阿里动作太过频繁,就我的脑海回忆,推出了挺多东西的,效果还都不错,今天盘点下都有哪些。
长文短说
写完这篇文章我才发现,阿里已经搞了这么多项目,难怪在我的脑海中,阿里最近的动作频繁,一个接一个的推出。
·
通义千问大模型,大家自然是知道的。
·
AnyText 我之前也写文章介绍过了,专门针对中文,在生成的图片中能够很好的嵌入中文,而且还有强大的文字编辑功能。
·
Animate Anyone,英文名字大家可能不熟悉,但是说通义千问的全民舞王,兵马俑跳科目三的视频等等,之前就火了一段,大家应该就熟悉了。一个静态图片转视频的项目。
·
还有
Replace Anything,也是阿里的智能计算研究院推出的一款图像内容替换框架,比如更换人物发型、人物的服装以及背景等。
·
还有
Outfit Anyone 也是阿里推出的一个服装虚拟试穿的开源项目,不需要亲自穿,只需要一张模特图片,一张衣服平面图,就可以达到始试穿的效果。这个项目一旦落地,在电商、设计、甚至是购物都很方便,普通人在家里就可以体验新颖的衣物,随时随地,设计师也可以随时随地的看自己设计的衣服,搭配在不同人身上的效果,来做修改。还有电商模特的成本将会大大降低。
·
FaceChain 是阿里达摩院推出的一个开源的人物写真和个人数字形象的 AI 生成框架(类似于免费开源版的妙鸭相机),用户仅需要提供最少一张照片即可生成独属于自己的个人形象数字替身。
·
I2VGen-XL, 阿里推出的图像到视频生成模型,也就是图生成视频又新增了一个 AI 工具,之前常用的效果好的有 Gen-2、pika、pixverse 这些。
·
Animate 3D Motion, 阿里推出的 AI 角色动画项目,可替换视频人物为 3D。上传一段视频,AI 自动识别视频中的运动主体人物,并一键替换成有趣的 3D 角色模型,生成与众不同的 AI 视频。
上面是阿里最近推出的一些项目,动作不断,太过频繁,事出反正必有妖,可以关注下落地场景。
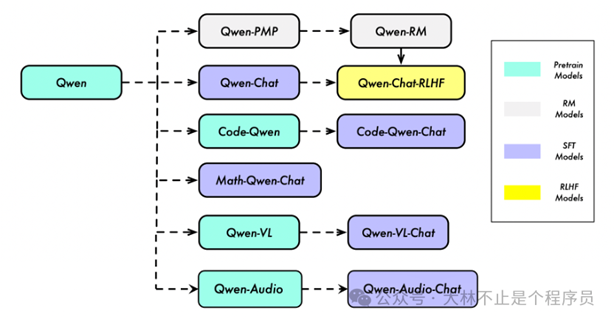
通义千问大模型
千问大模型(Qwen)官方介绍说法是:不仅仅是一个语言模型,而是一个致力于实现通用人工智能(AGI)的项目,目前包含了大型语言模型(LLM)和大型多模态模型(LMM)。
而且是开源的。
通义千问介绍文档 :https://tongyi.aliyun.com/qianwen/blog/tsq0i7fyr9is4oeo
·
论文链接 :
https://arxiv.org/abs/2309.16609
·
·
代码链接 :
https://github.com/QwenLM
·
·
Hugging Face:
https://huggingface.co/Qwen
·
·
魔塔社区 :
https://modelscope.cn/organization/qwen
·
Discord:
https://discord.gg/z3GAxXZ9C
·
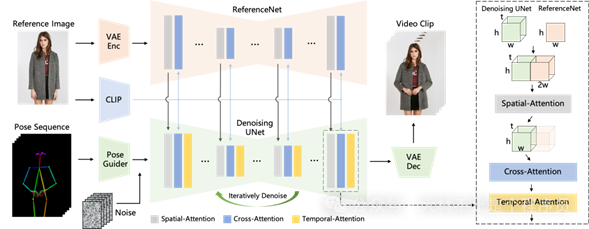
Animate Anyone
Animate Anyone 是阿里开源的图像到视频角色动画合成的框架,人话来说就是图生成视频,之前看到的很多兵马俑跳舞的视频就是这个做的。
而且目前已经集成在通义千问 APP 里面-全民舞王

