眼看快过年了!
通义千问Qwen又来了一波超吊的更新!

Qwen这波年终大放送相当给力,将所有模型更新到了1.5版本,一次性放出6个尺寸,几十个模型!
各项指标也是相当牛逼。
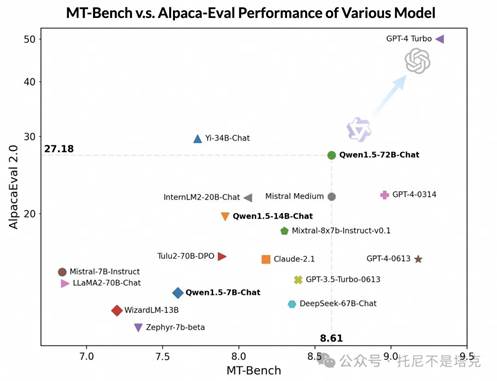
虽然离GPT-4 Turbo还有一些距离,但是一个开源模型都这么能打,还要什么飞机。
而且配套齐全。
一堆周边等你来玩。
无论是本地部署,服务器API,微调,全部给你整的明明白白。
突然发现,现在做程序员挺无助的!
有些需求你刚开始想,人家就已经做好了。
比如,我之前搞了一个叫Jarvis的一键运行包,想着可以集成各种最新的大模型。
我开了个头,就划水了。
现在一看,已经有很多这样的软件了。
比如这叫LM Studio的软件。
只要只支持GGUF的大语言模型,都可以一键安装,一键运行,立马开始对话。简直就是...
"GGUF"代表GPT-Generated Unified Format,是一种由Georgi Gerganov定义发布的大模型文件格式。Georgi Gerganov是著名开源项目llama.cpp的创始人。
GGUF是一种二进制格式文件的规范,旨在使原始的大模型预训练结果经过转换后能够更快地被载入使用,并且消耗更低的资源。GGUF通过采用紧凑的二进制编码格式、优化的数据结构、内存映射等多种技术来保存大模型预训练结果,从而提高效率。
简而言之,GGUF可以理解为一种高效处理和使用大型语言模型的文件格式定义,它通过格式转换优化模型的加载速度和运行效率。
软件目前完全免费,已经支持苹果的Mac M系列,微软的Windows系统,Linux系统。
除了可以直接对话之外,还支持API,而且硬件要求极低,真是要啥有啥。
本地玩转大模型绝对不是梦了。
今天,就拿Qwen来演示下!
首先当然是获取软件并安装。
安装简单到爆,只要双击EXE就可以了,不用任何配置。
打开后,可以看到一个搜索框,只要输入大模型的名字,或者huggingface的项目地址。就可以找到模型了。
由于Qwen已经和他们那个啥了。所以无需搜索,在软件上可以直接看到。
点一下 Download,就开始下载模型了。
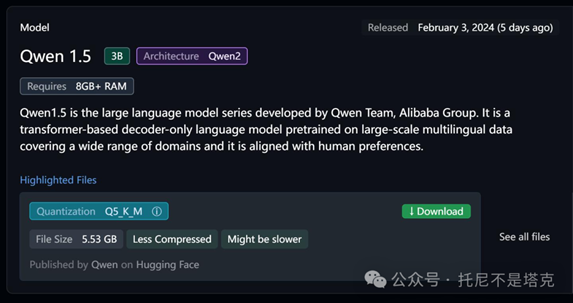
默认保存路径在C盘,如果要修改路径可以看下图。
下载过程中,软件底部会有进度条。
下载完成之后,点击顶部中间的下拉菜单,选择模型即可。
在User处输入问题,回车,就可以进行对话了!
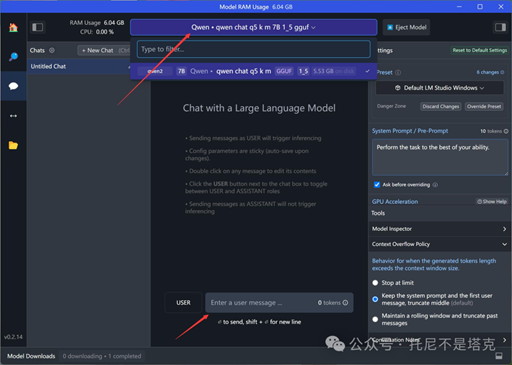
一键安装,一键加载,一键聊天。
相当丝滑!!!
