Playground团队刚刚发布了新的文生图模型Playground v2,它是基于SDXL的架构从零训练的模型,但是根据用户评价,它在生成效果上比SDXL强2.5倍。

Playground v2目前已经在huggingface开源,这次开源除了包括1024x1024的模型,还包含中间训练的256x256和512x512的模型。
1024x1024:playgroundai/playground-v2-1024px-aesthetic
· Hugging Face
512x512:playgroundai/playground-v2-512px-base · Hugging Face
256x256:playgroundai/playground-v2-256px-base · Hugging Face
Playground v2和SDXL的架构和模型参数都是相同的,都是采用两个text encoder:OpenCLIP-ViT/G和CLIP-ViT/L。你可以直接使用diffusers库来使用:
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"playgroundai/playground-v2-1024px-aesthetic",
torch_dtype=torch.float16,
use_safetensors=True,
add_watermarker=False,
variant="fp16"
)
pipe.to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt=prompt, guidance_scale=3.0).images[0]
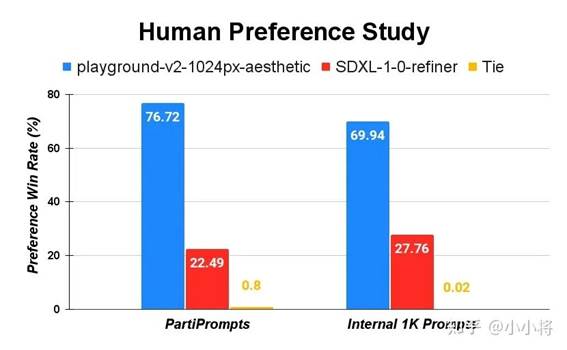
根据在包含2600+个用户的prompts上的人工评测,相比SDXL,Playground v2要优2.5倍:
为了进一步评价模型的生成图像的质量,Playground团队还构建了新的评测集MJHQ-30K。它是从Midjourney上收集的30000个高质量数据集,共包含10个常见的类别,每个类别包含3000个样本。Playground v2在MJHQ-30K上的FID明显优于SDXL:
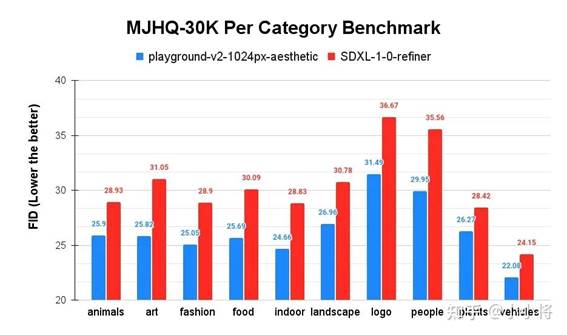

这个FID结果看起来和人工评测一致,看起来比采用MSCOCO14来计算FID更靠谱一些。
目前你可以在Playground V2 - a Hugging Face Space
by playgroundai或者https://playgroundai.com/体验这个模型:
由于Playground v2和SDXL架构和参数都一样,所以现有的工具WebUI和ComfyUI都兼容这个模型。


出自:https://mp.weixin.qq.com/s/SqgsuIMz0kldP5J5ytcgXw