大林AIP

·
代码链接 :https://github.com/HumanAIGC/AnimateAnyone
·
·
论文链接 :
https://arxiv.org/pdf/2311.17117.pdf
·
·
介绍地址 :
https://humanaigc.github.io/animate-anyone/
·
·
体验地址 :通义千问
APP 里面-全民舞王
·
·
Hugging Face 社区 Demo:
https://huggingface.co/spaces/xunsong/Moore-AnimateAnyone
·
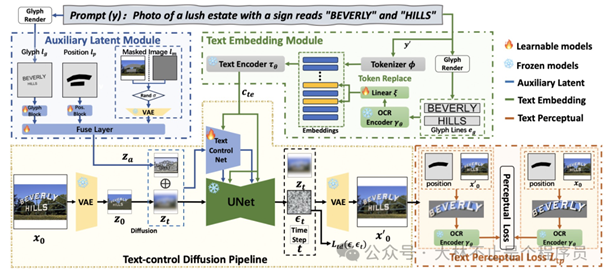
AnyText
之前专门写了一篇文档介绍 AnyText,效果很棒,可以看下。
体验完阿里推出的AnyText,效果确实不错,如果落地,AI加持下的电商会怎么样?
AnyText 针对中文的情况,做的一个多语言文字生成,还有蚊子编辑功能。

·
代码链接 https://github.com/tyxsspa/AnyText
·
·
论文链接 https://arxiv.org/abs/2311.03054
·
·
魔塔链接 https://modelscope.cn/studios/damo/studio_anytext
Replace Anything
Replace Anything 是阿里巴巴智能计算研究院推出的一款开源 AI
图像内容替换框架,比如更换人物发型、人物的服装以及背景等。
这个一出,阿里的电商又牛了一大步
服装更换

证件照、全家福背景替换

替换人物

背景替换

·
项目介绍地址https://aigcdesigngroup.github.io/replace-anything/
·
·
代码地址https://github.com/AIGCDesignGroup/ReplaceAnything
·
·
HF 体验地址https://huggingface.co/spaces/modelscope/ReplaceAnything
·
·
魔塔社区体验地址
·
https://www.modelscope.cn/studios/damo/ReplaceAnything/summary
⭐️
step1:在“输入图像”中上传 or 选择 Example 里面的一张图片
⭐️ step2:通过点击鼠标选择图像中希望保留的物体(或者上传一张黑白 Mask 图片,白色对应期望保留的区域)
⭐️ step3:输入对应的参数,例如 prompt 等,点击
Run 进行生成
⭐️ step4 (可选):此外支持换背景操作,上传目标风格背景,执行完 step3 后点击 Run 进行生成
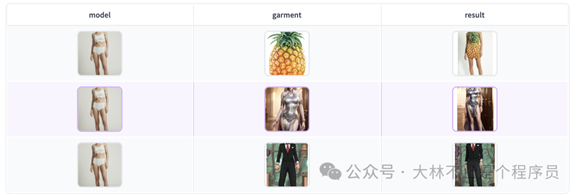
Outfit Anyone
阿里开源的一键换衣虚拟试穿项目。
Outfit Anyone 是由阿里巴巴智能计算研究院推出的一个服装虚拟试穿的开源项目,不需要亲自穿,只需要一张模特图片,一张衣服平面图,就可以达到始试穿的效果。
这个项目一旦落地,在电商、设计、甚至是购物都很方便,普通人在家里就可以体验新颖的衣物,随时随地,设计师也可以随时随地的看自己设计的衣服,搭配在不同人身上的效果,来做修改。还有电商模特的成本将会大大降低。




·
项目地址https://humanaigc.github.io/outfit-anyone/
·
·
代码https://github.com/HumanAIGC/OutfitAnyone
·
·
魔塔社区体验https://modelscope.cn/studios/DAMOXR/OutfitAnyone/summary
·
·
HF 体验https://huggingface.co/spaces/HumanAIGC/OutfitAnyone
·
FaceChain
阿里推出的人物写真和个人形象生成框架
FaceChain 是阿里巴巴达摩院推出的一个开源的人物写真和个人数字形象的 AI 生成框架(类似于免费开源版的妙鸭相机),用户仅需要提供最少一张照片即可生成独属于自己的个人形象数字替身。
这个框架利用了 Stable Difusion 模型的文生图功能并结合人像风格化 LORA 模型训练及人脸相关感知理解模型,将输入的图片进行训练后推理输出生成为个人写真图像。

