这篇文章为流行的GPU的性能提供了一个简明的参考,包括NVIDIA和华为海思的主流型号,水平有限,译文整理,供参考学习。
·
1 引言
§ NVIDIA GPU 的命名规则
·
2 L2/T4/A10/A10G/V100对比
·
3
A100/A800/H100/H800/Ascend 910B的比较
§ 3.1 关于GPU间带宽的注意事项:HCCS与NVLINK
·
4
H20/L20/Ascend 910B的比较
·
5 关于美国对华“芯片出口管制”的说明
§ 5.1 出口管制 2022.10
§ 5.2 出口管制 2023.10
1 引言:NVIDIA GPU 的命名规则
GPU 型号名称中的第一个字母表示其 GPU 架构,包括:T代表 图灵Turing;A 代表 安培Ampere;V 代表 伏特Volta;H 代表 Hopper 是202203推出的;L 代表 Ada Lovelace;
2 比较L2/T4/A10/A10G/V100
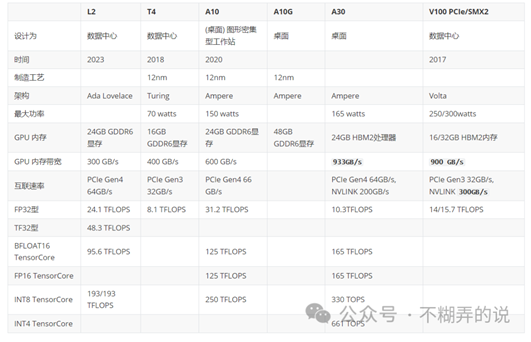
其中:TFLOPS是每秒执行1万亿次浮点运算次数,TOPS每秒执行1万亿次运算次数。
o FP代表浮点运算数据格式,包括双精度(FP64)、单精度(FP32)、半精度(FP16)以及FP8等,INT代表整数格式,包括INT8、INT4等。后面的数字位数越高,意味着精度越高,能够支持的运算复杂程度就越高,适配的应用场景也就越广;
o FP32也叫做 float32,两种叫法是完全一样的,全称是Single-precision floating-point(单精度浮点数),在IEEE 754标准中是叫做binary32,用32位二进制来表示的浮点数,数据溢出动态范围(1.4E-45 ~
3.40E38);
o BF16也叫做BFLOAT16 (这是最常叫法),全称brain floating point,用16位二进制来表示的,Google Brain开发,数据溢出动态范围(9.2E−41~3.38E38);
o FP16也叫做 float16,全称是Half-precision
floating-point(半精度浮点数),在IEEE
754标准中是叫做binary16,用16位二进制来表示的浮点数,数据溢出动态范围(5.96E−8~
65504)。
详细参数参考官网:
1.
T4:https://www.nvidia.com/en-us/data-center/tesla-t4/
2.
A10:https://www.nvidia.com/en-us/data-center/products/a10-gpu/
3.
A30:https://www.nvidia.com/en-us/data-center/products/a30-gpu/
4.
V100-PCIe/V100-SXM2/V100S-PCIe:https://www.nvidia.com/en-us/data-center/v100/
3 比较A100/A800/H100/H800/910B
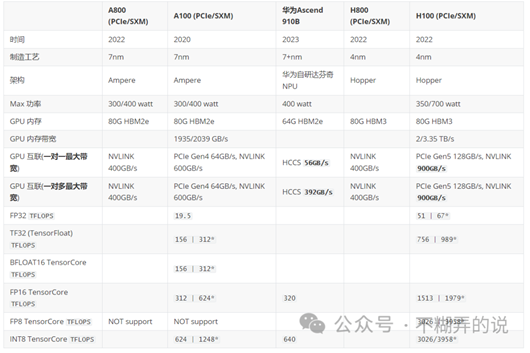
其中:H100 vs. A100 简而言之: 3 倍的性能,2 倍的价格.
详细参数参考官网:
1.
A100:https://www.nvidia.com/en-us/data-center/a100
2.
H100:https://www.nvidia.com/en-us/data-center/h100/
3.
Huawei
Ascend-910B (404)见HUAWEIAscend)310:https://www.hisilicon.com/cn/products/Ascend/Ascend-310
4.
