提交工具的执行结果
在循环中判断 Run 状态是否为 requires_action,如果是则从 Run 中获取需要执行的工具信息 tool_calls,包括工具名称和参数
在示例中会调用 3 次get_current_weather方法,因此我们新建了一个数组 tool_infos 来保存工具返回的结果
执行完工具后,将工具返回结果保存到
tool_infos 数组中,同时将 tool_calls 中工具 id 也保存到里面,下面在提交工具结果时会用到
拿到工具返回的结果后,我们通过 Run API 来提交这些结果:
def submit_tool_outputs(thread, run, tool_infos):
tool_outputs = []
for tool_info in tool_infos:
tool_outputs.append(
{
"tool_call_id": tool_info["call_id"],
"output": tool_info["function_response"],
}
)
client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=tool_outputs,
)
这里用到了 Run 提交工具结果的 API,其中 tool_outputs 参数是一个数组,数组中每个元素包含 tool_call_id 和 output 两个属性
tool_call_id
的值是 tool_calls 中的 id,output
的值是工具的返回结果
调用了多少个工具就要在 tool_outputs
添加多少个元素
运行结果如下:
今天北京的温度是 10℃,上海的温度是 15℃,成都的温度是 20℃。
改进计划
在 Assistant API 的使用过程中,我们发现现在获取 Run 的状态都是通过轮询的方式,这可能会导致更多的 token 损耗和性能问题,OpenAI 官方介绍在未来会对这一机制进行改进,将其替换成通知模式,另外还有其他改进计划如下:
支持流式输出模式(类似 Websocket 或者 SSE)
支持通过共享对象状态更新通知来代替轮询
支持 DALL-E 3 作为内置的工具
支持用户上传图片文件
总结
以上就是 Assistant API 的基本原理和功能介绍,和 GPTs 相比两者各有优势,GPTs 更适合没有编程经验的用户使用,而 Assistant API 则适合有开发经验的开发人员或团队使用,而且可以使用自定义工具来打造更为强大的功能,但也有一些缺点,就是无法使用 DALL-E 3 画图工具和上传图片(这也意味着无法做图片识别),这些功能相信在未来会逐步支持。
出自:https://mp.weixin.qq.com/s/maEH0Xacxfcyba1pLQao0A