·
代码https://github.com/modelscope/facechain/tree/main
·
·
论文
·
https://arxiv.org/abs/2308.14256
·
魔塔社区
·
https://www.modelscope.cn/brand/view/FaceChain
·
HF 地址
·
https://huggingface.co/spaces/modelscope/FaceChain
I2VGen-XL
阿里推出的图像到视频生成模型
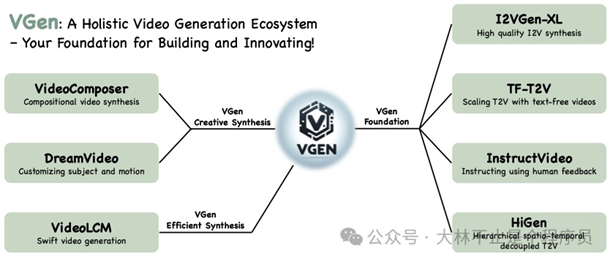
VGen 是阿里巴巴达摩院推出的一款开源的图像到视频的生成模型,也就是图生成视频又新增了一个
AI 工具,之前常用的效果好的有 Gen-2、pika、pixverse 这些。
VGen
可以根据用户输入的静态图像和文本生成目标接近、语义相同的视频,生成的视频具高清(1280 * 720)、宽屏(16:9)、时序连贯、质感好等特点。
可以根据输入的文本、图像、所需的运动、所需的主题,甚至提供的反馈信号生成高质量的视频。它还提供了各种常用的视频生成工具,例如可视化、采样、训练、推理、使用图像和视频的联合训练、加速等。
Step
1: 选择合适的图片进行上传 (建议图片比例为 1:1),然后点击“生成视频”,得到满意的视频后进行下一步。
Step
2: 补充对视频内容的英文文本描述,然后点击“生成高分辨率视频”,视频生成大致需要 2 分钟。
·
项目地址https://i2vgen-xl.github.io/
·
·
代码链接https://github.com/ali-vilab/i2vgen-xl
·
·
魔塔社区 :https://www.modelscope.cn/studios/damo/I2VGen-XL-Demo/summary
·
·
HF 地址:https://huggingface.co/spaces/modelscope/I2VGen-XL
·
Animate 3D Motion
阿里推出的
AI 角色动画项目,可替换视频人物为 3D
大林AIP
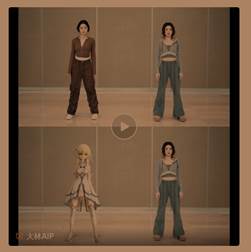
上传一段视频,AI 自动识别视频中的运动主体人物,并一键替换成有趣的 3D 角色模型,生成与众不同的 AI 视频。
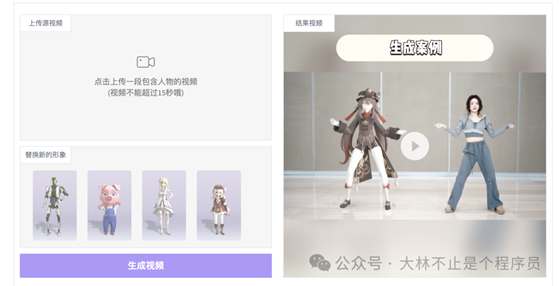
第一步:上传一个包含人物的视频(请保证人物完整,视频时长不超过 15 秒);
第二步:选择视频中要替换的人物(自动选择);
第三步:选择要替换的虚拟角色模型并点击生成,等待 10 分钟即可生成结果。
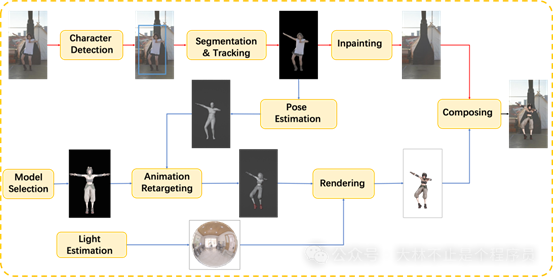
提出了一个用 3D 头像替换视频中角色的框架。由两部分组成:1)用于提取修复背景视频序列的视频处理管道,2)用于生成头像视频序列的姿势估计和渲染管道。通过并行两条管道并使用高性能光线追踪渲染器
TIDE,整个过程可以在几分钟内完成。
·
项目地址https://aigc3d.github.io/motionshop/
·
魔塔社区https://www.modelscope.cn/studios/Damo_XR_Lab/motionshop/summary
AIGC
知识库:https://szqxz4m7fs.feishu.cn/wiki/wikcnMJ5qdVdOJ03XsBZFuXIRkf
出自:https://mp.weixin.qq.com/s/IczheUjcj32Eh1zjJD9JDg