910论文: Ascend: a Scalable
and Unified Architecture for Ubiquitous Deep Neural Network Computing, HPCA,
2021:https://ieeexplore.ieee.org/abstract/document/9407221
3.1
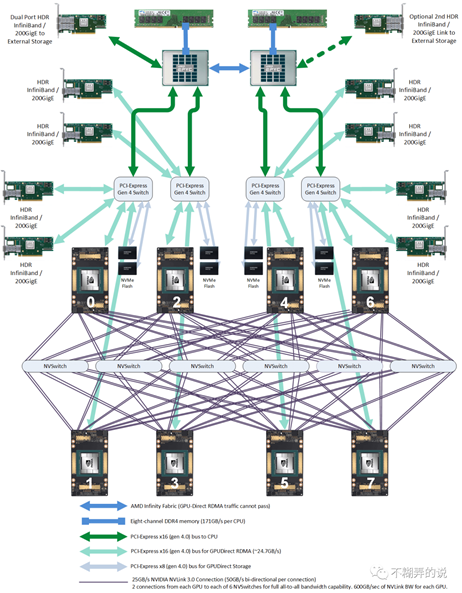
GPU间带宽注意: HCCS vs. NVLINK
对于 8 卡 A800 和 910B 模块:910B HCCS 的总带宽为
, 这似乎与 A800 NVLink 相当。但是,有一些差异,分别是392GB/s和400GB/s。NVIDIA NVLink:全网状拓扑如下,因此(双向)GPU 到 GPU 的最大带宽为 400GB/s(请注意,下面的模块为 600GB/s,共享类似的全网状拓扑);8*A100``8*A800
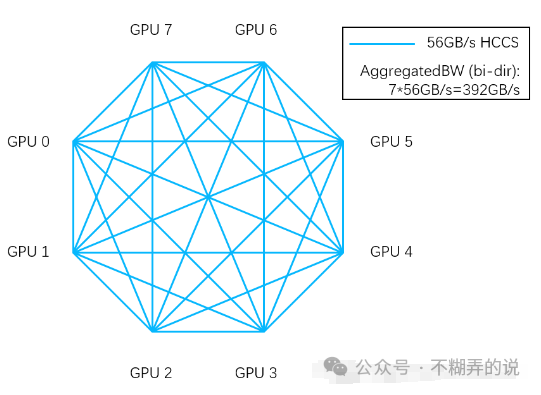
华为 HCCS:点对点拓扑(没有 NVSwitch 芯片之类的东西),因此(双向)GPU 到GPU的最大带宽为 56GB/s;
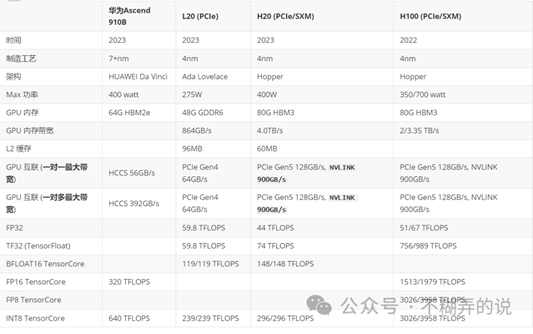
4 比较 H20/L20/华为910B
5 关于美国对华“芯片出口管制”说明
5.1 出口管制 2022.10
根据美国联邦政府的政府公报额外出口管制清单Implementation
of Additional Export Controls: Certain Advanced Computing and Semiconductor
Manufacturing Items; Supercomputer and Semiconductor End Use; Entity List
Modification,对于可以运往中国市场的芯片,必须满足以下条件:
1.
聚合双向传输速率必须< 600 GB/s;
2.
聚合处理性能必须< 4800 位 TOPS (TFLOPS),即 相当于:
o < 300 TFLOPS FP16
o < 150 TFLOPS FP32
A100 和 H100 受到这些限制,这就是为什么有定制版本的原因:A800 和 H800。
·
参考:https://www.federalregister.gov/documents/2022/10/13/2022-21658/implementation-of-additional-export-controls-certain-advanced-computing-and-semiconductor
5.2 出口管制更新 2023.10
根据Implementation of Additional
Export Controls: Certain Advanced Computing Items; Supercomputer and
Semiconductor End Use; Updates and Corrections, 除了2022.10 Export Controls内容外,更新和更正还具有 符合下列条件之一的,也禁止在中国市场销售:
1.
总处理性能在2400~4800位TOPS,性能密度在1.6~5.92; 2400 位 TOPS 相当于:
·
150
TFLOPS FP16
·
75
TFLOPS FP32
2.
总处理性能 >= 1600 位 TOPS 和 3.2~5.92 的性能密度;
这些限制涵盖大多数高性能 GPU,包括旧型号
A800。但是,应该注意的是,也有低计算能力的空间 但高传输速率的型号,例如传闻中的“148TFLOPS
+ 900GB/s NVLink“ H20 图形处理器。
参考:https://www.federalregister.gov/documents/2023/10/25/2023-23055/implementation
出自:https://mp.weixin.qq.com/s/AaNoJDSUTSRpvv7lO_iExQ