什么是Sora?
Sora是OpenAI公司发布的一款AI视频生成模型。它不仅能够根据文字指令创造出既逼真又充满想象力的场景,而且能生成长达1分钟的超长视频,不管是一镜到底还是分镜头切换模式,都能够保持角色及背景神一般的一致性和稳定性。这标志着我们如何理解和创造虚拟世界的方式即将迎来根本性的变革。
借助于对语言的深刻理解,Sora能够准确地理解用户指令中所表达的需求,把握这些元素在现实世界中的表现形式。也因此,Sora创造出的角色,能够表达丰富的情感!它所制作出的复杂场景,不仅可以包括多个角色,还有特定的动作类型,以及对对象和背景的精确细节描绘。Sora生成视频中人物的瞳孔、睫毛、皮肤纹理,都逼真到看不出一丝破绽,完全没有AI味儿。从此,视频和现实究竟还有什么差别?!
OpenAI在22年发布的ChatGPT改变了语言人工智能格局,24年发布的Sora目测也在改变着视频人工智能格局。
Sora的基础功能跟其他平台对比有什么强大的地方?
在此之前,尽管Runway、Pika、Moonvalley等早已推出了各具特色的视频生成工具,但OpenAI的Sora视频生成模型如同一颗新星,以其逼真、流畅、长达1分钟视频生成长度的特点和非常显著的效果提升,足以秒杀一众弟弟。
下图是Sora跟其他模型在生成视频能力上的一些对比:
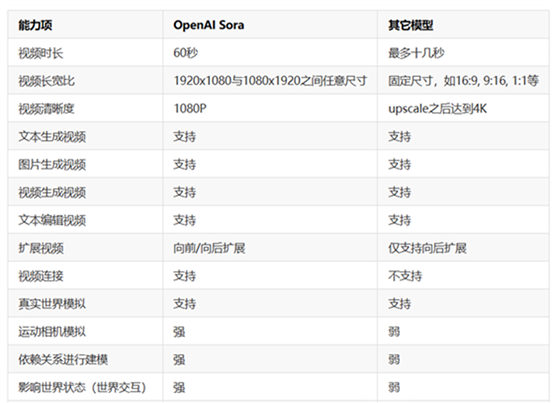
在OpenAI发布Sora之前,业界基于大模型生成视频的主要平台有Pika、Runway、Moonvalley等,但是这些平台视频生成默认都是几秒中,即便通过视频扩展等手段,最多也只能生成十几秒的视频。而OpenAI的Sora可以生成最多1分钟的视频(估计还能更长,很可能OpenAi在时间长度上做了限制,比如会员解锁更长)。并且视频生成的结果非常连贯和清晰。
其中,视频清晰度,OpenAI Sora默认是1080P,而且其它平台大多数默认的清晰度也都是1080P以下,只是在经过upscale等操作之后可以达到更清晰的水平。
根据OpenAI的Sora技术报告,Sora模型可以采样宽屏1920x1080视频、竖屏1080x1920视频以及介于两者之间的所有尺寸视频。这意味着它可以生成更加自由的视频尺寸。而此前的视频平台,如Runway,文本生成视频的方式只能选择16:9, 9:16, 1:1, 4:3,
3:4, 以及 21:9的长宽比。
此外,Sora还能在同一视频中设计出多个镜头,同时保持角色和视觉风格的一致性。要知道,以前的AI视频,都单镜头生成的。而这次OpenAI能在多角度的镜头切换中,就能实现对象的一致性,这不得不说是个奇迹!这种级别的多镜头一致性,是Runway和Pika都完全无法企及的!

不管是在视频的保真度、长度、稳定性、一致性、分辨率、文字理解等方面,Sora都做到了SOTA(当前最优)。
Sora还可以做什么?
Sora也可以通过其他输入进行创作,例如预先存在的图片或视频。这项能力使得Sora能够执行广泛的图像和视频编辑任务——创建完美循环的视频,为静态图像添加动画,向前或向后延长视频的时间等。

向前以及向后扩展视频的能力是Sora另一个与此前视频生成平台有巨大差异的地方。基于已有视频继续向后扩展在Runway
Gen2、Pika等平台都有,但是,OpenAI Sora可以在视频的基础上向前或者向后扩展。例如给定一个视频,OpenAI Sora可以为该视频创造不同的开头,最后都是以该视频结尾,过程非常连续。Sora甚至可以在一个视频上同时向前和向后扩展,以产生一个无限连续的循环视频。
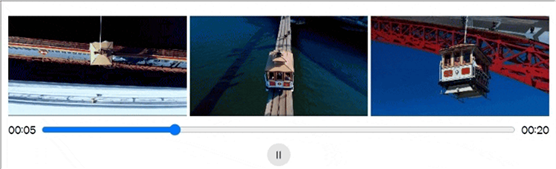
Sora支持视频风格的迁移和编辑,如下面的开车环境就被改到了雨林中。