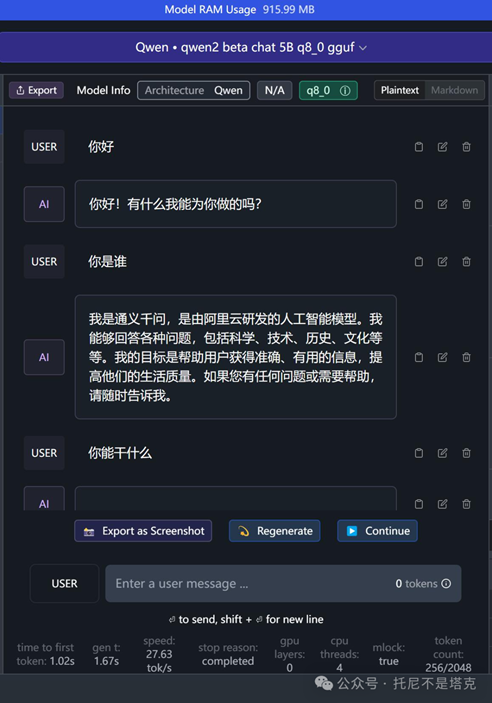
从截图中可以看到,我们已经成功和通义千问离线模型对上话了。
从图上数据可以看到,每秒能到达27tok,基本可以流畅对话了。
我本来想当然认为这是用了GPU。
实际上...看了一眼任务管理器,好像并没有用到。
有的话用得也不多。
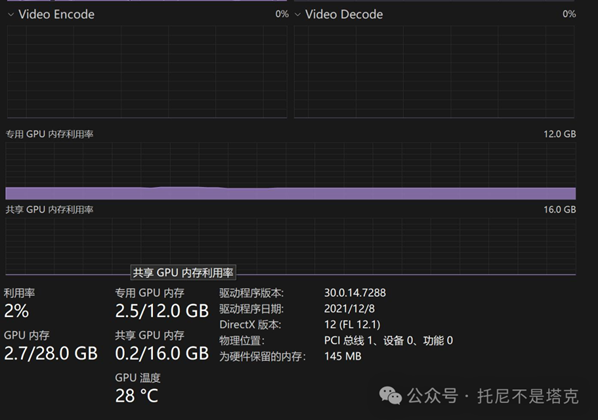
这个东西就有点牛逼了。默认加载的是70亿参数的模型哦!!!
如果你觉得这个对话速度还是有点慢,那么我们来体验一下Qwen最小的大模型。
直接在搜索框里输入Qwen1.5。
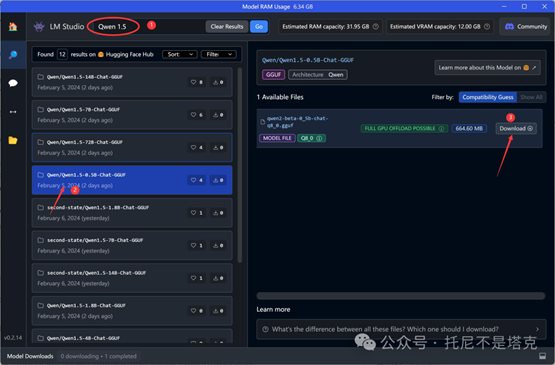
找到0.5B的模型。
从详细信息中可以看到,这个模型只有664MB。
我们以前玩的大模型动不动就是5G起步,对比之下,这个大小实在是太安逸了。
另外,上面说过,这个软件不单单支持Qwen,还支持很多其他大语言模型。
应该是llama.cpp支持的模型都支持。
看着llama.cpp出现,看着基于它的应用出现。
技术发展真的是日新月异,我们都是这个时代的见证人。
由于网络原因,有些人可能无法获取软件或者模型。
我已经把模型放在网盘里了。
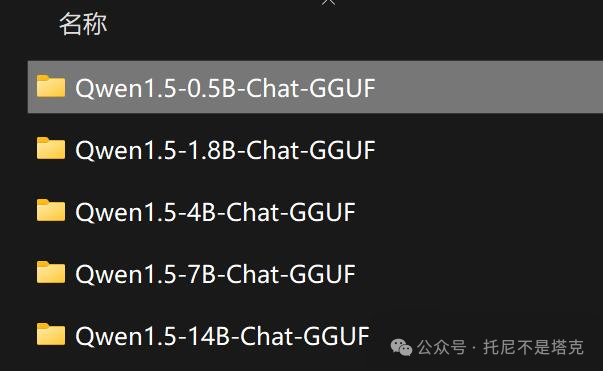
下载Models文件夹,然后通过软件设置模型路径,指向这个文件夹就可以了。
除了72B之外(一般设备也跑不了),另外5类模型全部给你们准备好了。
发送lms即可获取软件和模型!
出自:https://mp.weixin.qq.com/s/Od5j1Vorhho_MqsIu8XH0Q