Sora支持多个视频的连接。给定两个视频,Sora可以将这两个视频揉在一起,生成一个新的毫无违和感的视频。

Sora也能够生成图像,可以生成不同大小的图像——分辨率最高可达2048x2048。是不是有点碾压SDXL的感觉了。Midjourney和StableDiffusion表示躺枪了。
当然Sora作为一个视频模拟器目前还展现出许多问题。例如,它无法准确地模拟许多基本互动的物理效应,比如玻璃破碎、工人搬动凳子时受力情况等。再比如具有前后因果的模拟也并不是每次都正确,如吃食物,不总是产生正确的食物状态变化。还有在长时间样本中发展的不连贯性或物体的自发出现等。但别忘了,这才是Sora第一个版本,我们相信后续版本会不断解决这些问题。Sora目前展现出的能力表明,不断扩展视频模型是一条充满希望的道路,它将引领我们开发出能够模拟物理世界和数字世界,以及其中物体、动物和人类行为的高效模拟器。
想象一下,如果我们能够通过简单的描述就创造出动态的、互动的三维世界,那么教育、娱乐乃至科学研究将迎来怎样的变革?这项技术背后的原理是什么,又将如何影响我们的未来?
我们将花几分钟的时间用最容易理解的文字,为你深度探讨Sora模型生成视频的原理,小白也能看得懂!
大家在阅读下面这段文字之前,建议先把文末的“Sora相关术语”阅读一遍,有助于其原理的理解,相关术语尽量用了最简单的描述并且附带了大量比喻和举例,相信初中生也可以无障碍的理解。
Sora采用Diffusion
Transformer (DiT)架构进行训练。概括来说就是用视觉块编码(visual patch)的方式,把不同格式的视频统一编码成了用transformer架构能够训练的embeding,然后引入类似diffusion的方式在降维和升维的过程中做加噪和去噪,然后把模型做得足够大,大到能够出现涌现能力。
通过大规模参数量的训练,视频模型涌现出许多有趣的新能力。这些能力使得Sora能够模拟现实世界中人类、动物和环境的某些方面。简单来说,在别家做视频模型的时候还是基于“小”模型的思路(基于上一帧预测下一帧,并且用文字或者笔刷遮罩做约束)的时候,OpenAI则是用做“大”模型的思路做视频生成——准备足够大量的视频,用多模态模型给视频做标注,把不同格式的视频编码成统一的视觉块嵌入,然后用足够大的网络架构+足够大的训练批次(batch size)+ 足够强的算力,让模型对足够多的训练集做全局拟合(理解),在模型更好地还原细节的同时让模型出现智能涌现能力——例如在一定程度上理解真实世界的物理影响和因果关系。
最后我们预测一下Sora的出现,短期会对我们造成什么影响。
(1)
内容创作者的新机遇
目前各个平台头部短视频都已经专业化和团队化,Sora降低了高质量视频内容创作的门槛,使得个人创作者也能制作出专业级别的视频,这可能会改变内容创作和分发的格局。同时短视频内容将迎来爆炸性增长。这也利好XR行业,以vision pro为代表的XR产业将再次获得助力——内容匮乏将不再是问题。
(2)
媒体和娱乐行业的变革
Sora将改变电影、电视和在线视频内容的生产方式,提高制作效率,降低成本,同时可能催生新的叙事形式和视觉风格。短视频剧集将更加风靡,可能是下一个风口。
(3)
重塑广告、营销行业
Sora可以用于快速生成定制化的广告视频,这将为品牌提供更灵活、更个性化的营销工具。想象一下未来观看短视频时,视频或者广告能够实时生成,并且同一个视频可能会对不同用户进行不一样的广告引导微调或者风格转换。
(4)
教育和培训行业的革新
Sora可以用于创建教育视频,帮助学生更好地理解复杂概念,或者模拟实验场景,这将极大地丰富教育资源。当然了,学习是反人性的,小朋友不学习该揍还得揍。
(5)
利好AI视频生成行业,但对具体公司是一个大挑战
所有做AI视频生成的公司将面临第一波危机,但是危中有机。因为OpenAI证明了用大模型的思路做视频是可行的,那么他们需要做的只是证明我也可以用大模型做视频。参考ChatGPT火了之后做大语言模型的公司反而更多了而不是更少。
(6)
利空3D建模企业
AI三维生成的公司将面临第二波冲击,由于多目重建技术的存在,视频生成和3D生成的界限是模糊的。所以3D生成可能要重新考虑当前技术路线的合理性和商业叙事逻辑。
(7)
利好显卡赛道
虽然OpenAI没有明说,但是Sora需要的算力不会小,所以显卡公司会迎来新的一波利好,但是不一定利好英伟达。因为现在算力越来越呈现基础设施的特征,而基础设施是各个国家的命脉,即便不考虑禁运,我国不会是唯一一个要求算力自主可控的国家,甚至每个大厂都开始想自己搞显卡或者AI专用算力卡(参考google、特斯拉、openAI、阿里),所以算力领域的竞争者会越来越多。
(8)
法律和伦理挑战
随着AI生成视频的普及,可能会出现关于版权、肖像权和内容真实性的法律问题。未来会不会出现鉴真师呢?
在这个由人工智能技术驱动的新时代浪潮中,我们每个人都是这场变革的见证者和参与者。Sora等AI视频生成模型的出现,不仅为我们提供了前所未有的创作工具,也为我们打开了新的可能性。作为这个时代的一员,我们应当积极拥抱这些变化,不断提升自己的技能和知识,以便更好地利用这些工具来实现个人价值和职业发展。
我们不应该满足于仅仅成为历史的旁观者,被时代的车轮所碾压。相反,我们应该主动出击,成为推动时代前进的力量。这意味着我们需要不断学习新的技术,理解AI的工作原理,掌握与AI合作的方法,以及如何在AI的帮助下创造新的价值。我们应该勇于尝试,敢于创新,不断挑战自己的舒适区,以确保在这场技术革命中,我们不仅能够跟上时代的步伐,还能够引领潮流。
通过不断自我提升,我们可以在AI的帮助下,创造出更加丰富、更加个性化的内容,无论是在艺术创作、教育、娱乐还是商业领域。我们的目标是成为那些能够驾驭技术、引领创新的先锋,而不是被技术所淘汰的落后者。让我们携手并进,共同书写这个时代的新篇章。
OpenAI关于Sora的研究报告
https://openai.com/research/video-generation-models-as-world-simulators
加我微信讨论Ai
